Differentiële private clusteringmodellen
Dataprivacy en anonimisering in Python

Rebeca Gonzalez
Data engineer
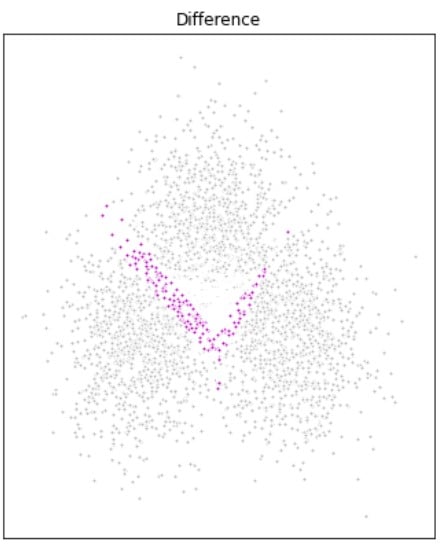
Modellen vergelijken
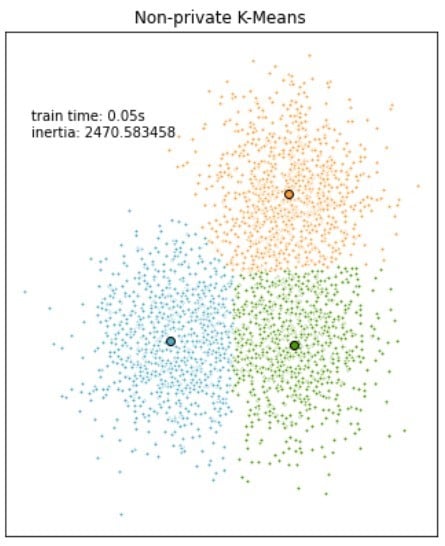
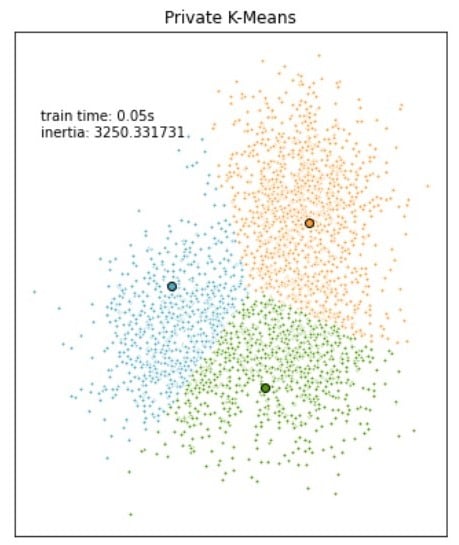
Modellen vergelijken
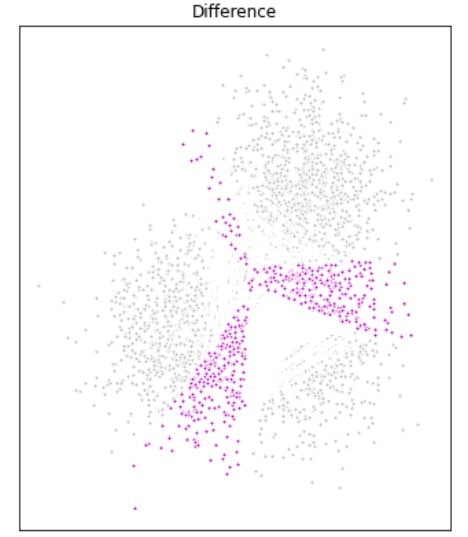
DP-clusteringmodellen verbeteren
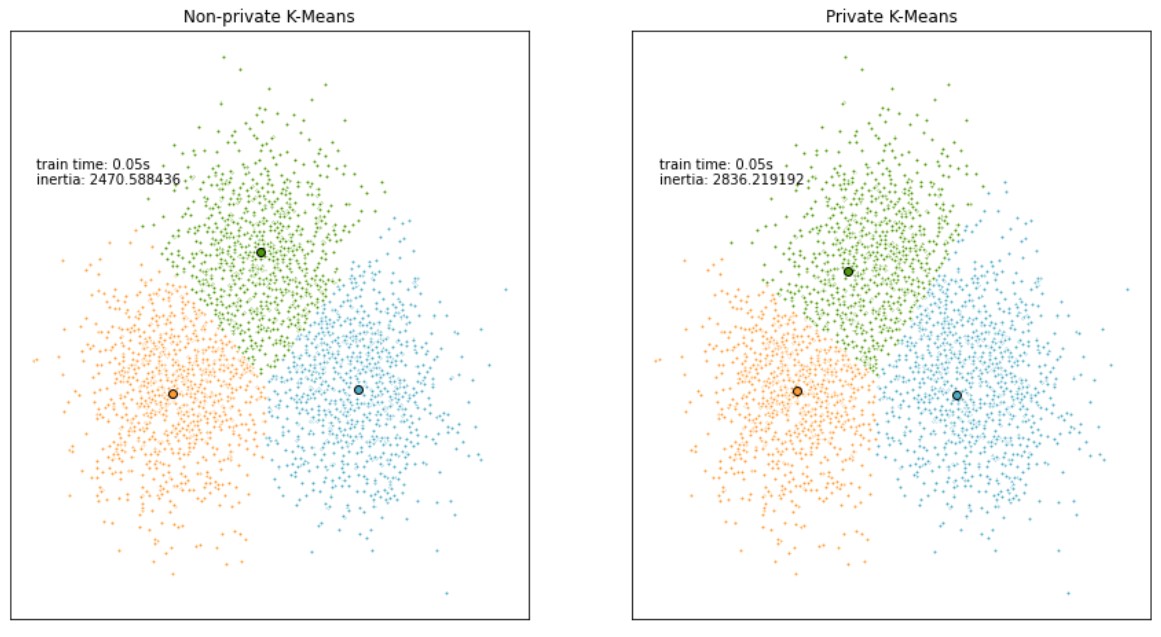
DP-clusteringmodellen verbeteren
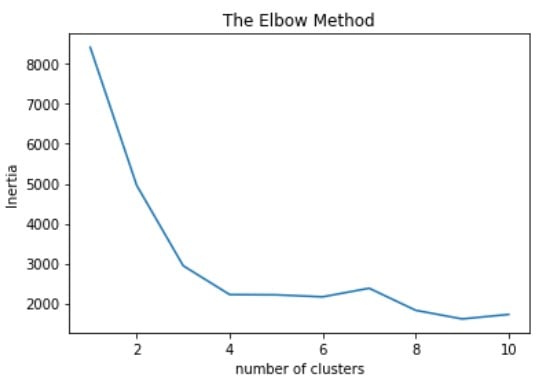
Elbow-methode
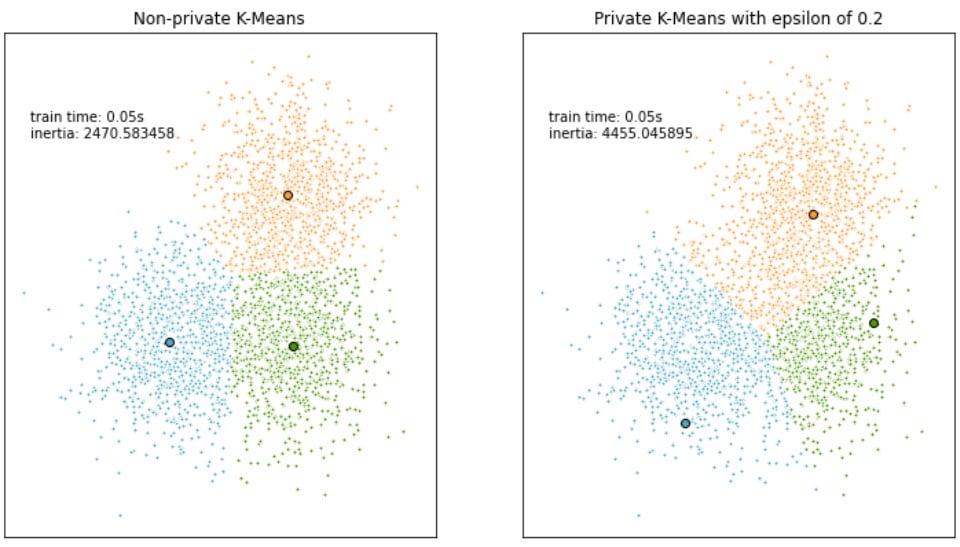
Epsilon
Dataprivacy en anonimisering in Python
Rebeca Gonzalez
Data engineer

