Datamasking en datageneratie met Faker
Dataprivacy en anonimisering in Python

Rebeca Gonzalez
Data engineer
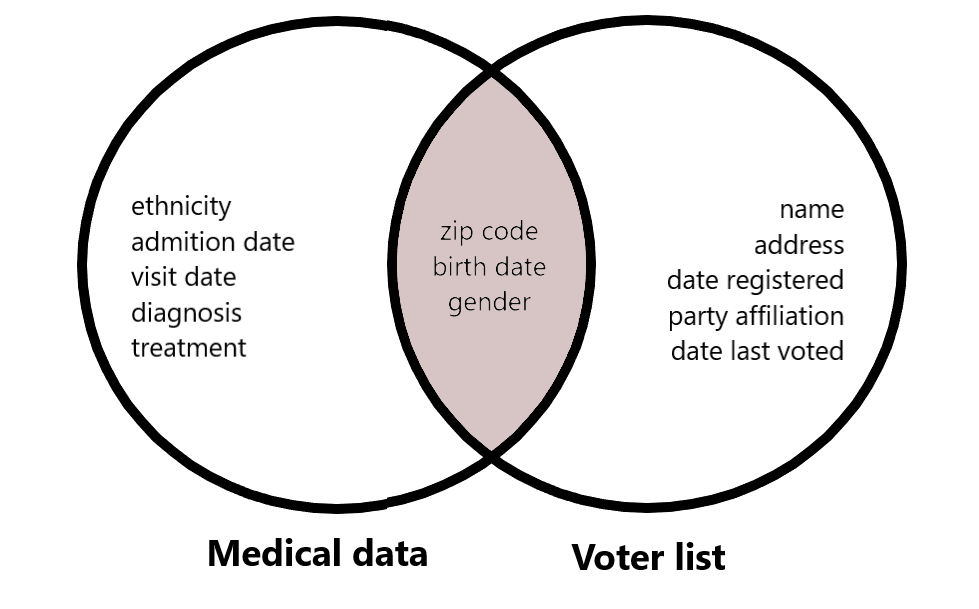
Quasi-identificatoren
Niet-gevoelige, persoonsidentificeerbare info kan ook quasi-identificatoren zijn.

1 Foto van Angela Merkel via Wikimedia Commons
Quasi-identificatoren

Quasi-identificatoren en heridentificatie-aanvallen
Meer anonimiseringstechnieken
Anonimiseringstechnieken voor quasi-identificatoren om datarisico te verlagen.
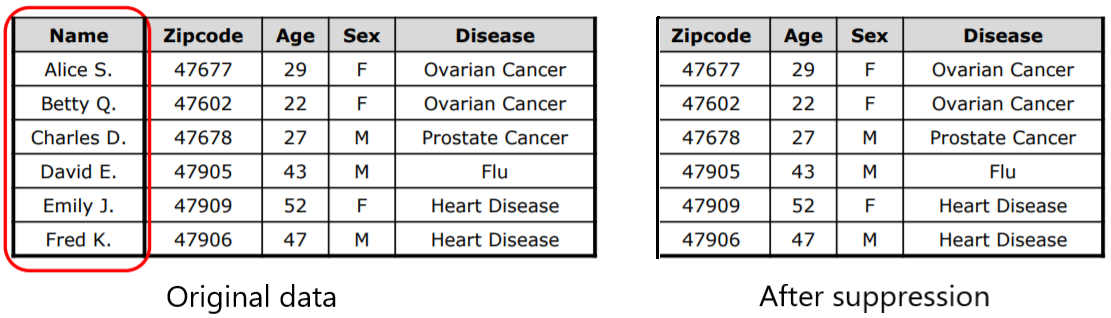
Gedeeltelijke datamasking
Synthetische data genereren

- Gevoelige info vervangen door nieuw, op het origineel lijkend, gegenereerd data.

