PCA voor anonimisering
Dataprivacy en anonimisering in Python

Rebeca Gonzalez
Data engineer
Principal component analysis (PCA)
$$ $$ Methode voor dimensionaliteitsreductie, vaak gebruikt om grote datasets te verkleinen.
Datamasking met PCA
PCA maakt nieuwe "hoofcomponenten" via lineaire transformaties van de originele features.
In een dataset met bieren construeert PCA nieuwe features. Bijvoorbeeld:
$$ 2\times AlcoholicVolume - BitternessLevel$$
Datamasking met PCA
Nieuwe projecties van de data
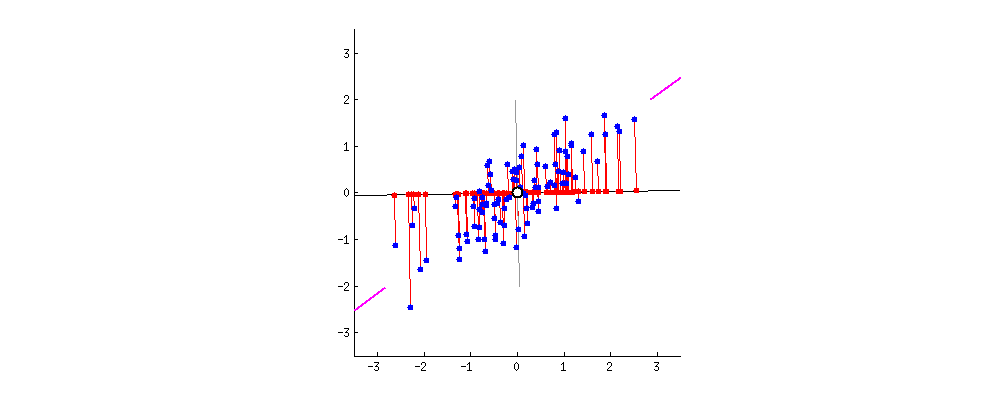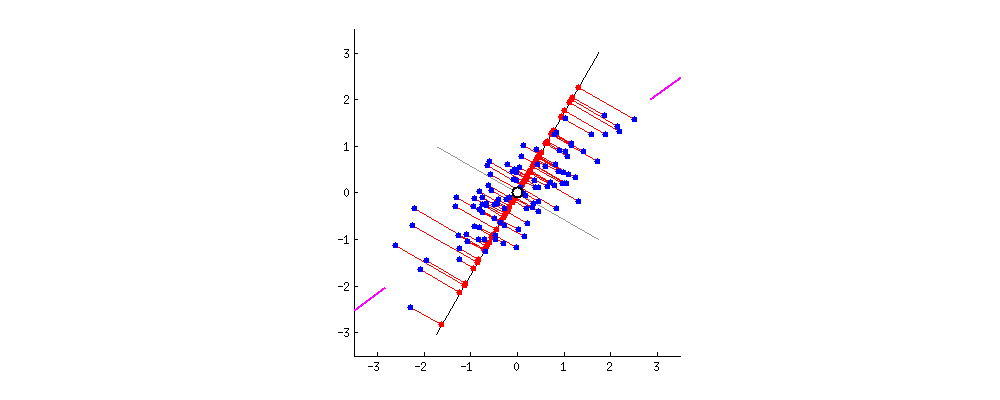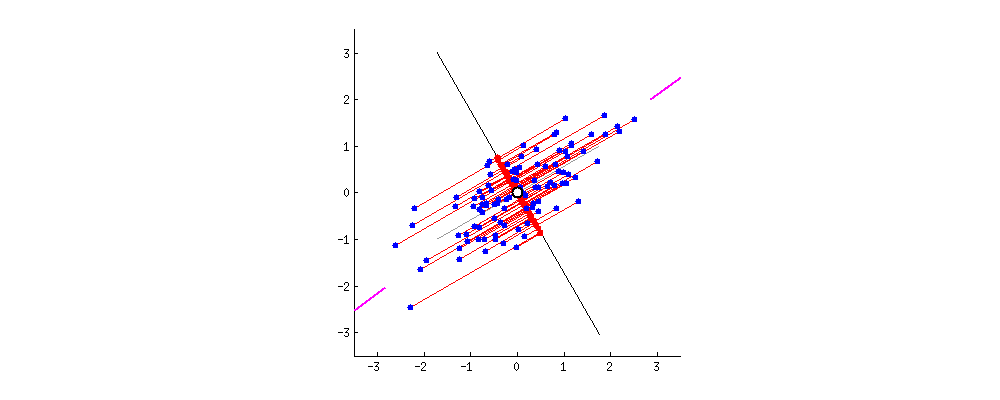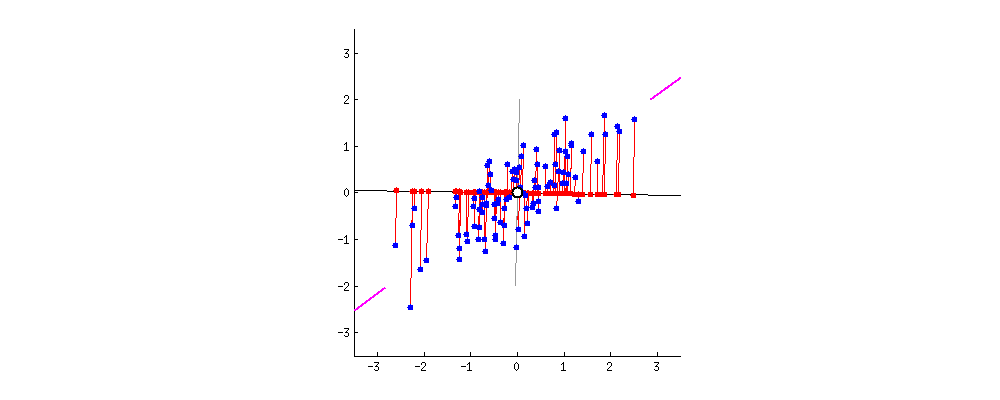
Datamasking met PCA
PCA zonder dimensionaliteitsreductie
$$
- Het is alleen een rotatie van de oorspronkelijke ruimte.
- Afstanden blijven behouden.
- Voordeel voor voorspellende taken en algoritmen.
Datamasking met PCA
- Als die waarden zonder uitleg worden gedeeld, kunnen algoritmen er nog steeds op trainen en nauwkeurig voorspellen.
- Tegenstanders weten niet hoe ze die gemaskeerde waarden moeten interpreteren.
Datamasking met PCA
# Verken de dataset
heart_df.head()
age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal target
0 63 1 3 145 233 1 0 150 0 2.3 0 0 1 1
1 37 1 2 130 250 0 1 187 0 3.5 0 0 2 1
2 41 0 1 130 204 0 0 172 0 1.4 2 0 2 1
3 56 1 1 120 236 0 1 178 0 0.8 2 0 2 1
4 57 0 0 120 354 0 1 163 1 0.6 2 0 2 1
Datamasking met PCA en Scikit-learn
# Verkrijg de data zonder de target-kolom x_data = df.drop(['target'], axis = 1)# Target-kolom als array met waarden y = df.target.values
Datamasking met PCA en Scikit-learn
# Importeer PCA uit Scikit-learn from sklearn.decomposition import PCA# Initialiseer PCA met evenveel componenten als kolommen pca = PCA(n_components=len(x_data.columns))# Pas PCA toe op de data x_data_pca = pca.fit_transform(x_data)
Datamasking met PCA en Scikit-learn
# Bekijk de data
x_data_pca
array([[-1.22673448e+01, 2.87383781e+00, 1.49698788e+01, ...,
7.31102828e-01, -2.90393586e-01, 5.12575925e-01],
[ 2.69013712e+00, -3.98713736e+01, 8.77882303e-01, ...,
4.04206943e-01, -4.25920179e-01, -1.48124511e-01],
[-4.29502141e+01, -2.36368199e+01, 1.75944589e+00, ...,
-9.15397287e-01, 2.17828257e-01, 7.97593843e-02],
...,
Datamasking met PCA en Scikit-learn
# Maak een DataFrame van de PCA-uitvoer df_x_data_pca = pd.DataFrame(x_data_pca)# Controleer de vorm van de dataset df_x_data_pca.shape
(1213, 13)
Databruikbaarheid na PCA-masking
- Voer classificatie uit met logistieke regressie en kijk naar nauwkeurigheidsverlies door originele en resulterende data te vergelijken.
$$
- Logistische regressie is een classificatie-algoritme om een binaire uitkomst te voorspellen op basis van onafhankelijke variabelen.
Databruikbaarheid na PCA-masking
Voer classificatie uit met logistieke regressie en kijk naar nauwkeurigheidsverlies.
# Splits de resulterende dataset in train- en testdata x_train, x_test, y_train, y_test = train_test_split(x_data_pca, y, test_size=0.2)# Maak het model lr = LogisticRegression(max_iter=200)# Train het model lr.fit(x_train,y_train)# Voer het model uit en voorspel om de accuracy te krijgen acc = lr.score(x_test, y_test) * 100 print("Test Accuracy is ", acc)
Test Accuracy is 85.24590163934425
Databruikbaarheid vóór PCA-masking
Voer classificatie uit met logistieke regressie en bekijk de score met de originele data
# Splits de resulterende dataset in train- en testdata
x_train, x_test, y_train, y_test = train_test_split(x_data.to_numpy(),y,test_size = 0.2)
# Maak het model
lr = LogisticRegression(max_iter=200)
# Train het model
lr.fit(x_train,y_train)
# Voer het model uit en voorspel om de accuracy te krijgen
acc = lr.score(x_test,y_test) * 100
print("Test Accuracy is ", acc)
Test Accuracy is 85.24590163934425
Laten we oefenen!
Dataprivacy en anonimisering in Python

