Gegevens met continue waarden anonimiseren
Dataprivacy en anonimisering in Python

Rebeca Gonzalez
Instructor
Continue variabelen
- leeftijd
- lengte
- gewicht
- temperatuur
- datum en tijd
Continue variabelen
# Bekijk de dataset
hr.head()
Age BusinessTravel Department EducationField EmployeeNumber
0 41 Travel_Rarely Sales Life Sciences 1
1 49 Travel_Frequently Research & Development Life Sciences 2
2 37 Travel_Rarely Research & Development Other 4
3 33 Travel_Frequently Research & Development Life Sciences 5
4 27 Travel_Rarely Research & Development Medical 7
Continue verdelingen
Gebruik de beste continue verdeling voor onze data.
- Maak een histogram
- Probeer continue functies en fit ze op het histogram.
- Behoud de functie met de kleinste fout t.o.v. het histogram.
Continue verdeling
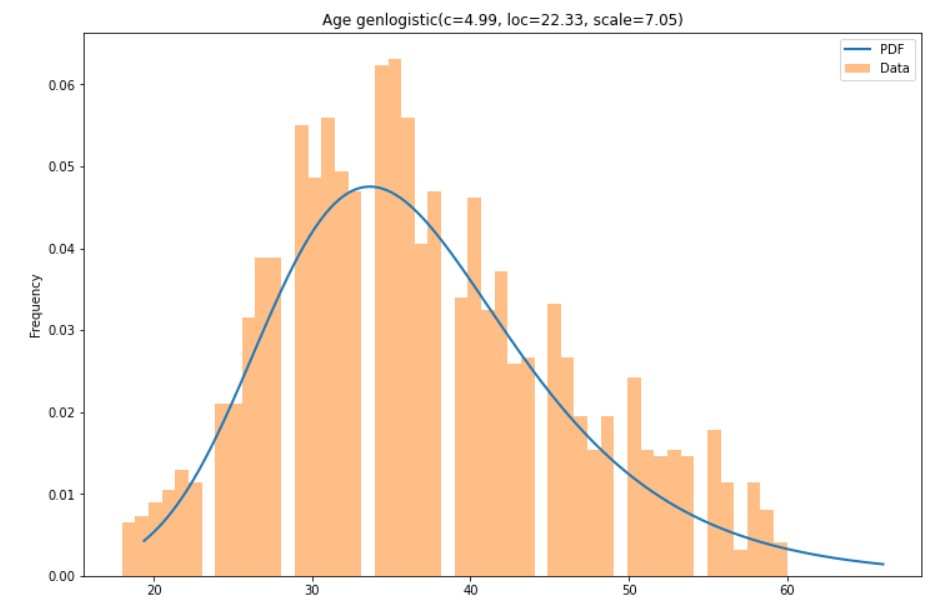
Een verdeling toepassen
import scipy.stats# Fit de genlogistic-verdeling op de continue variabele Age params = scipy.stats.genlogistic.fit(hr['Age'])# Bekijk de parameters van de continue functies print(params)
(4.9899067653418285, 22.32808853181744, 7.046590524738551)
Steekproeven uit de continue verdeling
# Steekproef uit de genlogistic-verdeling df['Age'] = scipy.stats.genlogistic.rvs(size=len(df.index), *params)# Bekijk de resulterende dataset df['Age'].head()
Age BusinessTravel Department EducationField EmployeeNumber
0 40.767259 Travel_Rarely Sales Life Sciences 1
1 45.730504 Travel_Frequently Research & Development Life Sciences 2
2 41.910050 Travel_Rarely Research & Development Other 4
3 35.275320 Travel_Frequently Research & Development Life Sciences 5
4 40.198134 Travel_Rarely Research & Development Medical 7
Steekproeven uit de continue verdeling
# Afronden om discrete waarden te krijgen
df['Age'] = df['Age'].round()
Age BusinessTravel Department EducationField EmployeeNumber
0 41 Travel_Rarely Sales Life Sciences 1
1 46 Travel_Frequently Research & Development Life Sciences 2
2 42 Travel_Rarely Research & Development Other 4
3 35 Travel_Frequently Research & Development Life Sciences 5
4 40 Travel_Rarely Research & Development Medical 7
Laten we oefenen!
Dataprivacy en anonimisering in Python

