Introductie tot k-anonimiteit
Dataprivacy en anonimisering in Python

Rebeca Gonzalez
Data engineer
Waarom is k-anonimiteit belangrijk?

Waarom is dit belangrijk?
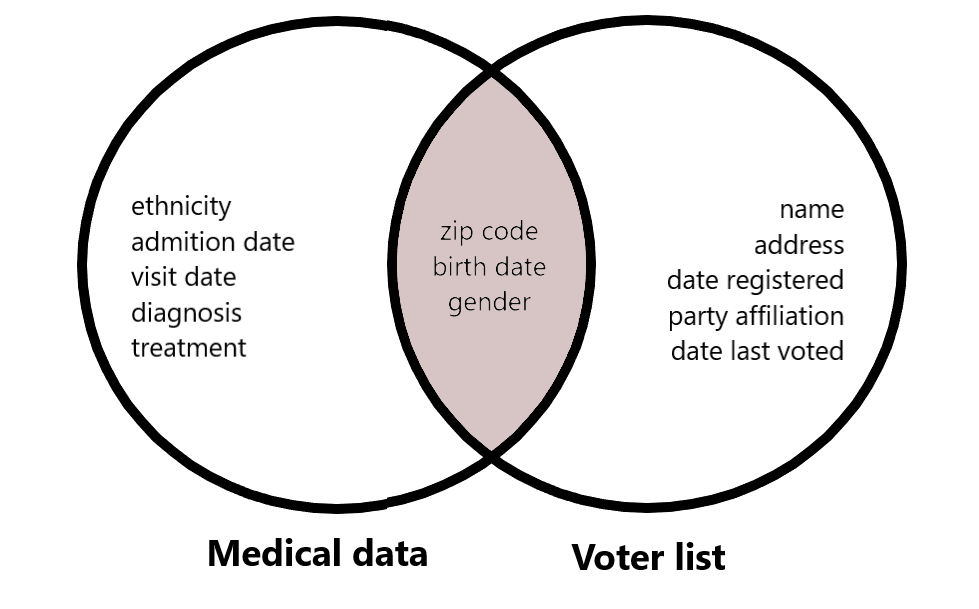
Definitie van k-anonimiteit

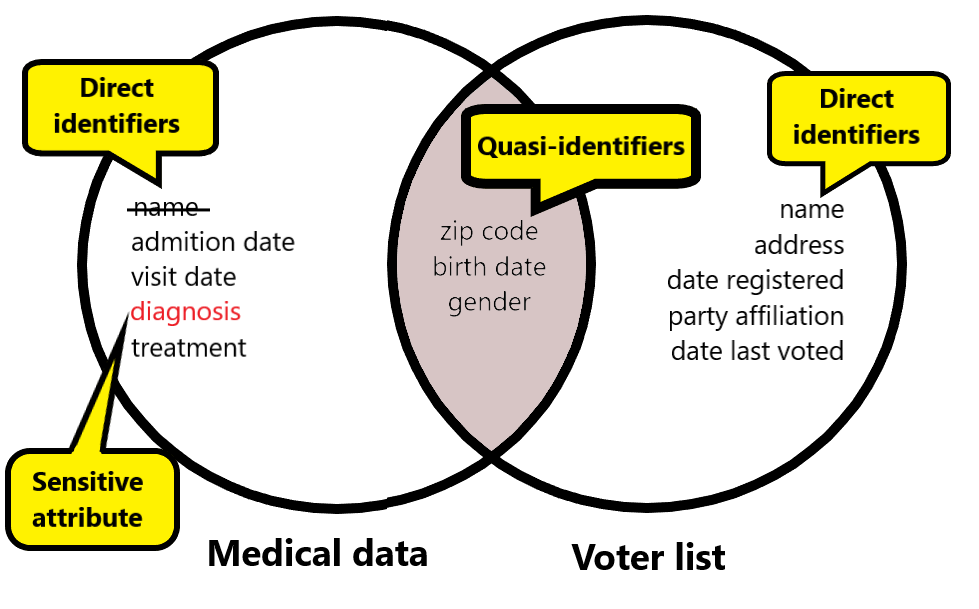
K-anonimiteit: terminologie
Dataprivacy en anonimisering in Python
Rebeca Gonzalez
Data engineer

