Omgaan met ongebalanceerde datasets
Fraudedetectie in R

Bart Baesens
Professor Data Science at KU Leuven
Ongebalanceerde datasets

Ongebalanceerde datasets

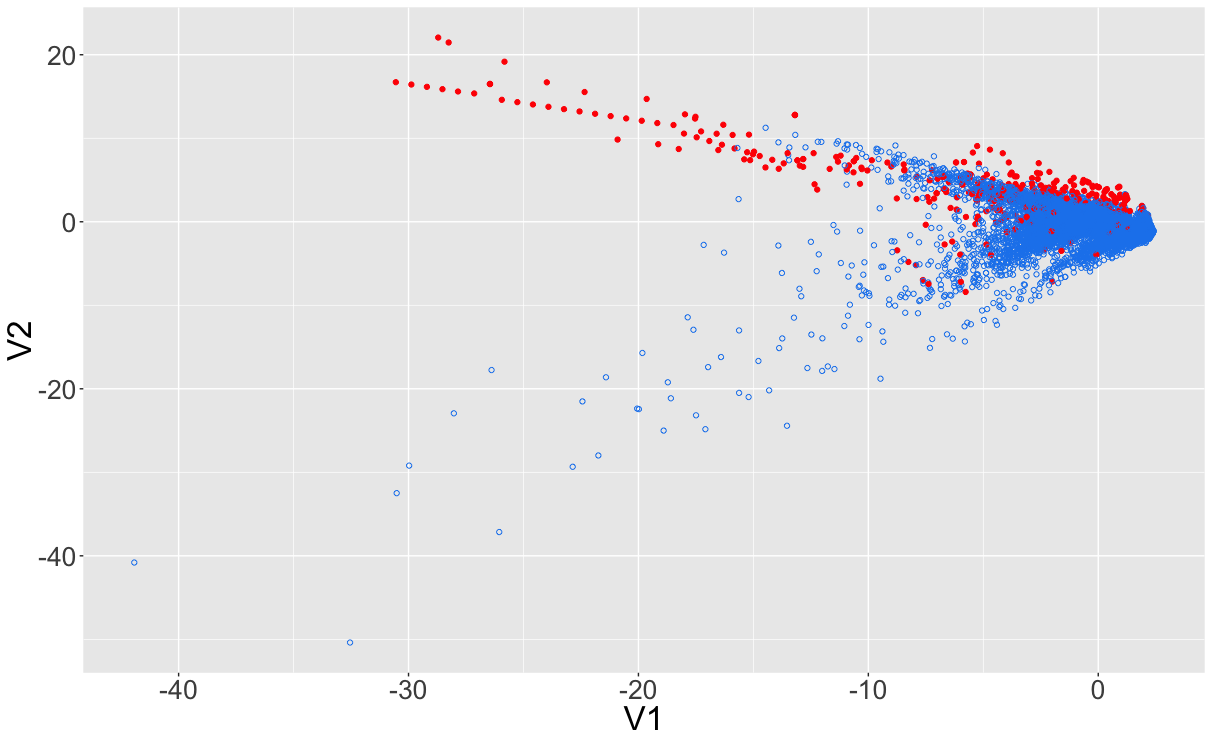
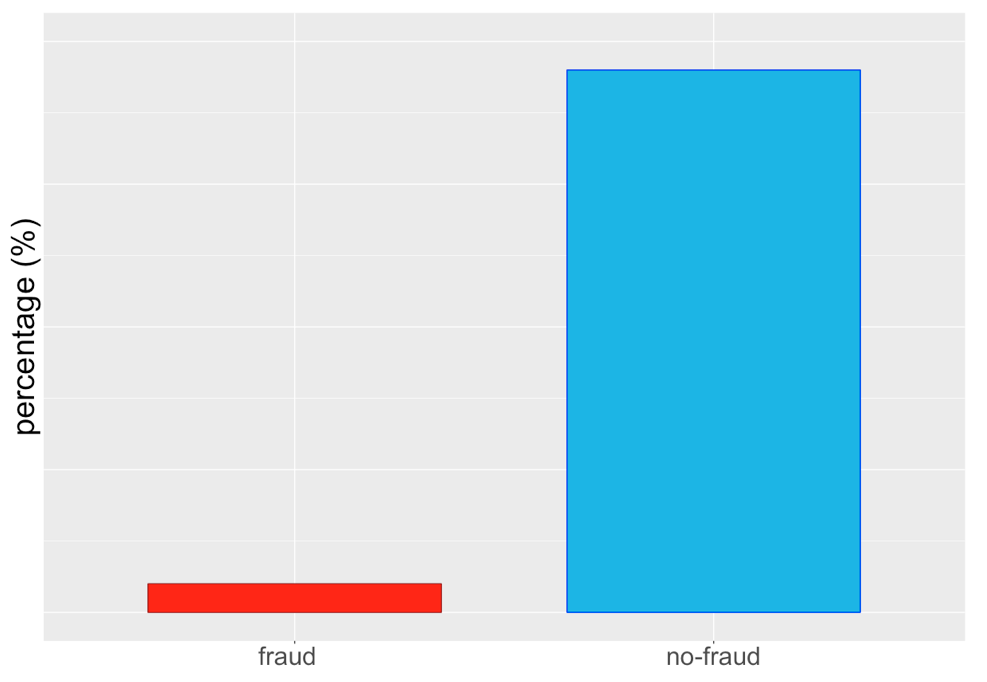
Oorspronkelijke onbalans
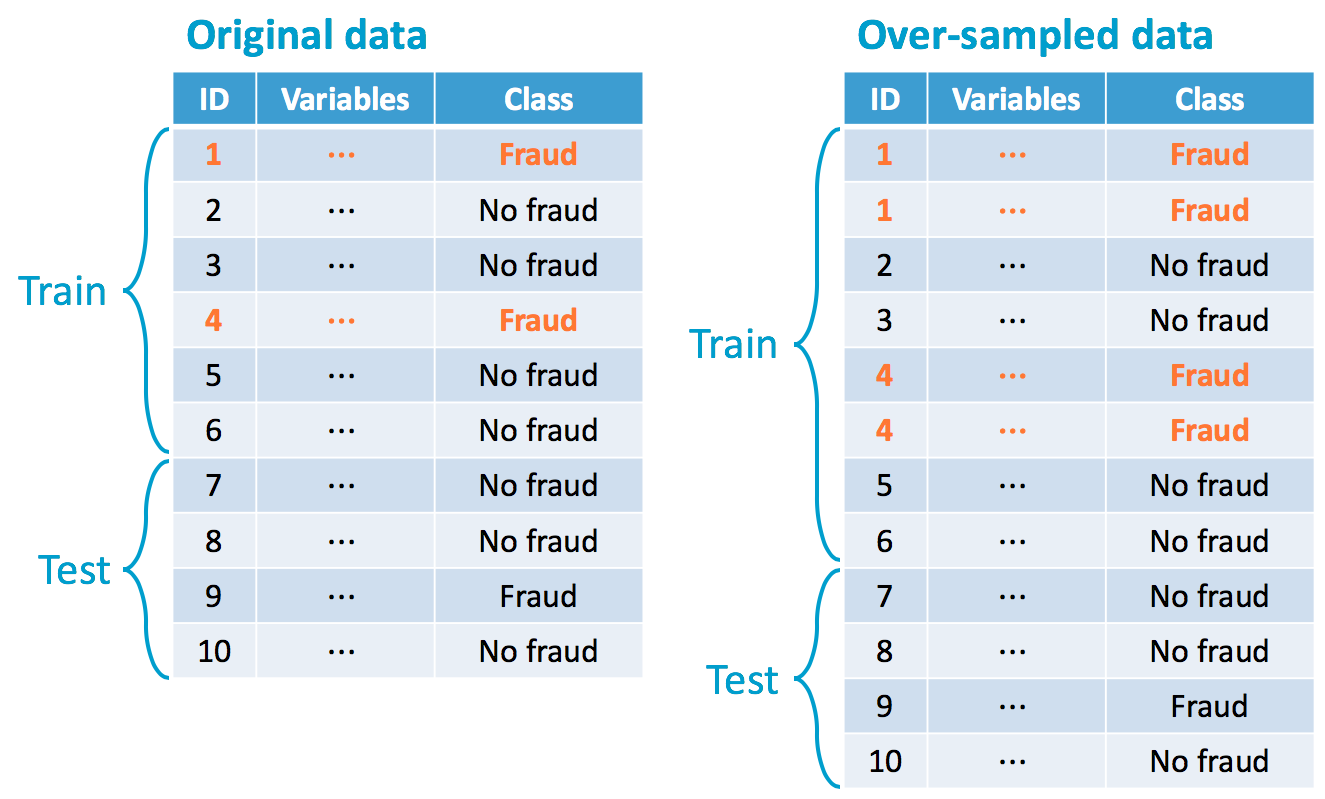
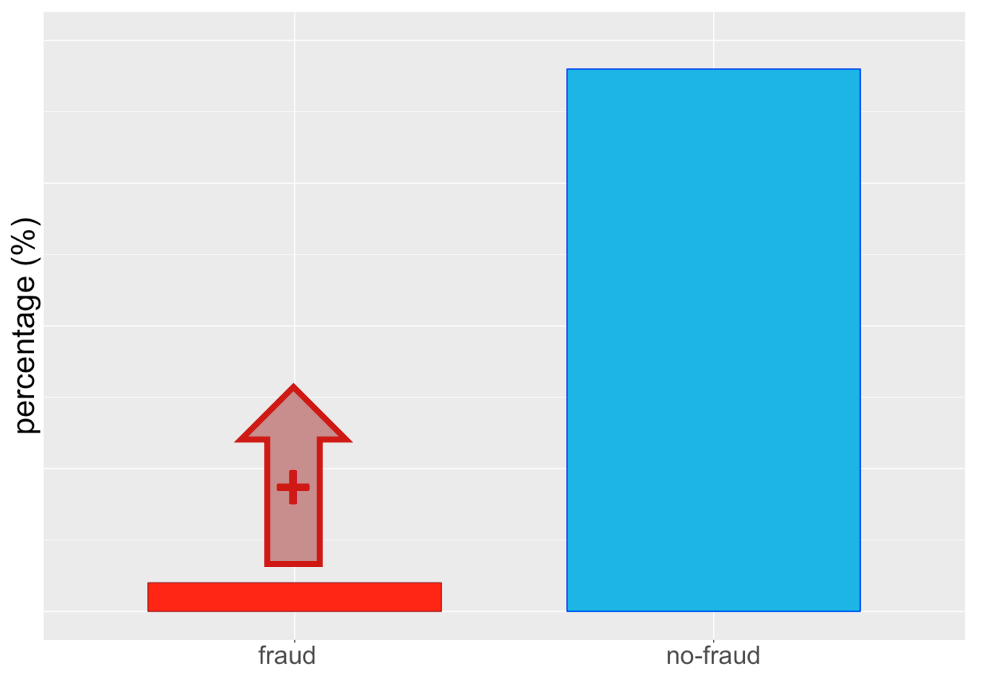
Over-samplen van de minderheidsklasse...
... of majorityklasse onder-samplen ...
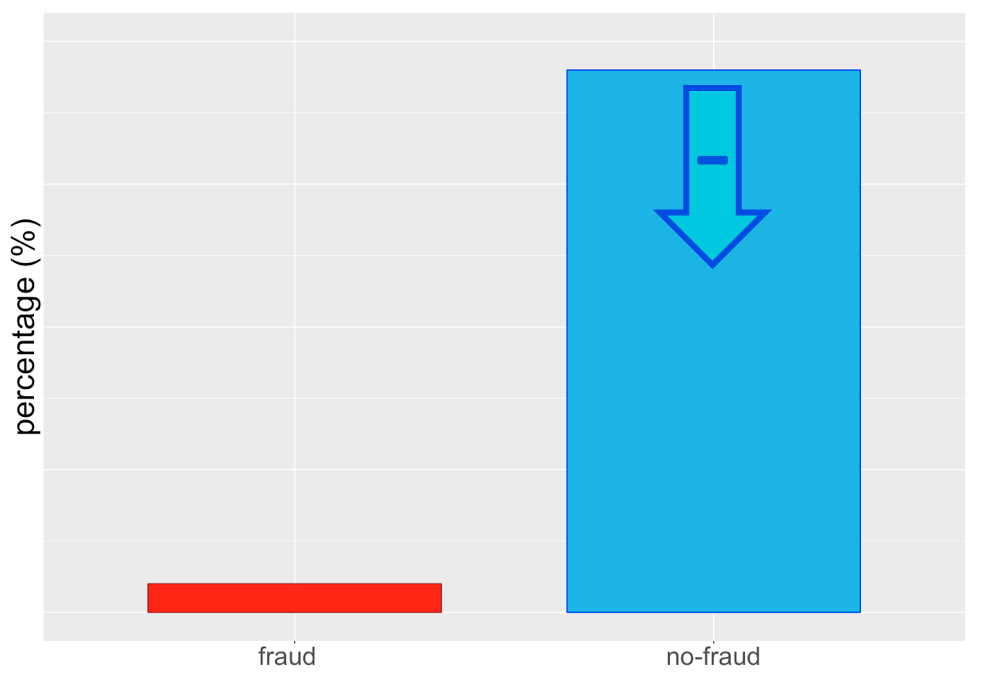
... of beide!
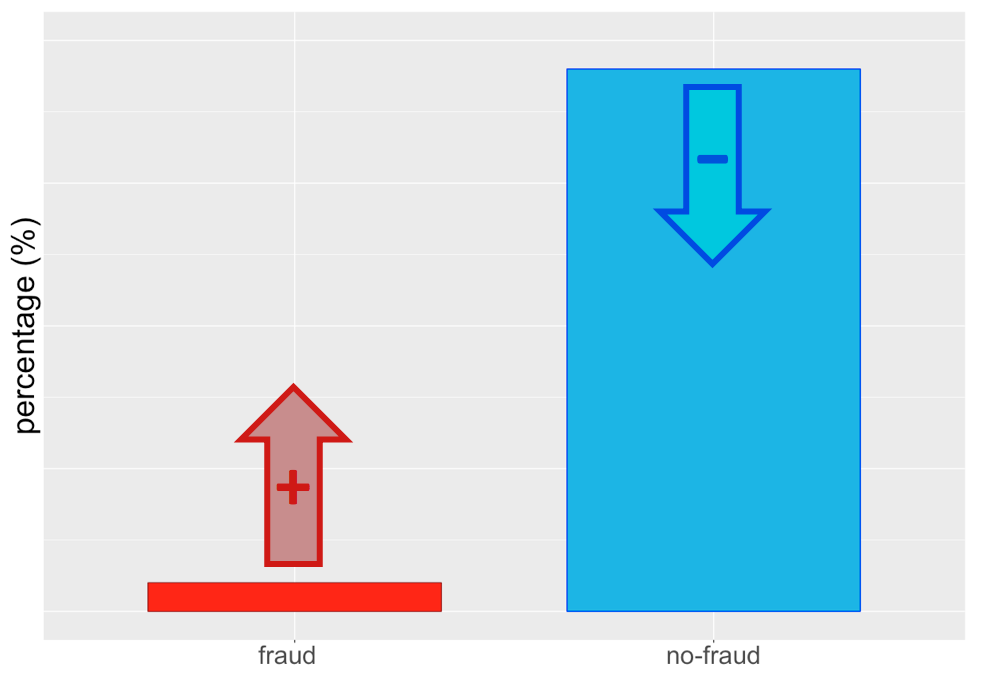
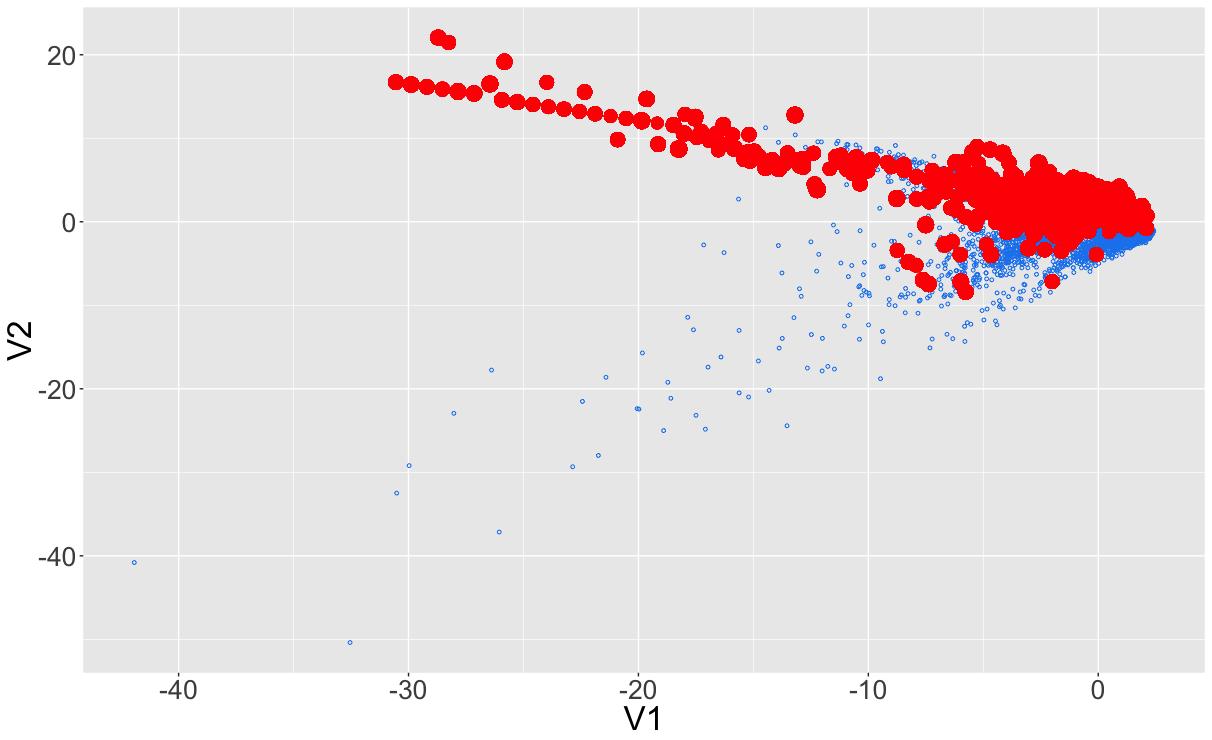
Resultaat na sampling...
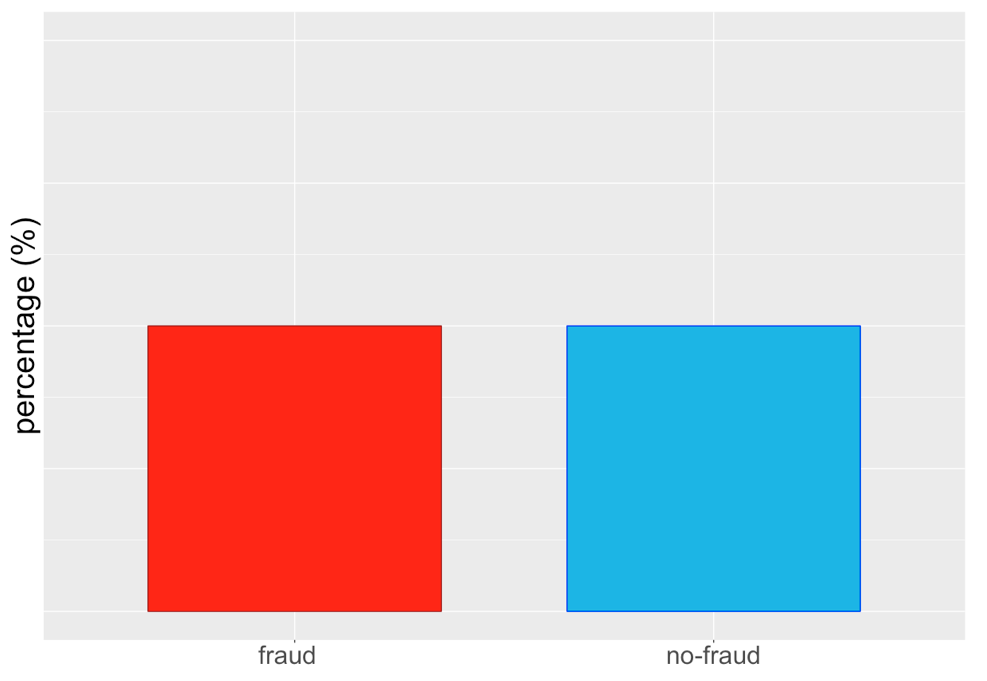
... of zo
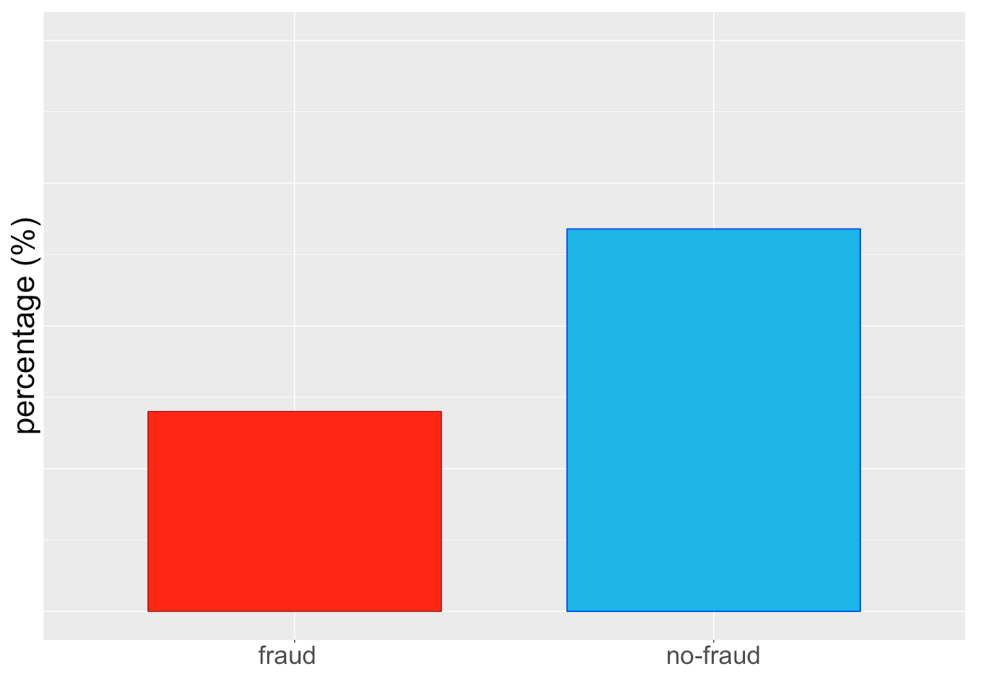
Random over-sampling (ROS)