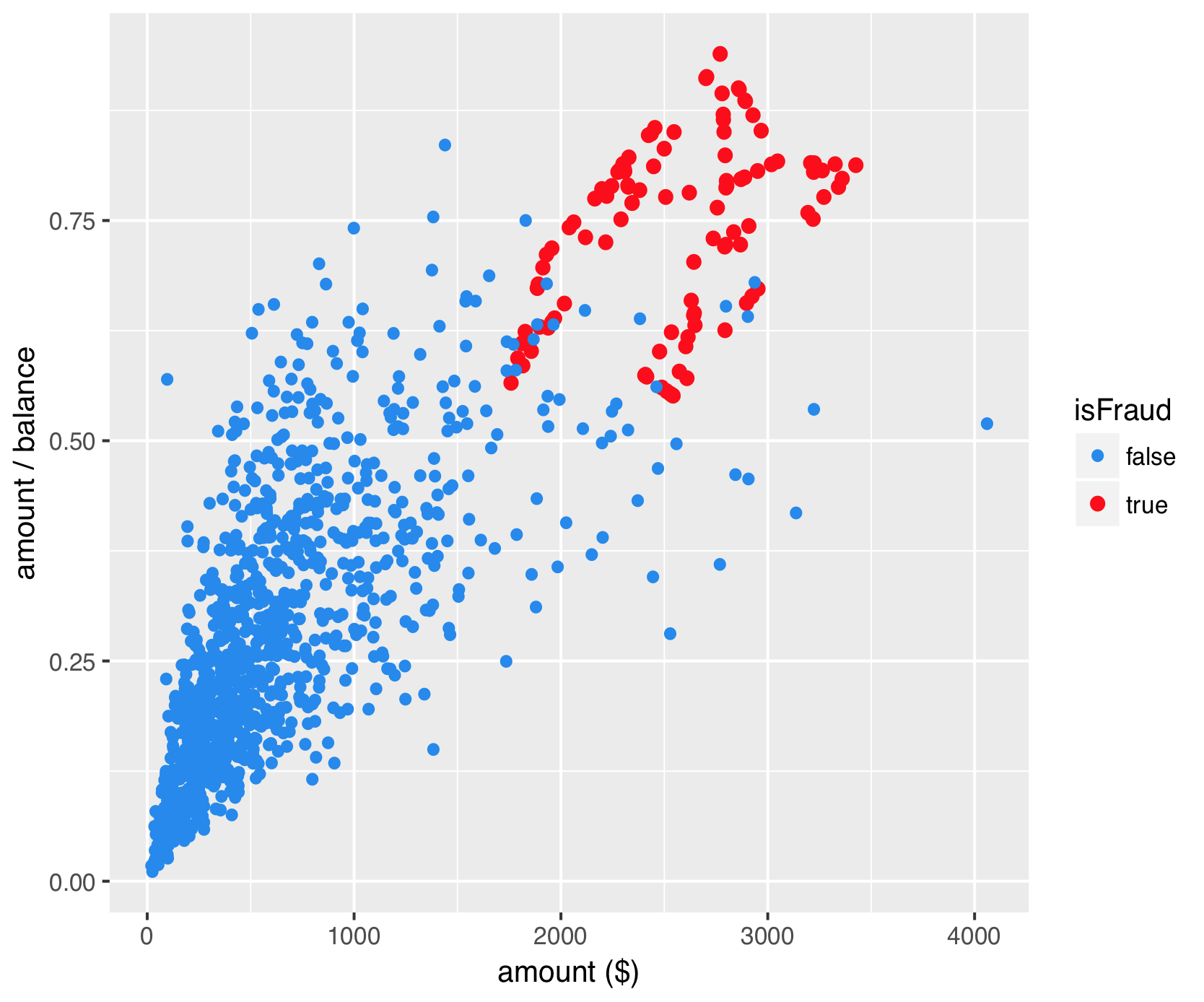
Synthetische oversampling
Fraudedetectie in R

Sebastiaan Höppner
PhD researcher in Data Science at KU Leuven
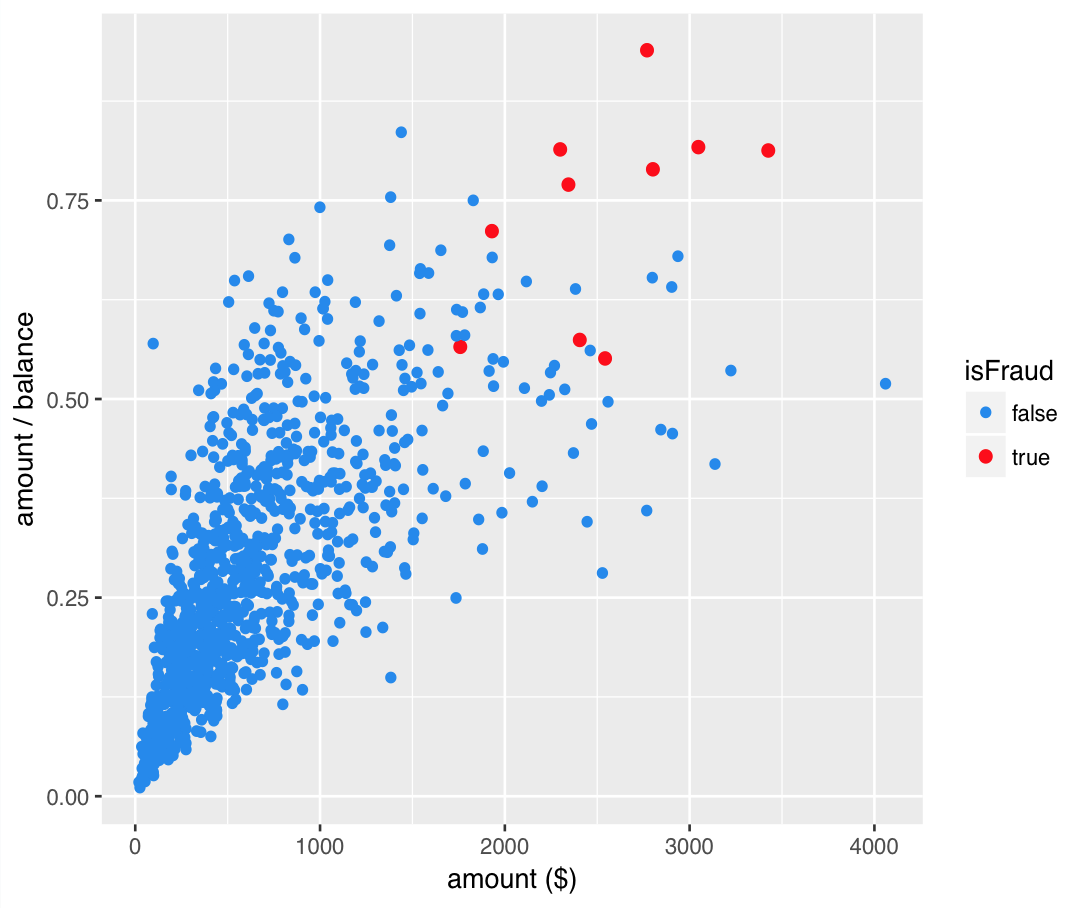
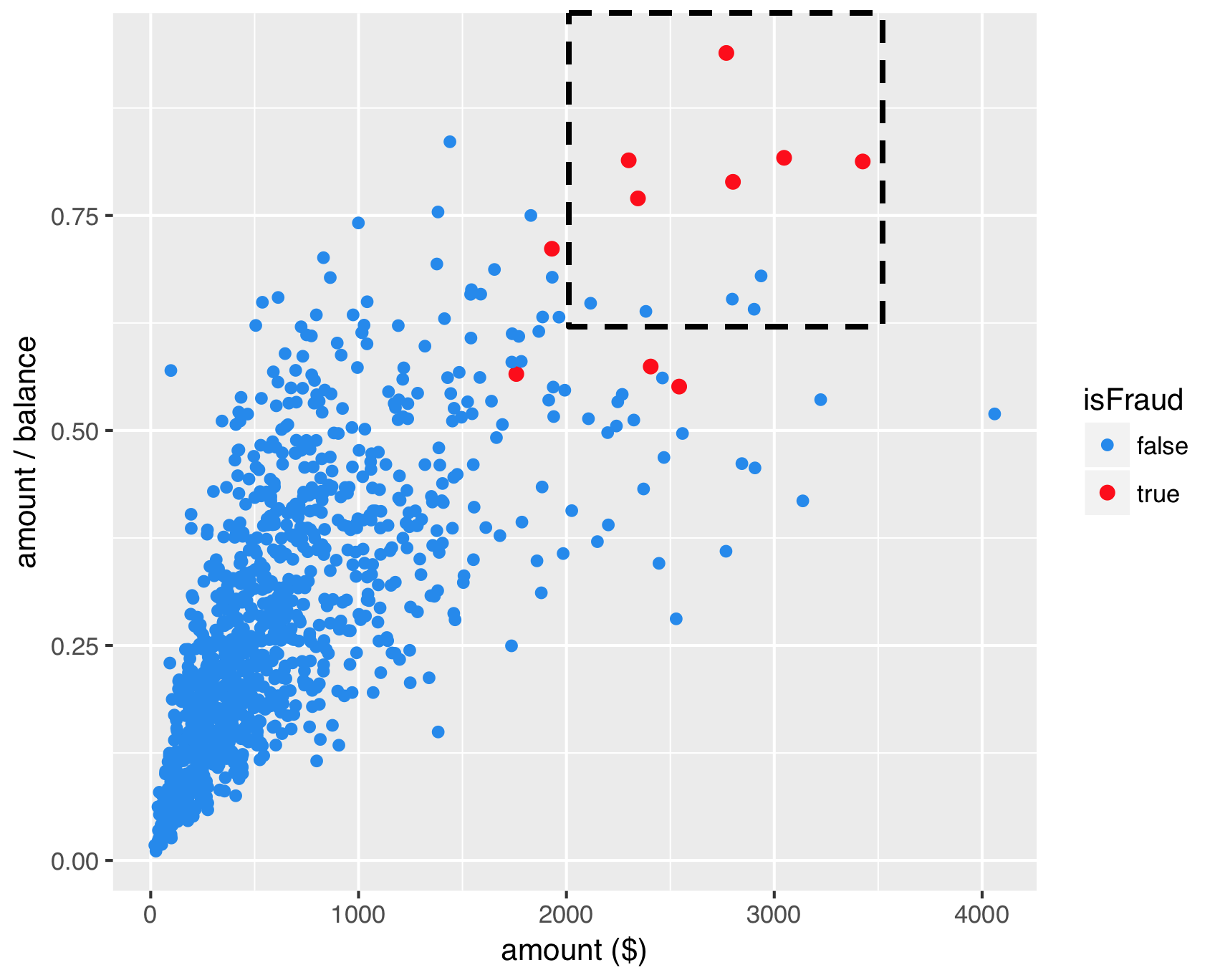
SMOTE
SMOTE - stap 1
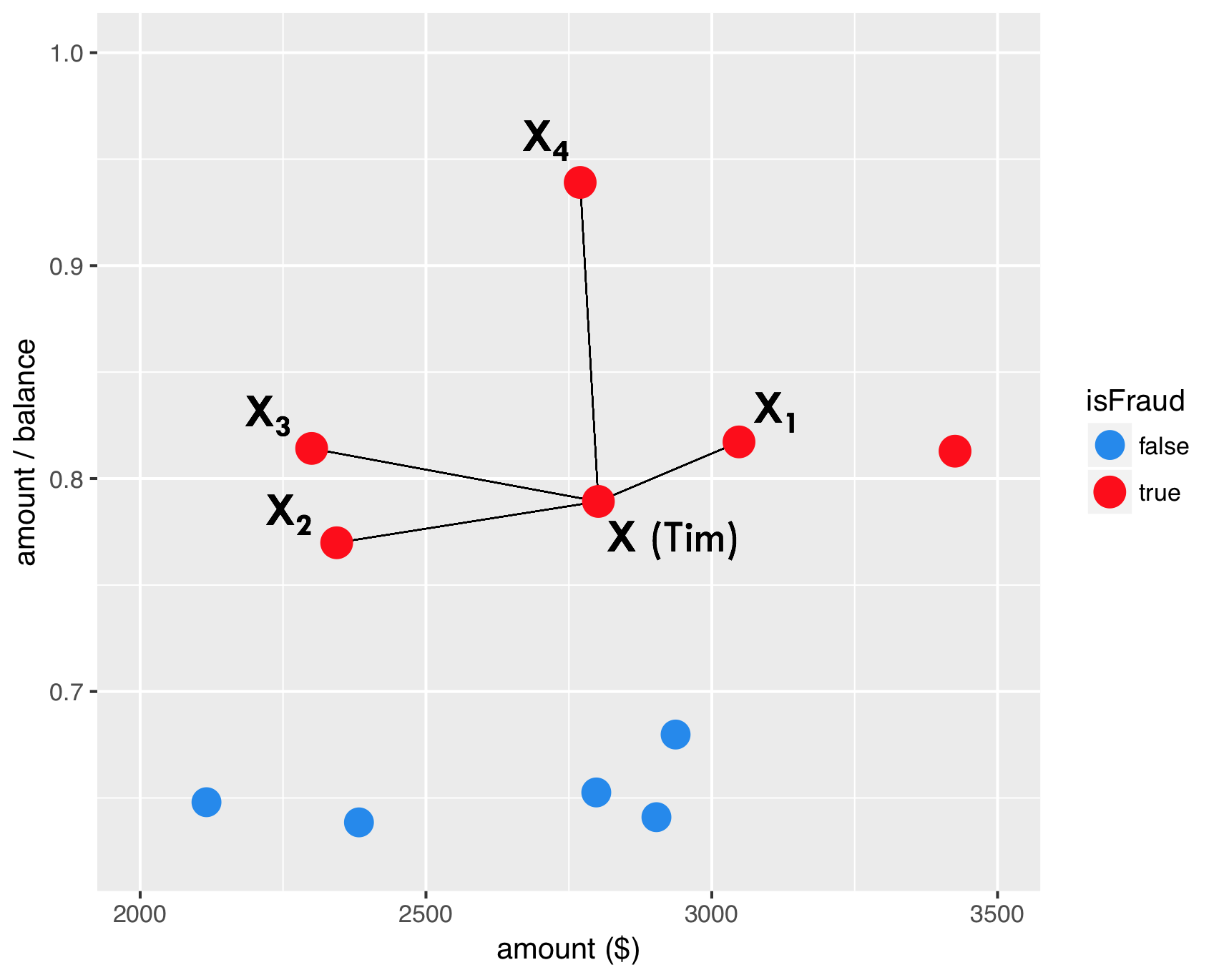
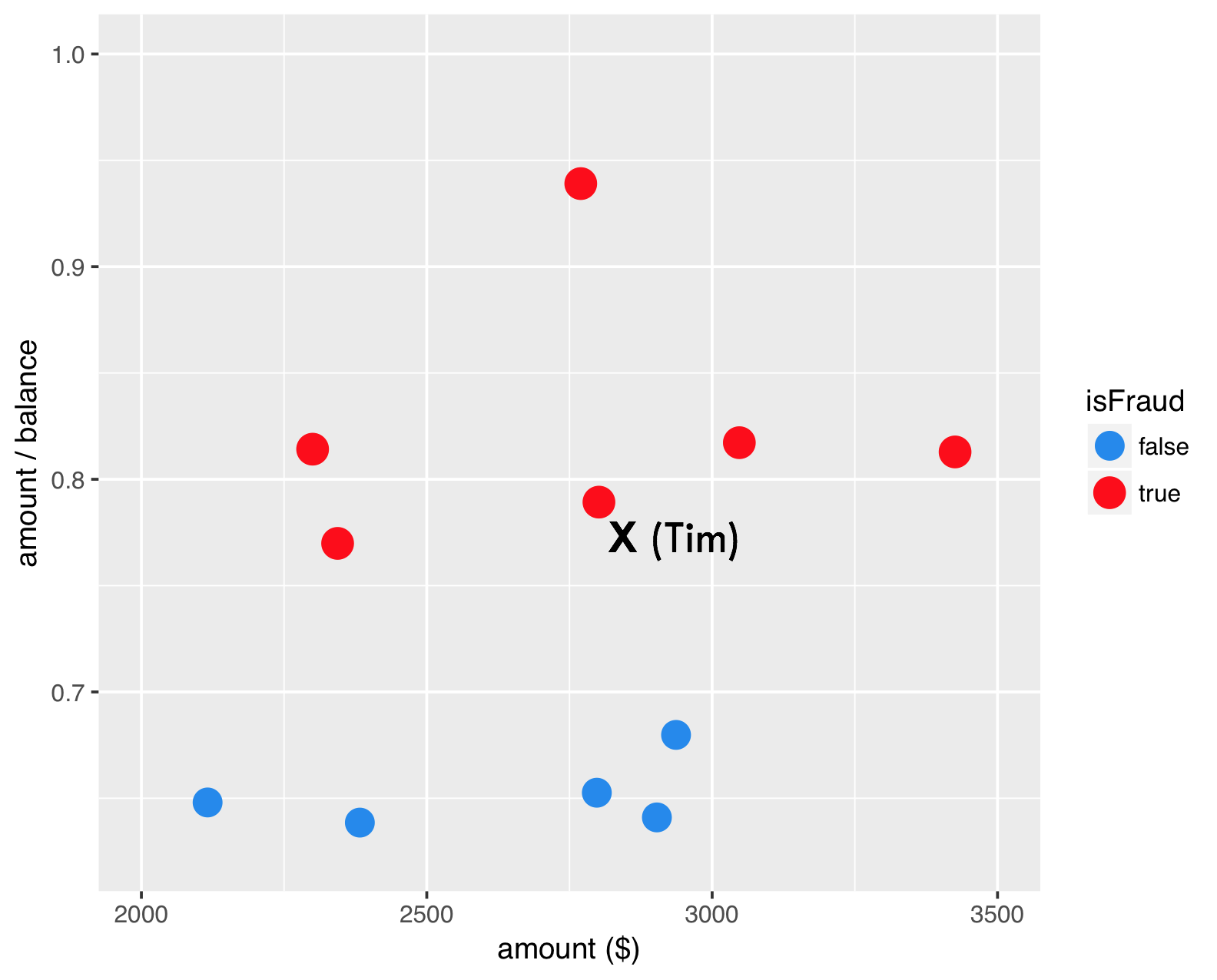
SMOTE - stap 2
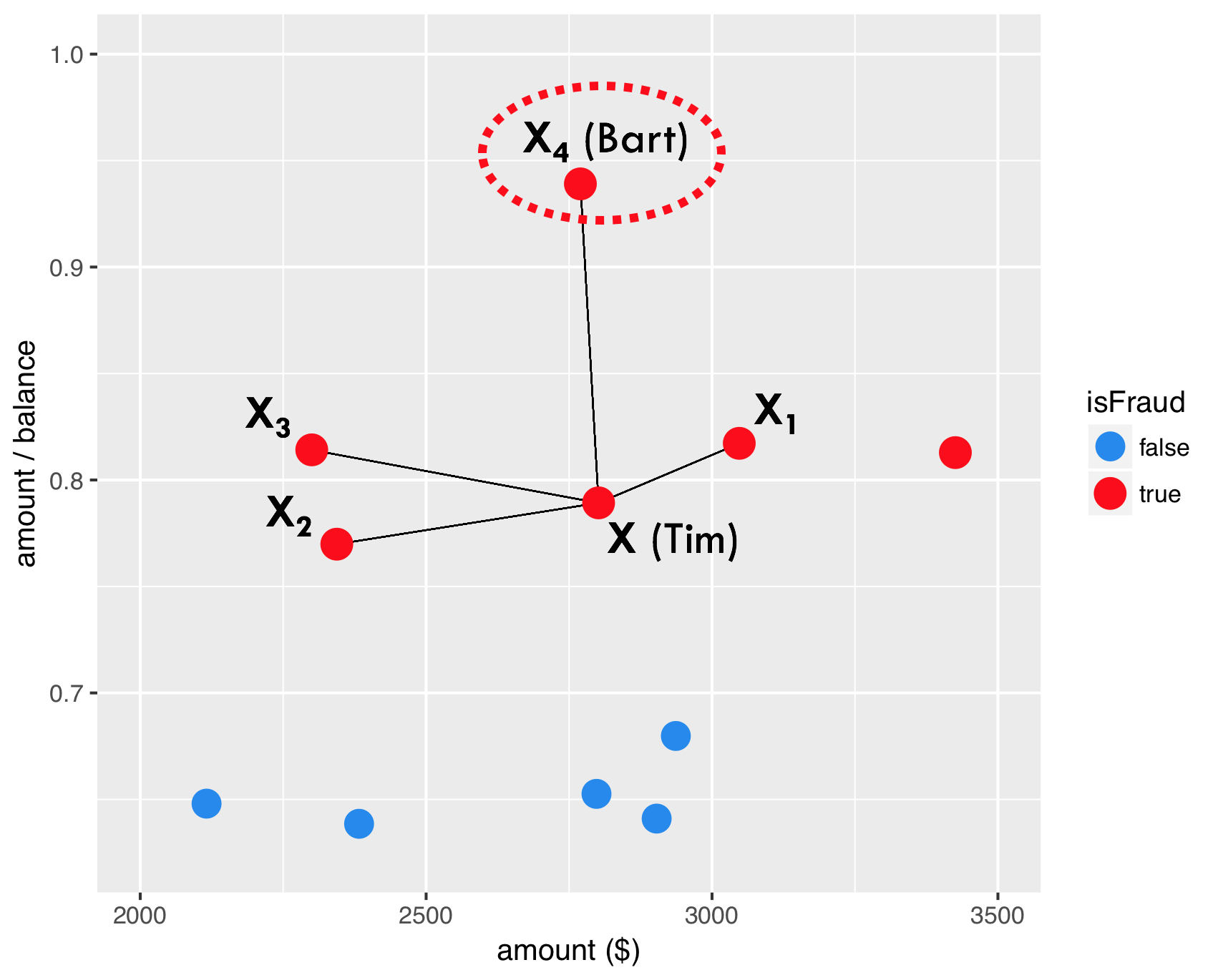
SMOTE - stap 3
Stap 3: maak een synthetisch voorbeeld

SMOTE - stap 3
Stap 3: maak een synthetisch voorbeeld

SMOTE - stap 3
Stap 3: maak een synthetisch voorbeeld
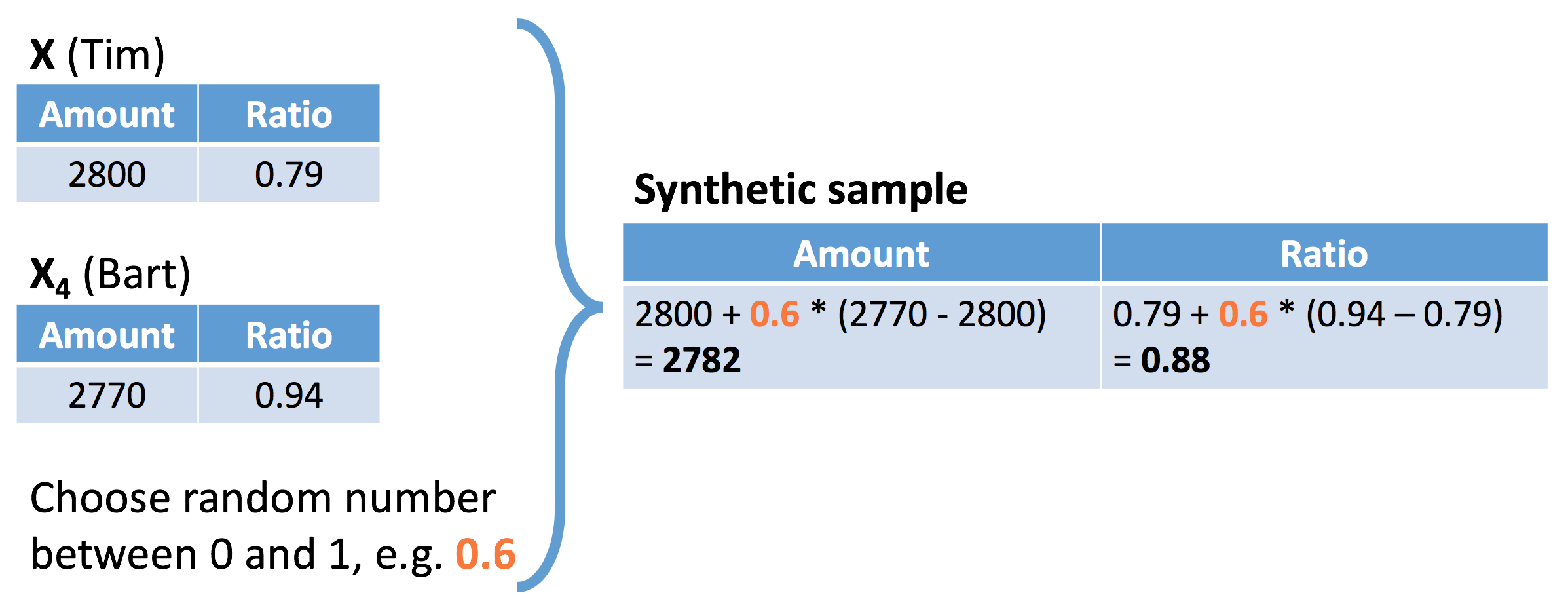
SMOTE - stap 3
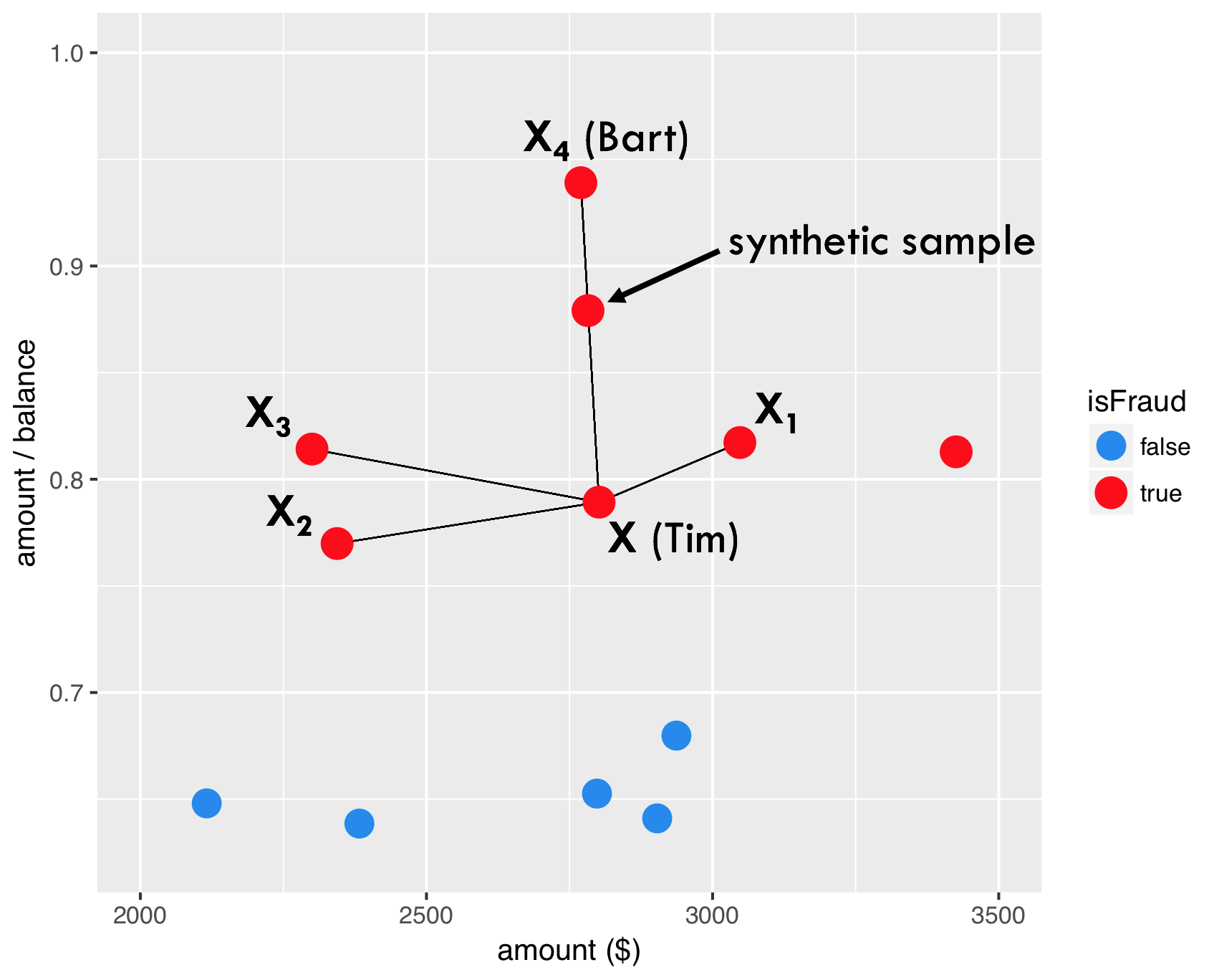
SMOTE - stap 4