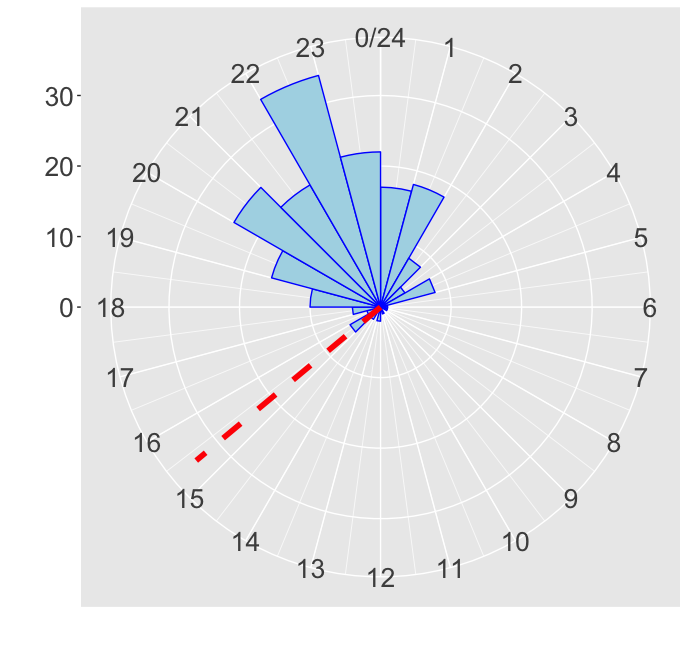
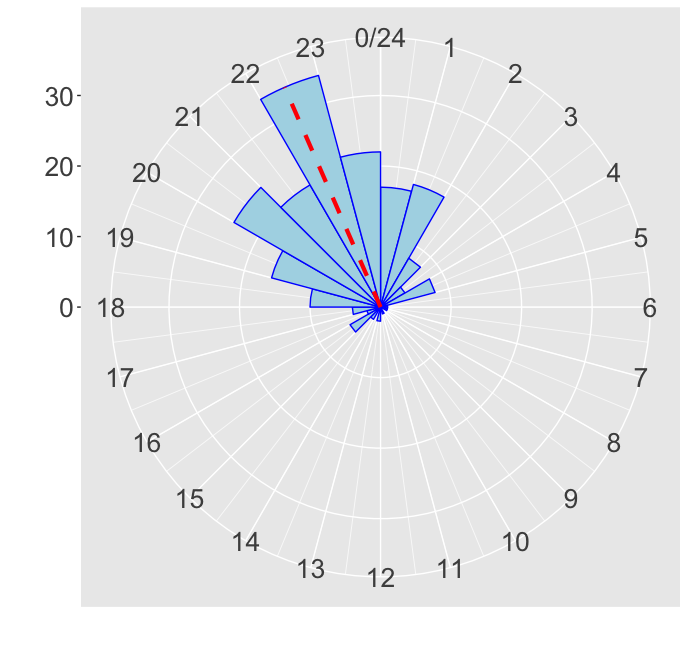
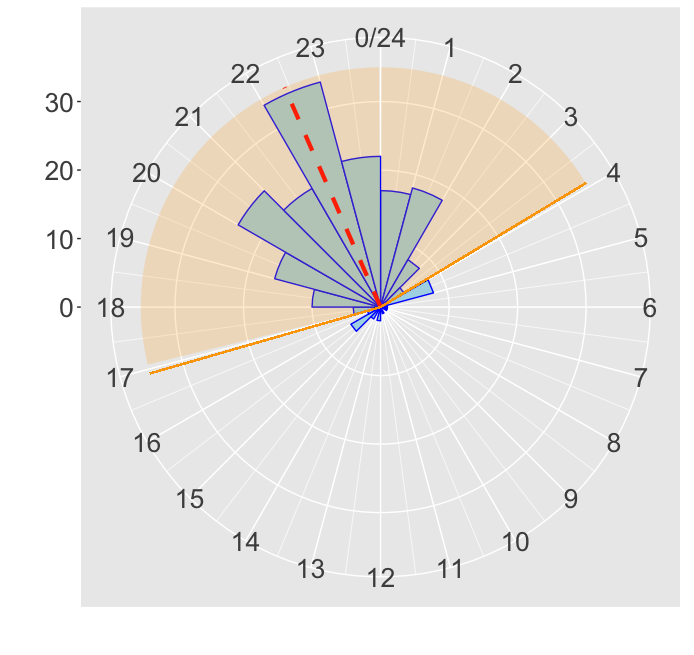
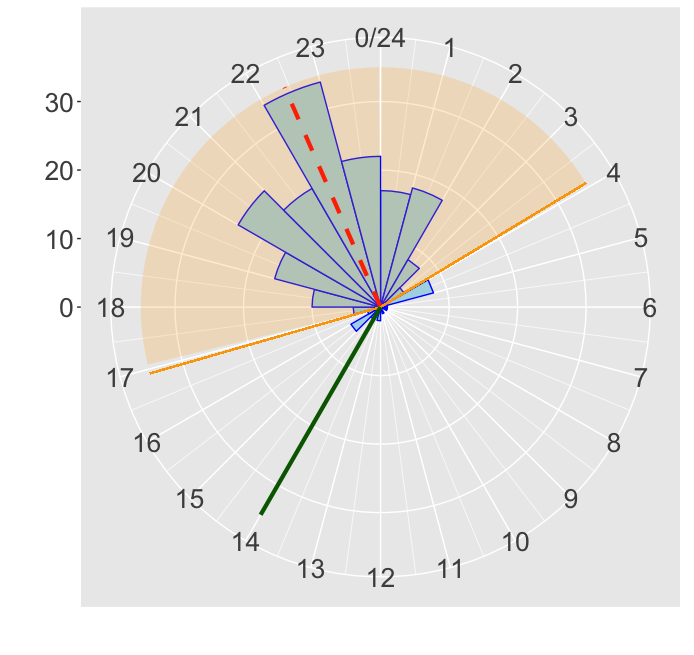
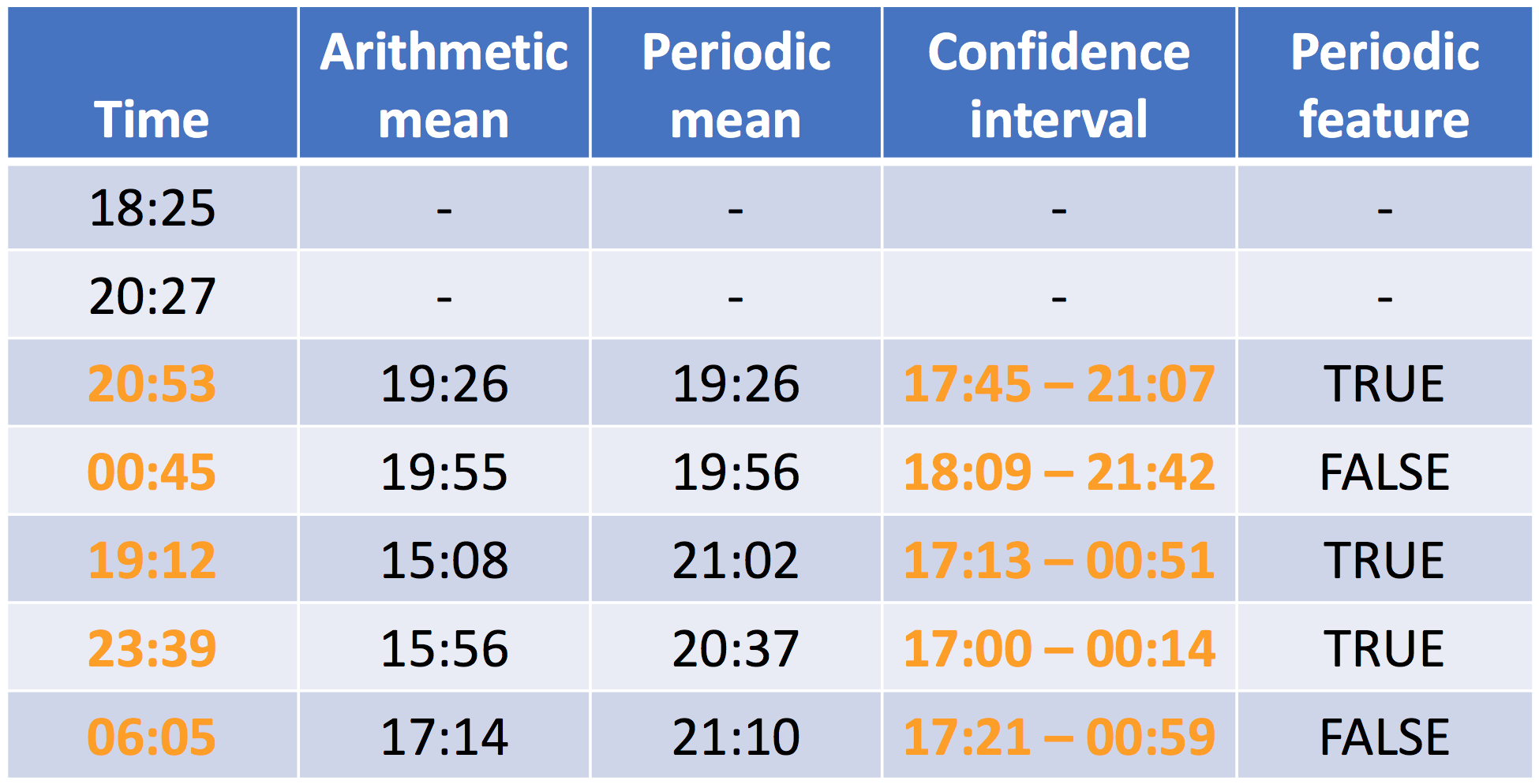
## ts bevat de timestamps 18.42, 20.45, 20.88, 0.75, 19.20, 23.65 en 6.08
time_feature = c(NA, NA)
for (i in 3:length(ts)) {
ts_history <- ts[1:(i-1)] ## (1) Vorige timestamps
estimates <- mle.vonmises(ts_history) ## (2) Schat mu en kappa op historische timestamps
p_mean <- estimates$mu %% 24
concentration <- estimates$kappa
dens_i <- dvonmises(ts[i], mu = p_mean, kappa = concentration) ## (3) Schat dichtheid huidig timestamp
alpha <- 0.90 ## (4) Check of dichtheid groter is dan afkap bij 90% betrouwbaarheid
quantile <- qvonmises((1-alpha)/2, mu=p_mean, kappa=concentration) %% 24
cutoff <- dvonmises(quantile, mu = p_mean, kappa = concentration)
time_feature[i] <- dens_i >= cutoff
}
print(time_feature)
NA NA TRUE FALSE TRUE TRUE FALSE