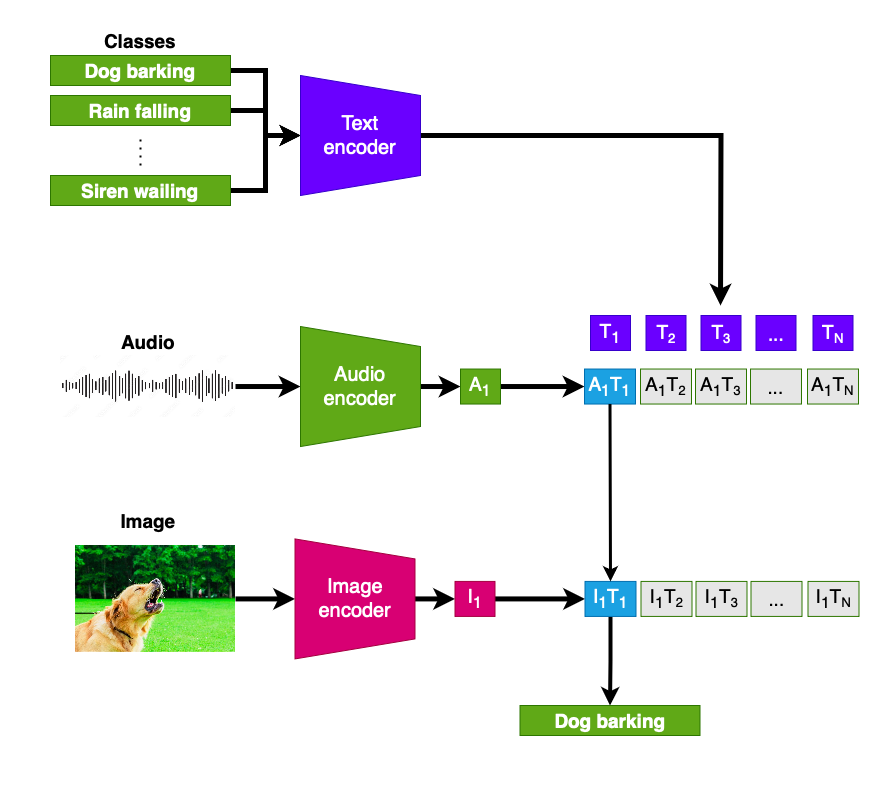
Zero-shot videoclassificatie
Multi-modale modellen met Hugging Face

James Chapman
Curriculum Manager, DataCamp
Zero-shot videoclassificatie

1 https://repository.duke.edu/dc/adviews/dmbb37204
CLAP
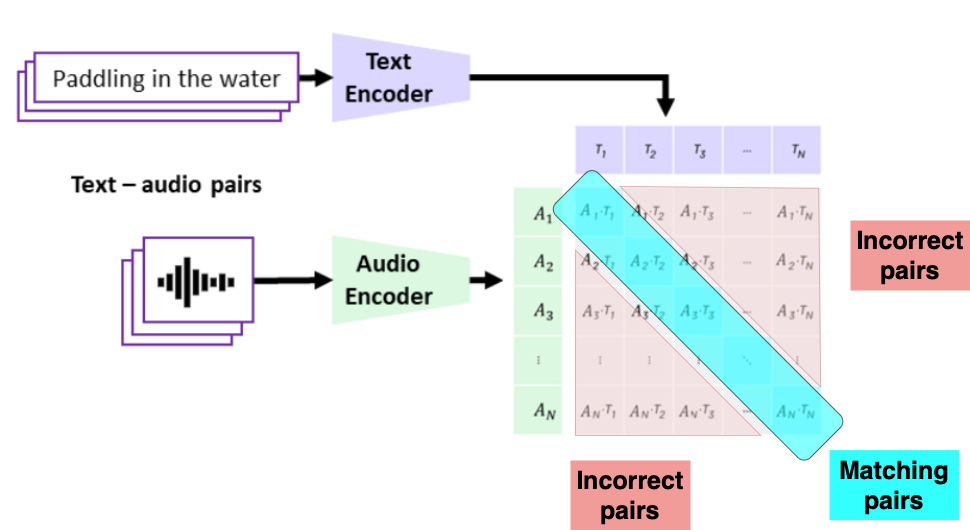
1 https://arxiv.org/html/2211.06687v4
Aanpak: multimodale ZSL
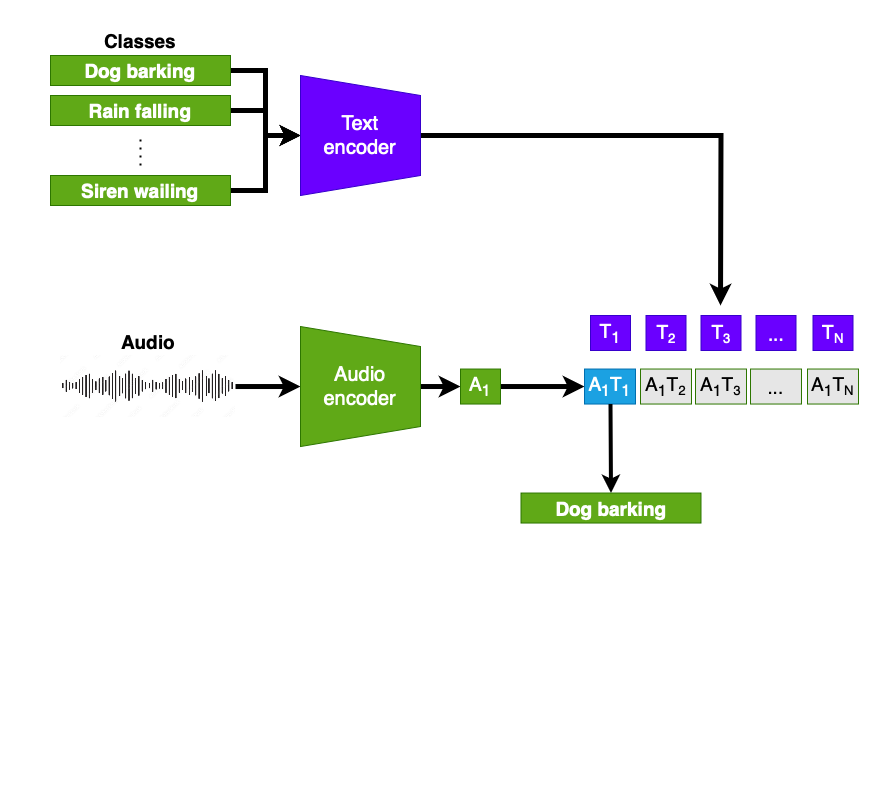
1 https://arxiv.org/html/2310.02298v3
Aanpak: multimodale ZSL