Multimodale sentimentanalyse
Multi-modale modellen met Hugging Face

James Chapman
Curriculum Manager, DataCamp
Vision-Language Models (VLM's)
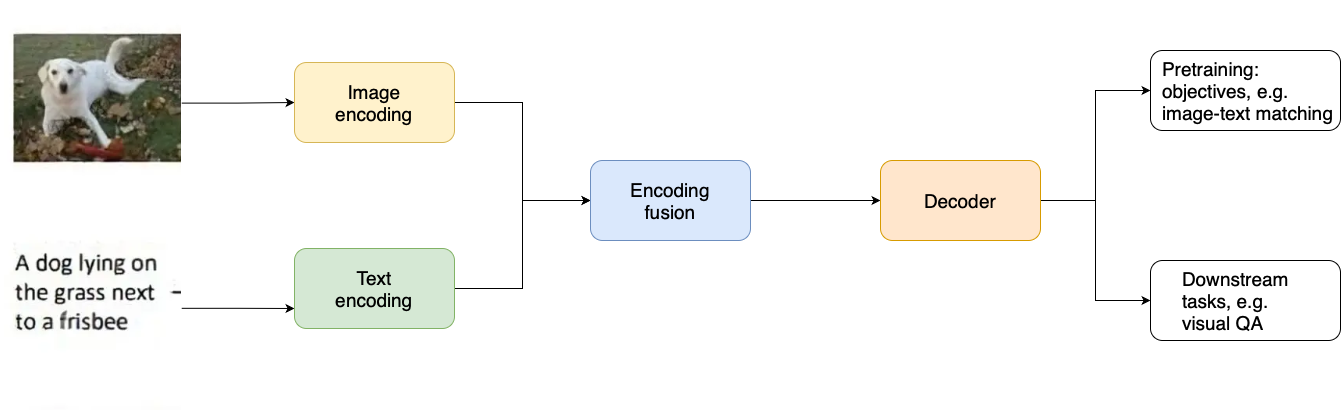
- Afbeelding en tekst apart gecodeerd
- Featurefusie
- Gedeelde representaties maken
- Meerdere taken met één model
Visuele redeneertaken
- VQA: Afbeelding + vraag → Directe antwoorden over de inhoud
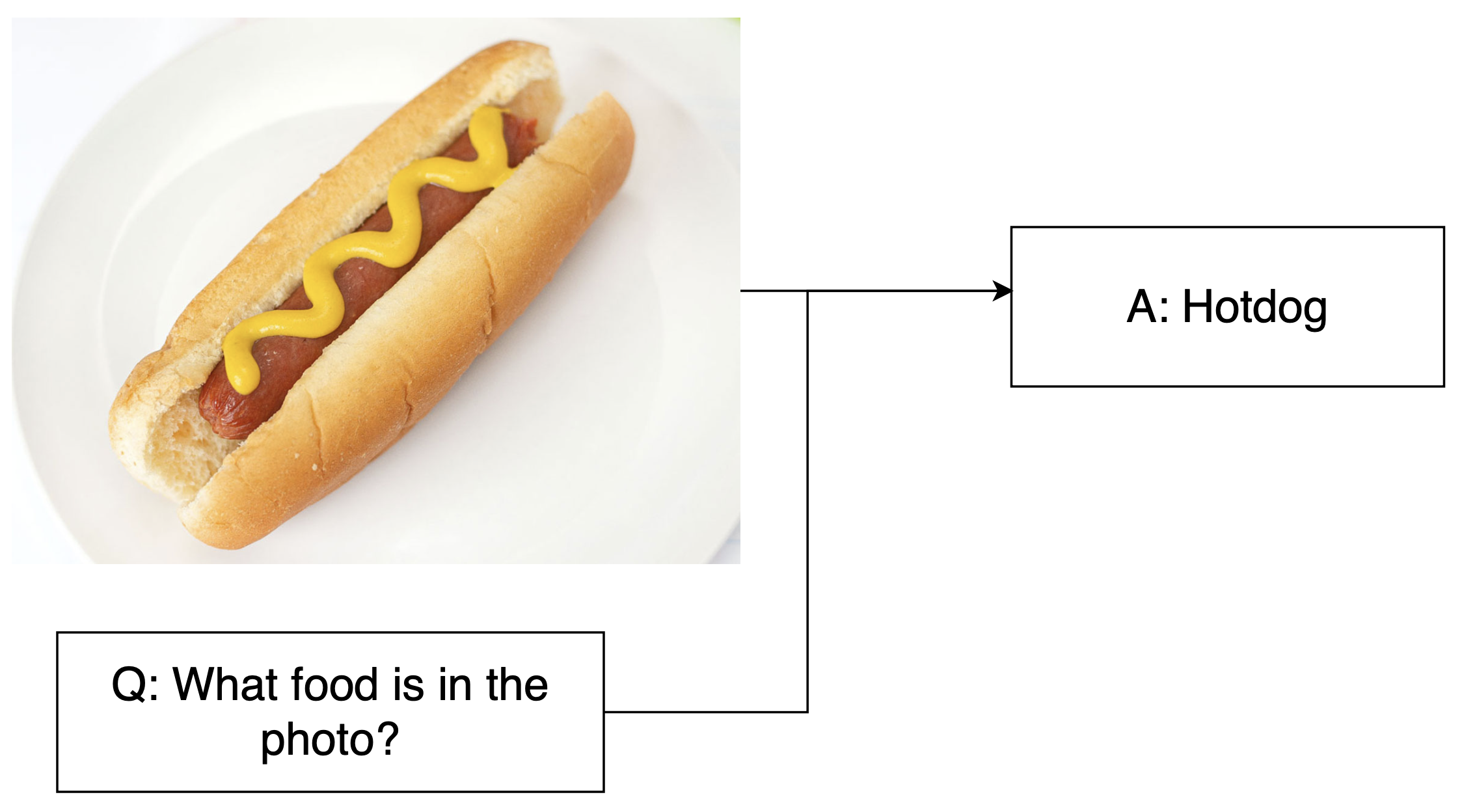
1 https://arxiv.org/pdf/1505.00468
Visuele redeneertaken
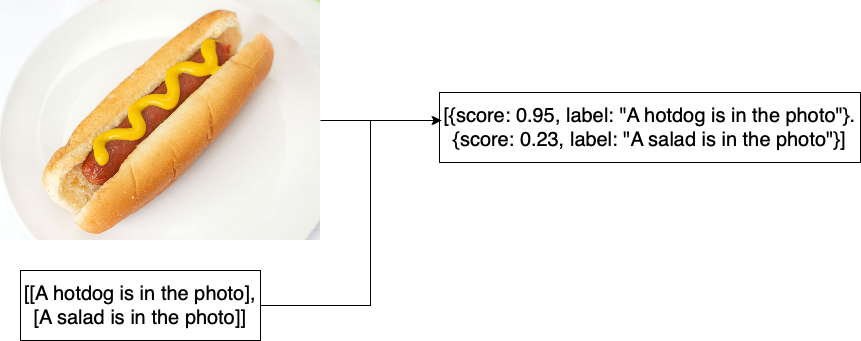
Visuele redeneertaken

Use case: effect op aandelenkoers


