Zero-shot beeldclassificatie
Multi-modale modellen met Hugging Face

James Chapman
Curriculum Manager, DataCamp
CLIP
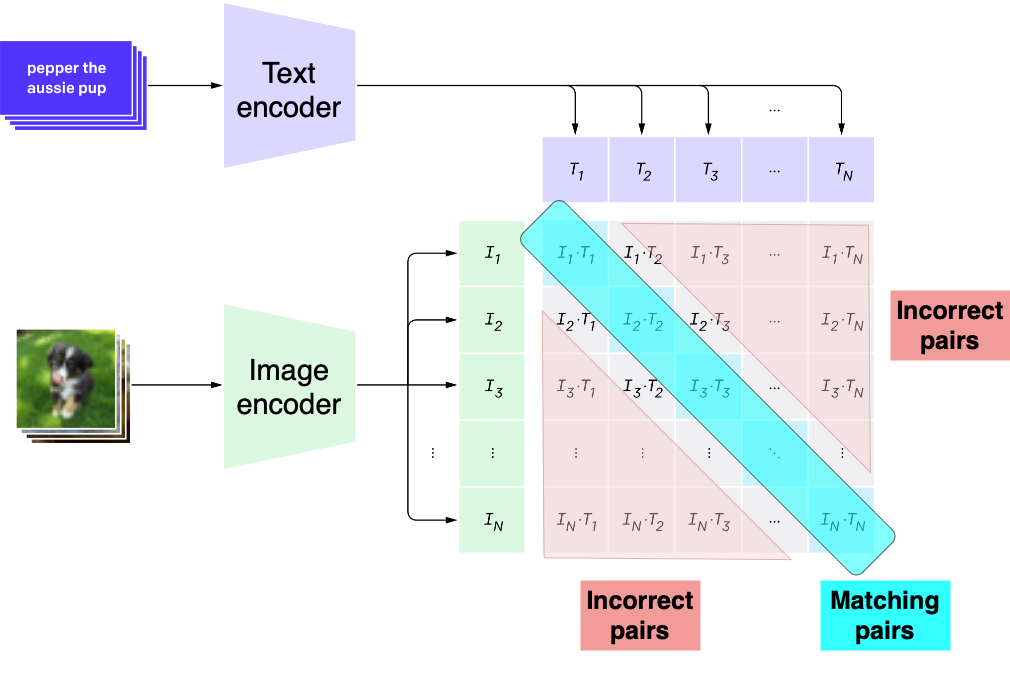
1 https://openai.com/index/clip/
Zero-shot learning
- Taken uitvoeren waarvoor het model niet is getraind
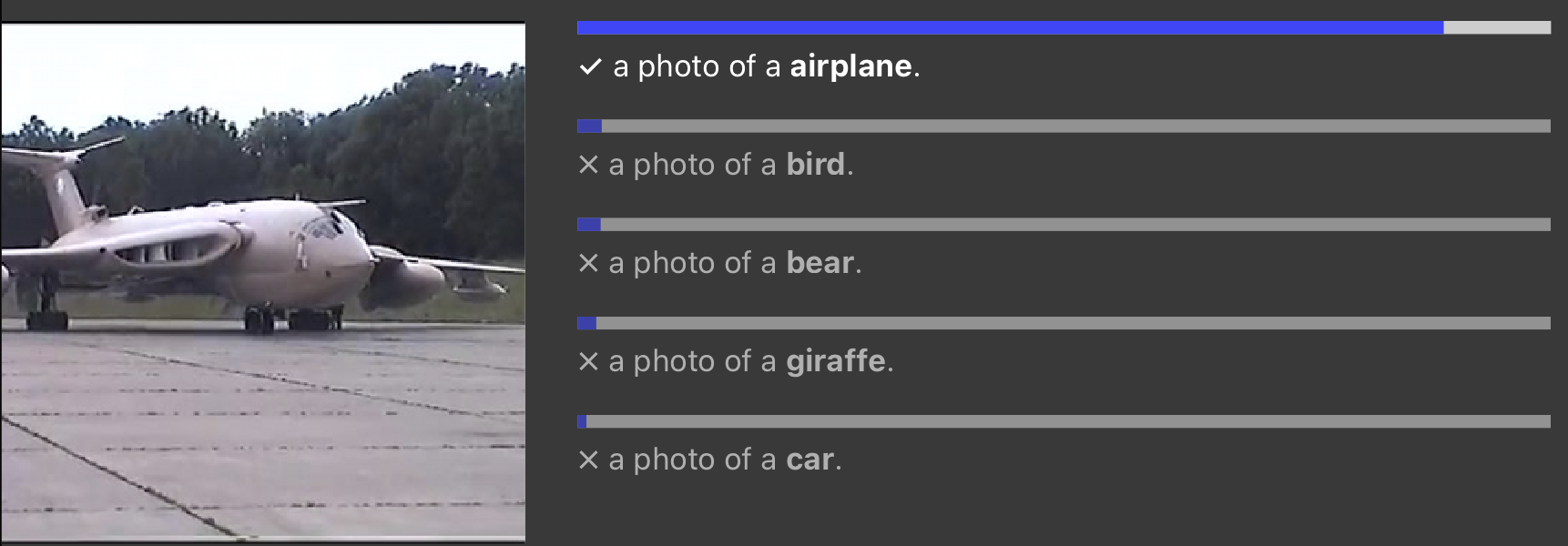
1 https://openai.com/index/clip/
Use case: productcategorisatie