Visuele vraagbeantwoording (VQA)
Multi-modale modellen met Hugging Face

James Chapman
Curriculum Manager, DataCamp
Multimodale QA-taken
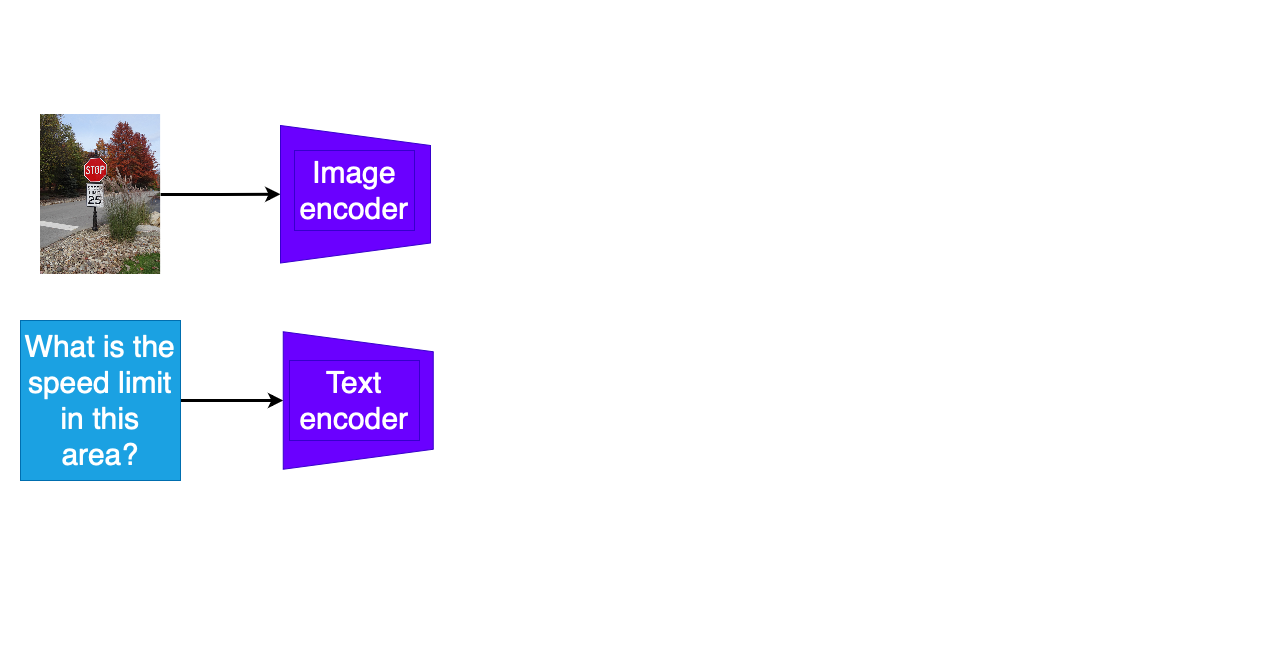
- Losse encodering van vraagtekst en andere modaliteit
Multimodale QA-taken
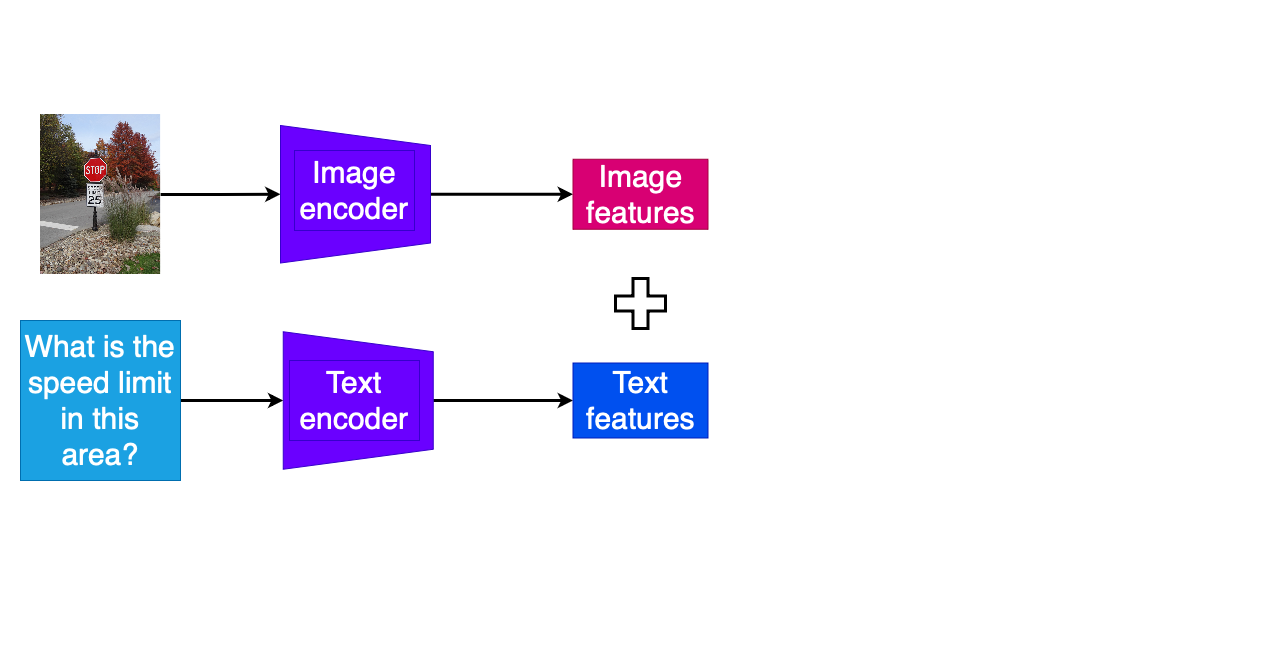
- Losse encodering van vraagtekst en andere modaliteit
- Combinatie van gecodeerde features
Multimodale QA-taken
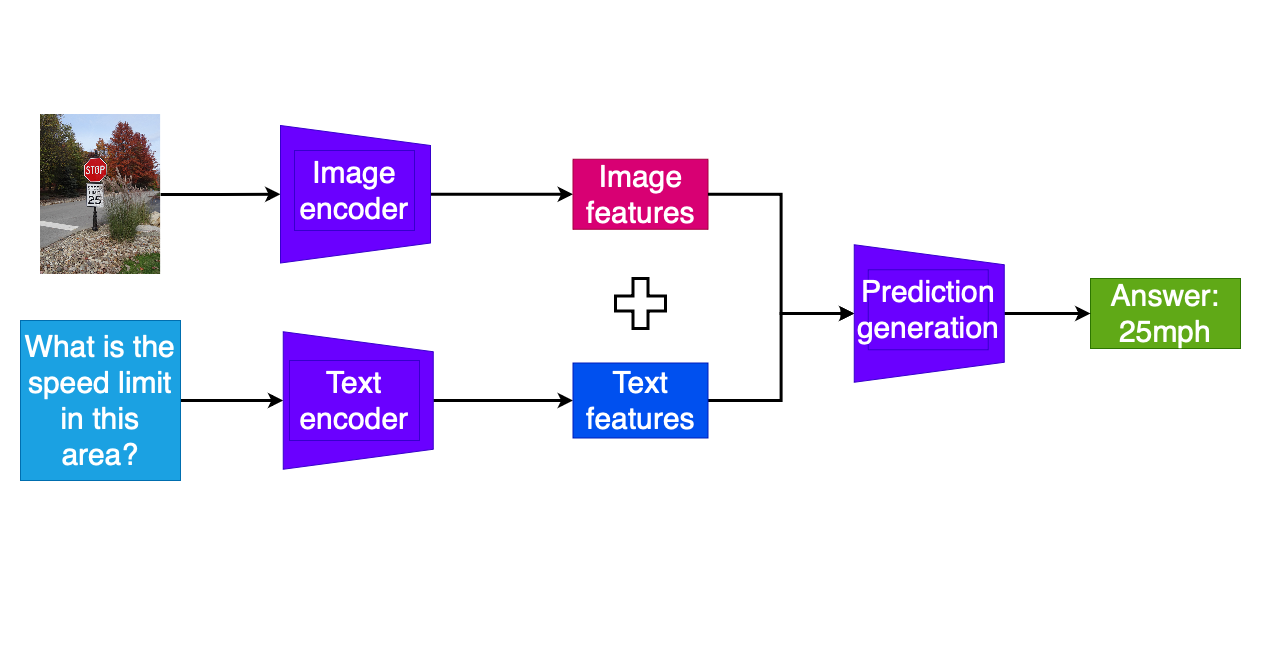
- Losse encodering van vraagtekst en andere modaliteit
- Combinatie van gecodeerde features
- Extra modellagen om antwoordsymbolen te voorspellen
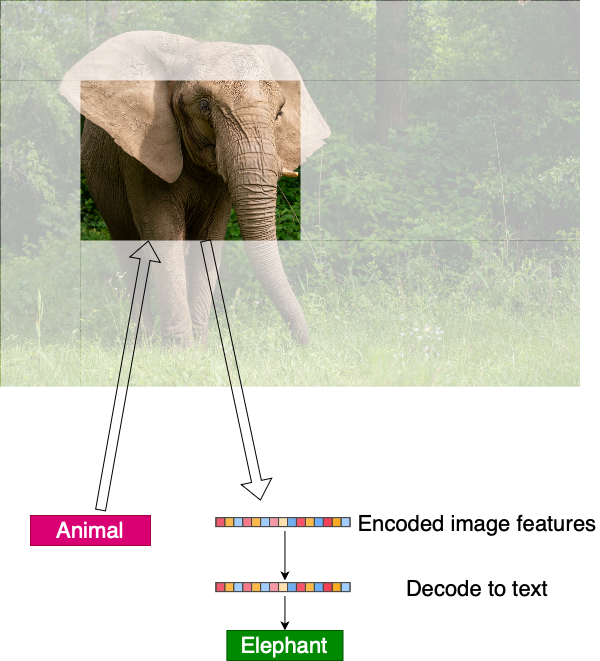
VQA

VQA
Document-VQA
Document-VQA

- Extra afhankelijkheden nodig voor OCR
pytesseractinstalleren viapip- Tesseract OCR via pakketinstaller installer (bijv.
apt-get,exeofhomebrew/macports)

Document-VQA