Fijn afstemmen van text-to-speech-modellen
Multi-modale modellen met Hugging Face

James Chapman
Curriculum Manager, DataCamp
Doel van fijn afstemmen van text-to-speech
Bijv. groot Engels algemeen pretrainingsmodel ⇏ realistische Italiaanse spraak

Doel van fijn afstemmen van text-to-speech
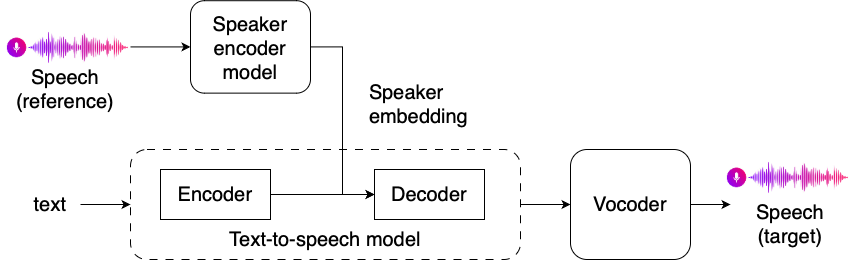
- Speaker embedding + TTS-functies → generatief model
- Nieuwe speaker embeddings zijn op zichzelf niet genoeg zonder fine-tuning
Het nieuwe model gebruiken