Afbeeldingen bewerken met diffusiemodellen
Multi-modale modellen met Hugging Face

James Chapman
Curriculum Manager, DataCamp
Diffusers

- Getraind om ruis naar een afbeelding te mappen
- CLIP + Diffusion → 2 soorten conditionele generatie
- Generatie: tekst → afbeelding
- Modificatie: tekst+afbeelding → afbeelding
1 https://huggingface.co/docs/diffusers
Aangepaste beeldbewerking
ControlNet: voorwaardelijke generatie op basis van beeld en tekst
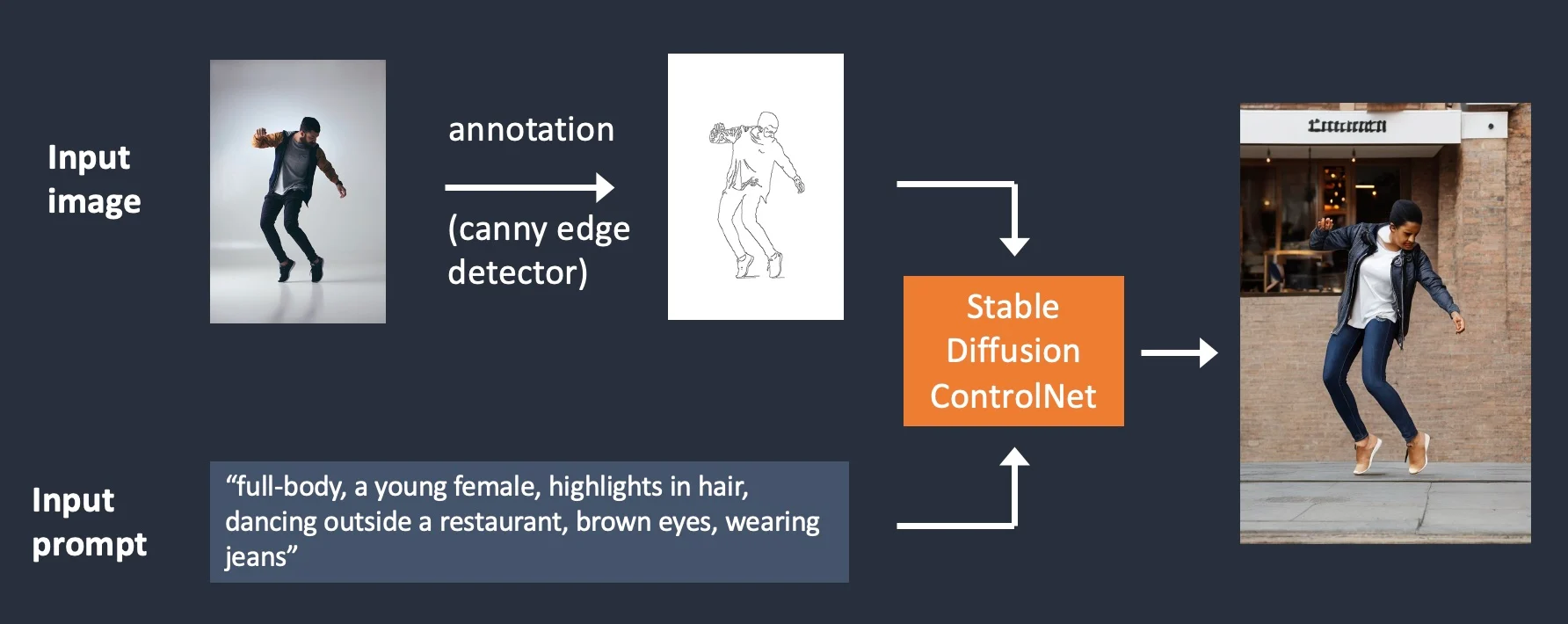
1 https://stable-diffusion-art.com/controlnet/
Aangepaste beeldbewerking

Aangepaste beeldbewerking

Aangepaste beeldbewerking

Image inpainting

Image inpainting

Image inpainting


