Features standaardiseren
CTR voorspellen met Machine Learning in Python

Kevin Huo
Instructor
Data schalen
- Standaardschalen zet alle features op gemiddelde 0 en standaarddeviatie 1
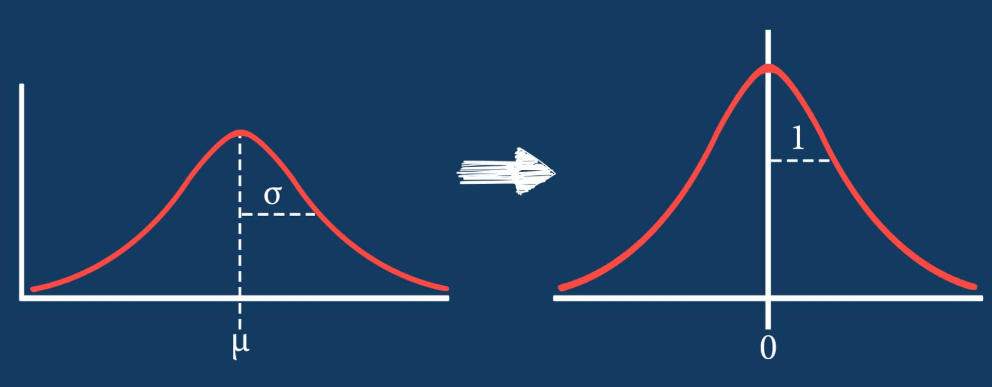
- Meestal een goede praktijk voor machine learning-modellen
CTR voorspellen met Machine Learning in Python
Kevin Huo
Instructor

