TF-IDF-vectorisatie
Natural Language Processing (NLP) in Python

Fouad Trad
Machine Learning Engineer
Van BoW naar TF-IDF
- BoW behandelt alle woorden als even belangrijk
- TF-IDF lost dit op door aan te geven:
- hoe vaak een woord in een document voorkomt
- hoe informatief dat woord is over de collectie

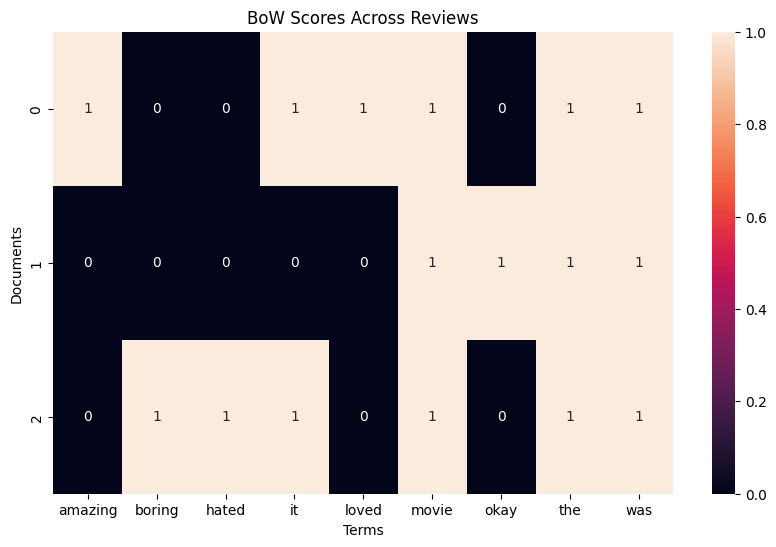
TF-IDF

TF-IDF
- TF: Term Frequency
- Hoe vaak een woord in een document voorkomt
TF-IDF
- TF: Term Frequency
- Hoe vaak een woord in een document voorkomt
- IDF: Inverse Document Frequency
- Hoe zeldzaam dat woord is over alle documenten
- Woord staat in één document, niet in anderen → hoge score
- Woord staat in elk document → lage score
Scores visualiseren als heatmap
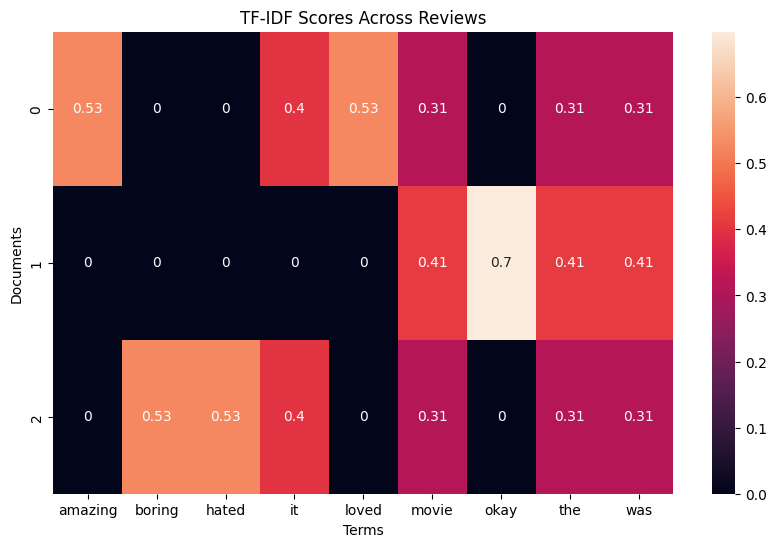
Vergelijking met BoW