Embeddings
Natural Language Processing (NLP) in Python

Fouad Trad
Machine Learning Engineer
Beperkingen van BoW en TF-IDF
- Soortgelijke woorden als losstaand zien
- Betekenis van tekst niet vatten

Embeddings
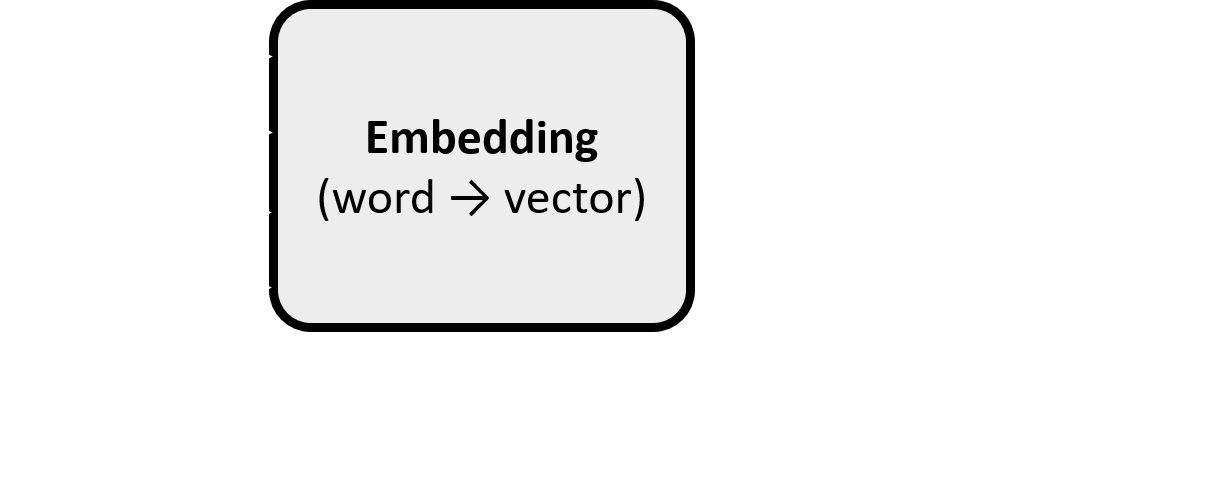
- Stel een woord voor met een vector die de betekenis vangt
Embeddings
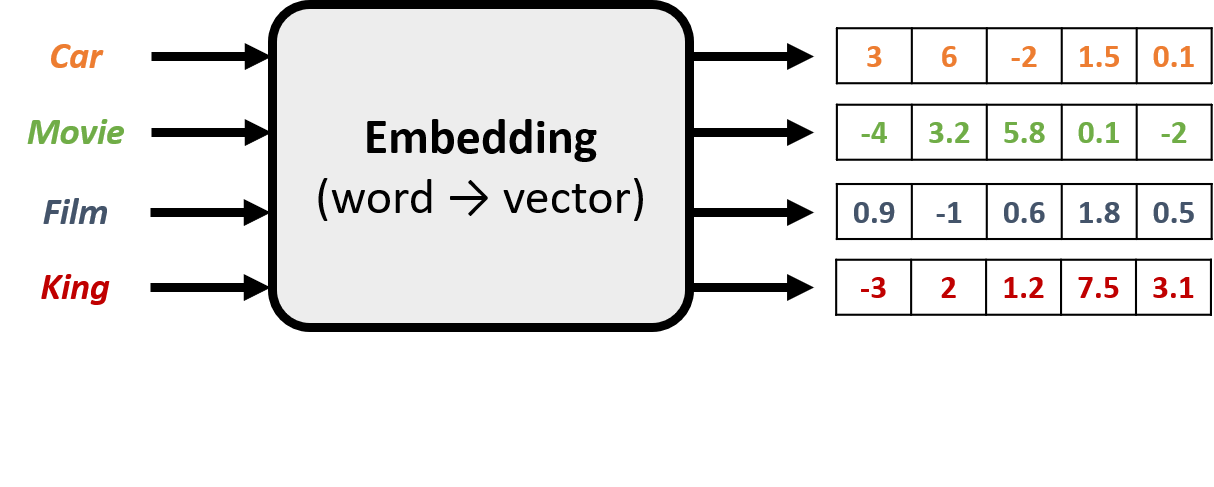
- Stel een woord voor met een vector die de betekenis vangt
- Wijs willekeurige waarden toe aan elk woord
Embeddings

- Stel een woord voor met een vector die de betekenis vangt
- Wijs willekeurige waarden toe aan elk woord
- Verfijn waarden door ontbrekende woorden in zinnen te voorspellen
Embeddings
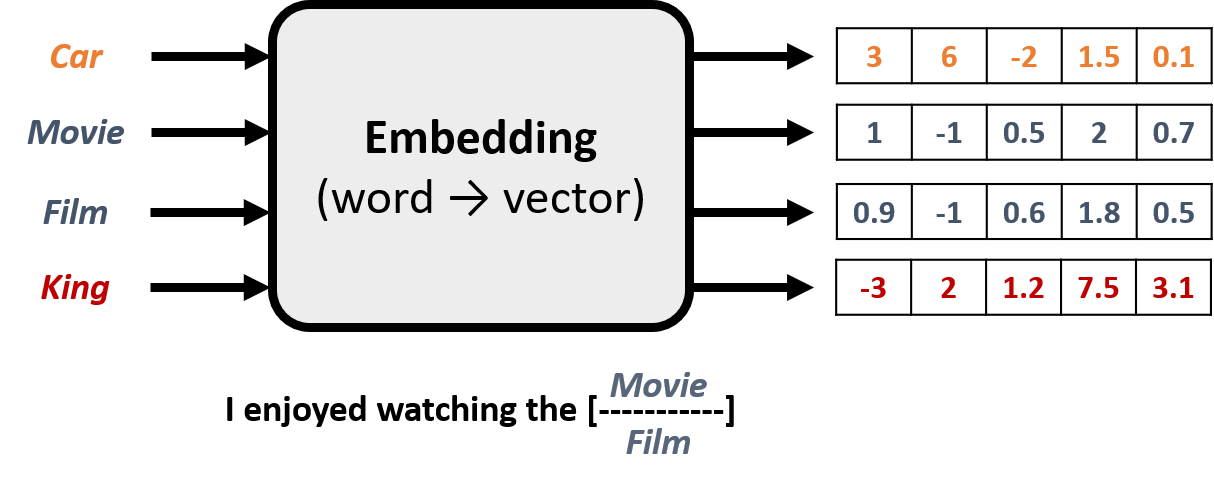
- Stel een woord voor met een vector die de betekenis vangt
- Wijs willekeurige waarden toe aan elk woord
- Verfijn waarden door ontbrekende woorden in zinnen te voorspellen
- Woorden in vergelijkbare contexten krijgen vergelijkbare representaties
Embeddings als GPS-coördinaten voor woorden
Gensim
![]()
Embeddings visualiseren
- Principal Component Analysis (PCA):
- Hoogdimensionale vectoren → 2D- of 3D-vectoren

1 Afbeelding gegenereerd door DALL-E
Embeddings visualiseren met PCA
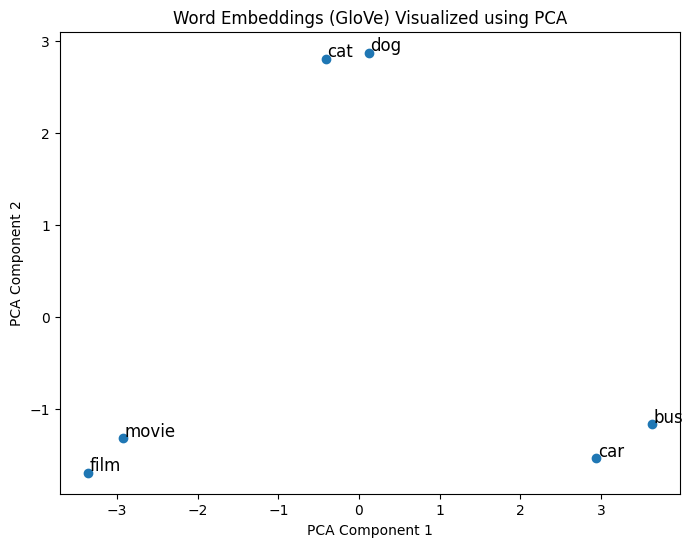
Vergelijking van embeddings
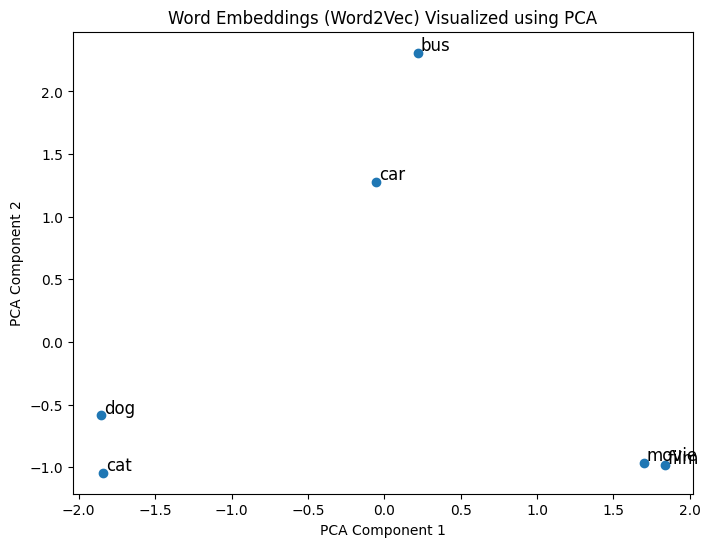
word2vec-google-news-300
glove-wiki-gigaword-50

