Bag-of-Words-representatie
Natural Language Processing (NLP) in Python

Fouad Trad
Machine Learning Engineer
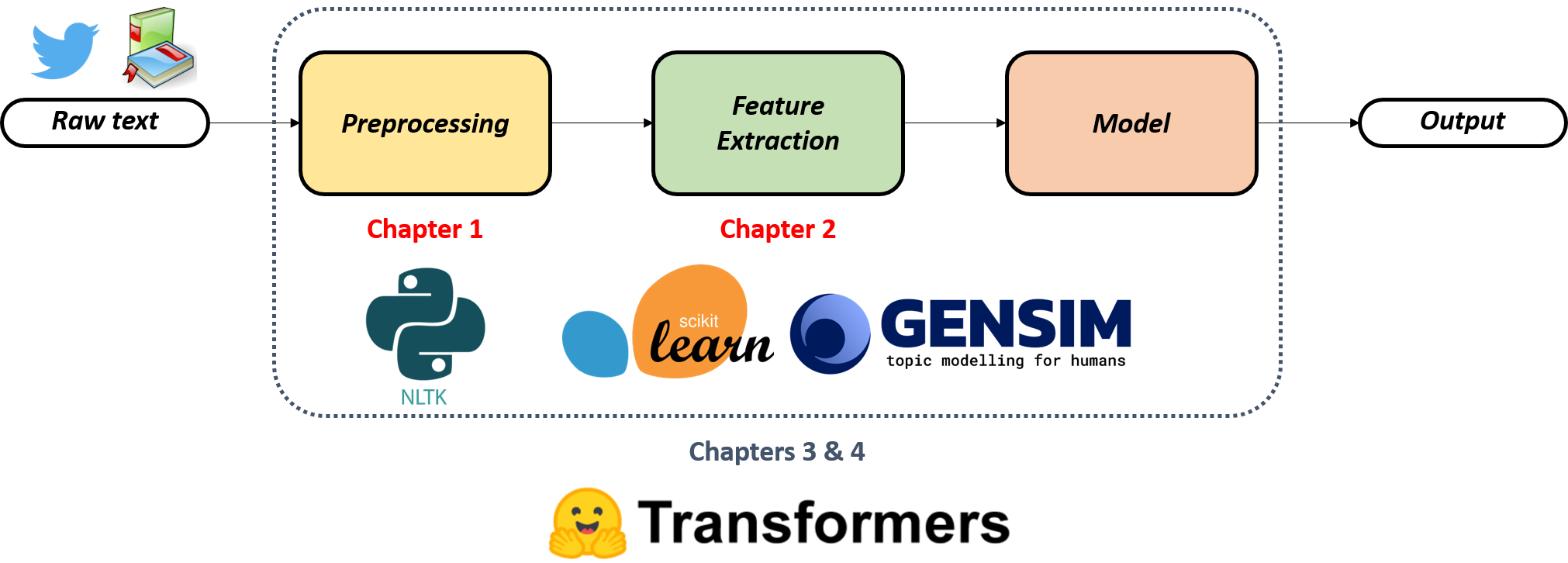
NLP-workflow: terugblik
Bag-of-Words (BoW)
- Basistechniek om tekst als getallen weer te geven
- Stel tekst voor door te tellen hoe vaak elk woord voorkomt
- Gooi woorden in een ‘zak’ en tel ze
- Negeert grammatica en volgorde

BoW-voorbeeld

BoW-voorbeeld
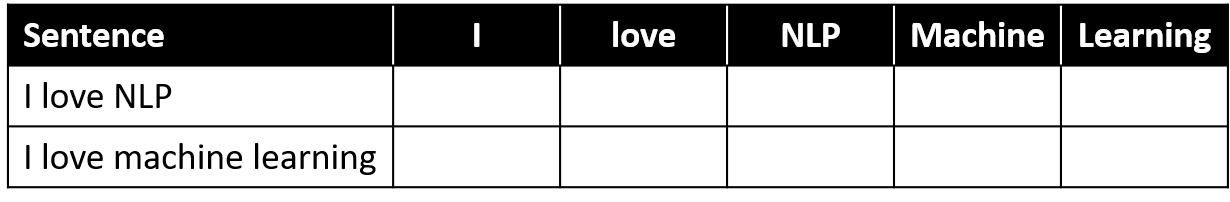
- Bouw een vocabulaire van alle unieke woorden
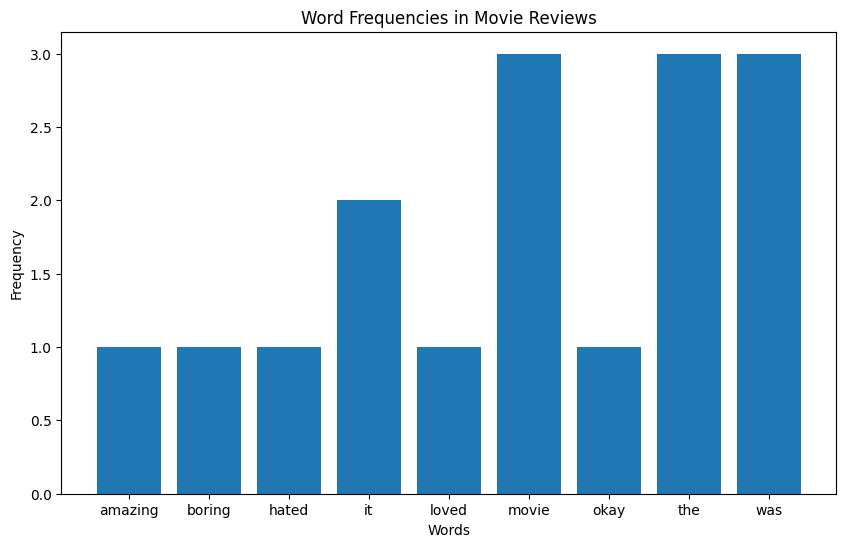
BoW-voorbeeld

- Bouw een vocabulaire van alle unieke woorden
- Tel hoe vaak elk woord uit het vocabulaire voorkomt
Woordfrequenties