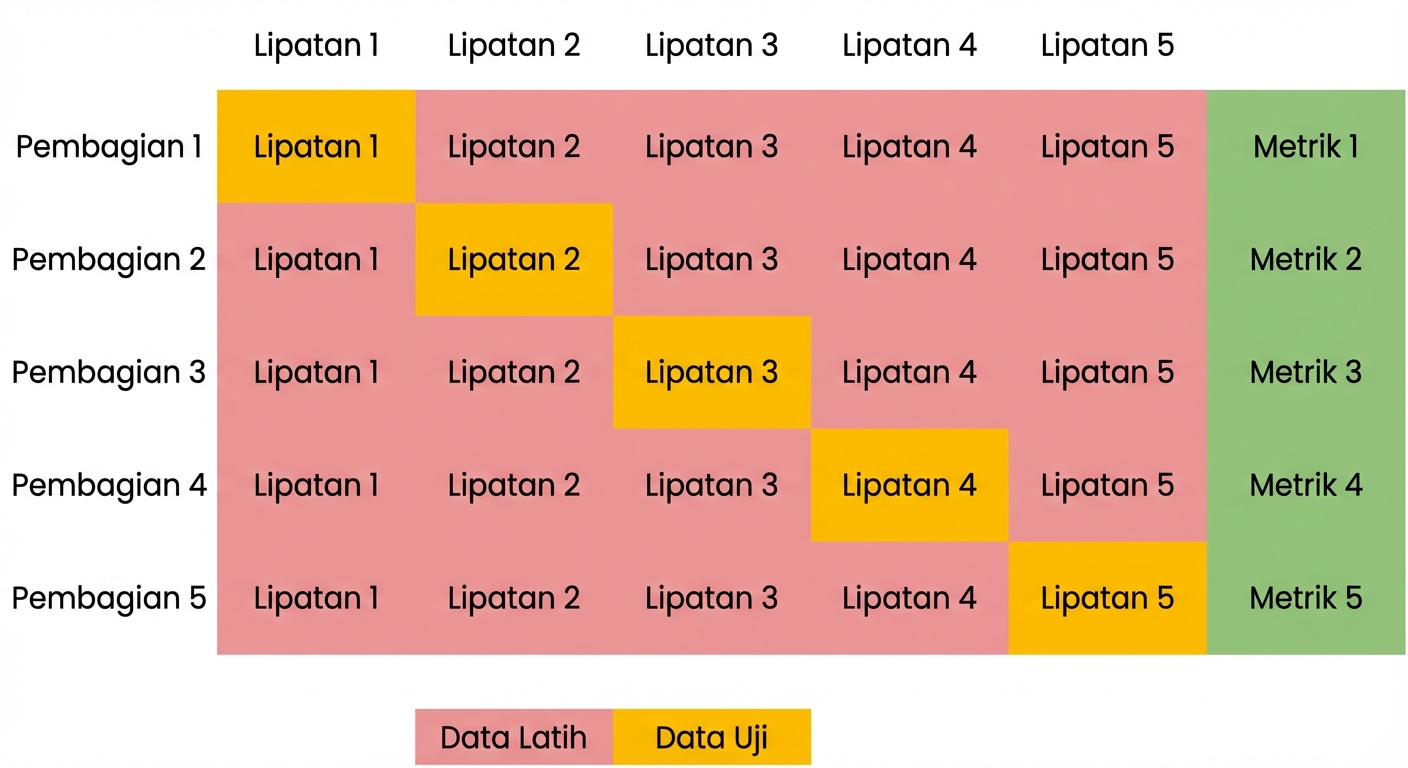
Validasi silang
Supervised Learning dengan scikit-learn

George Boorman
Core Curriculum Manager, DataCamp
Dasar validasi silang

Dasar validasi silang
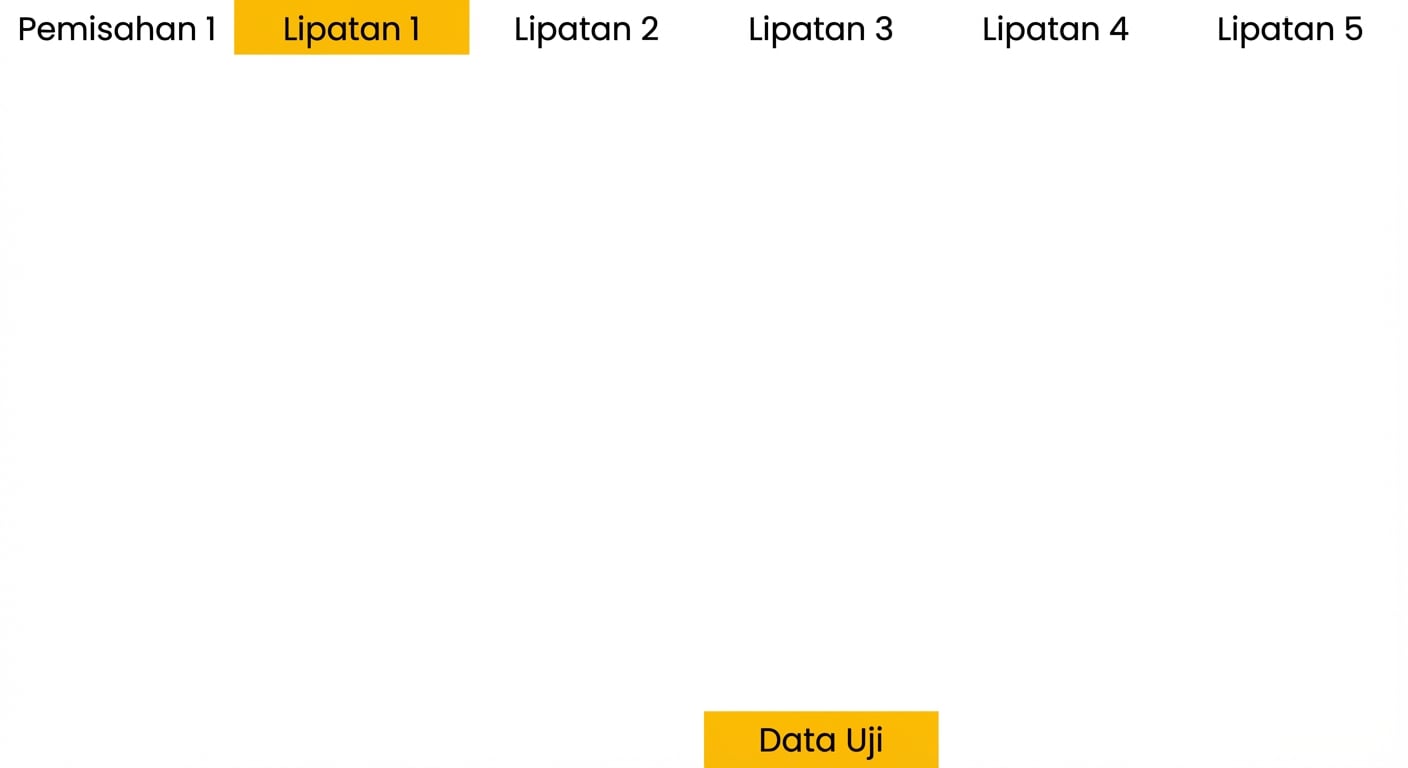
Dasar validasi silang
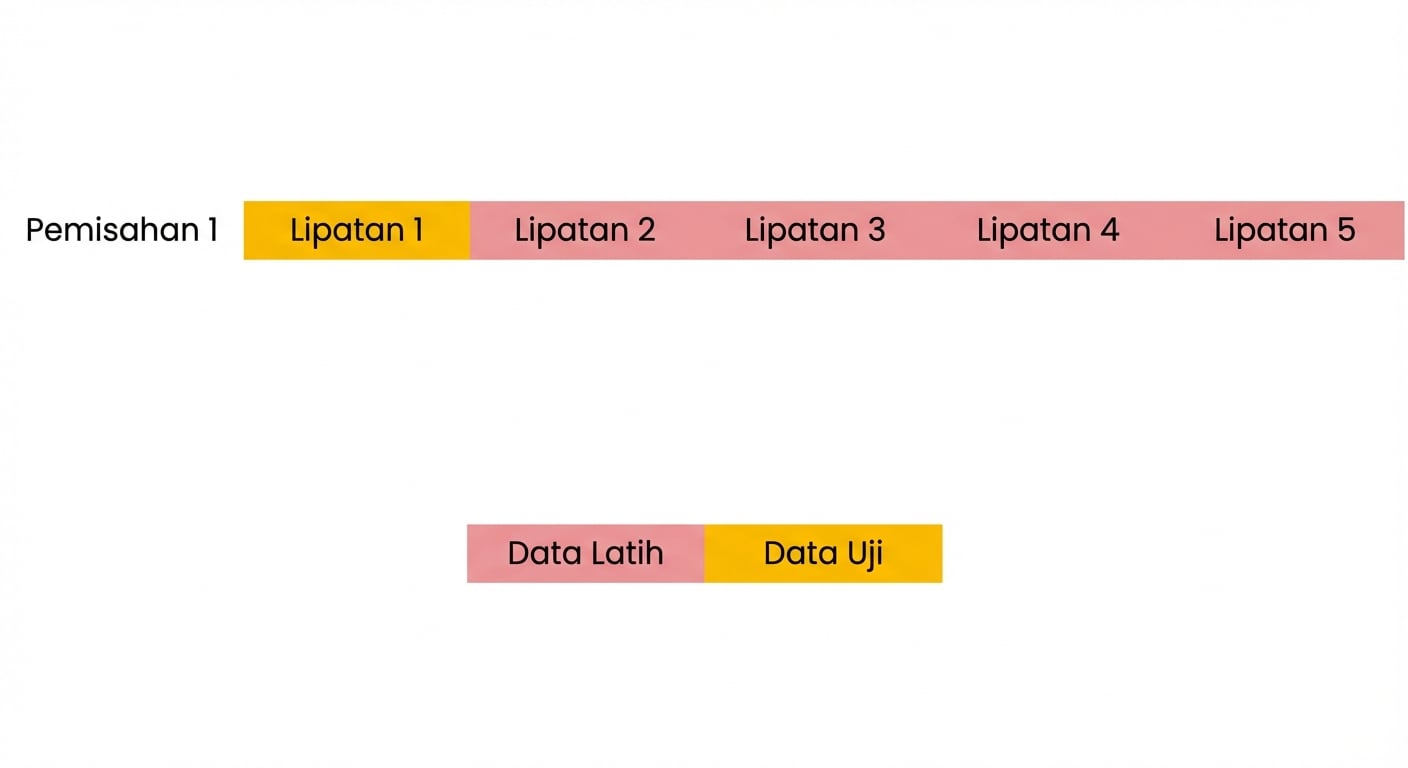
Dasar validasi silang
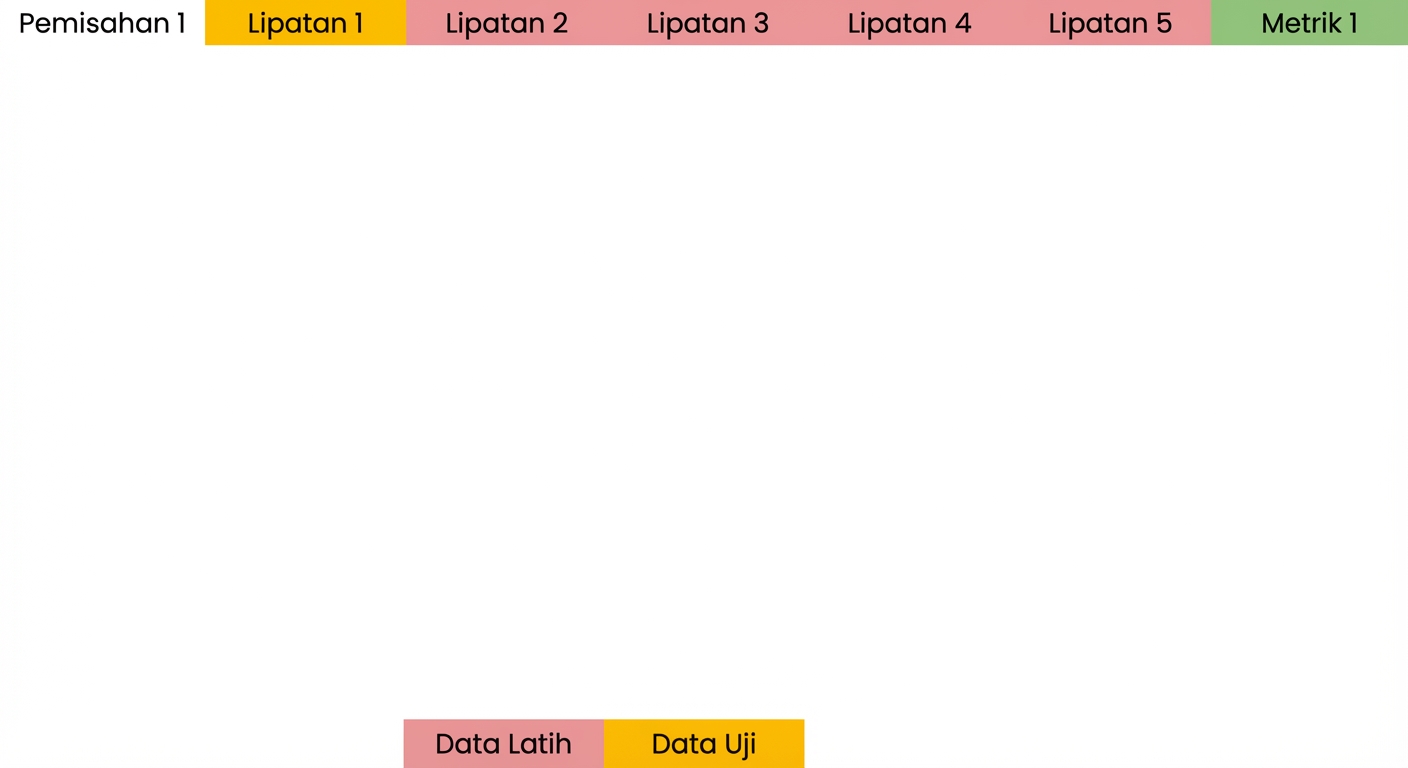
Dasar validasi silang

Dasar validasi silang
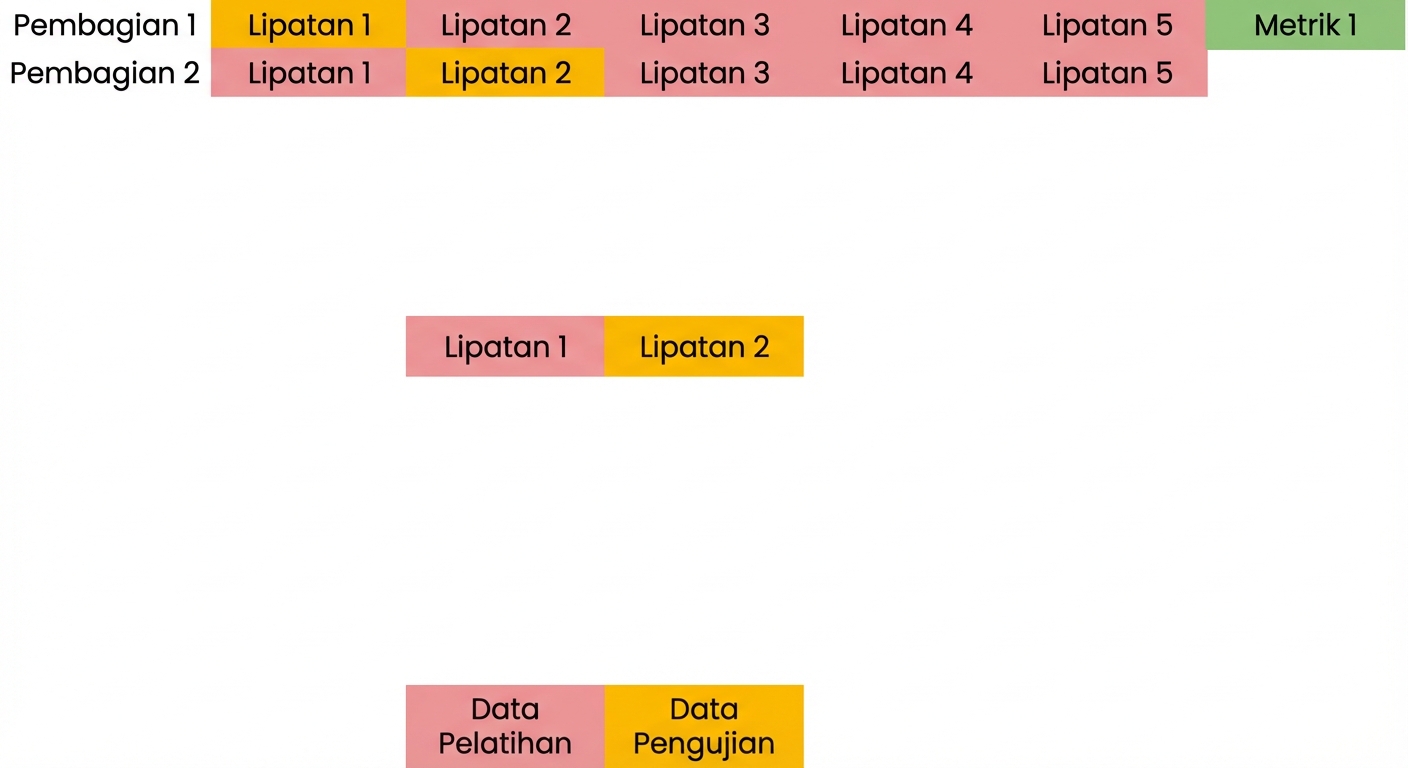
Dasar validasi silang
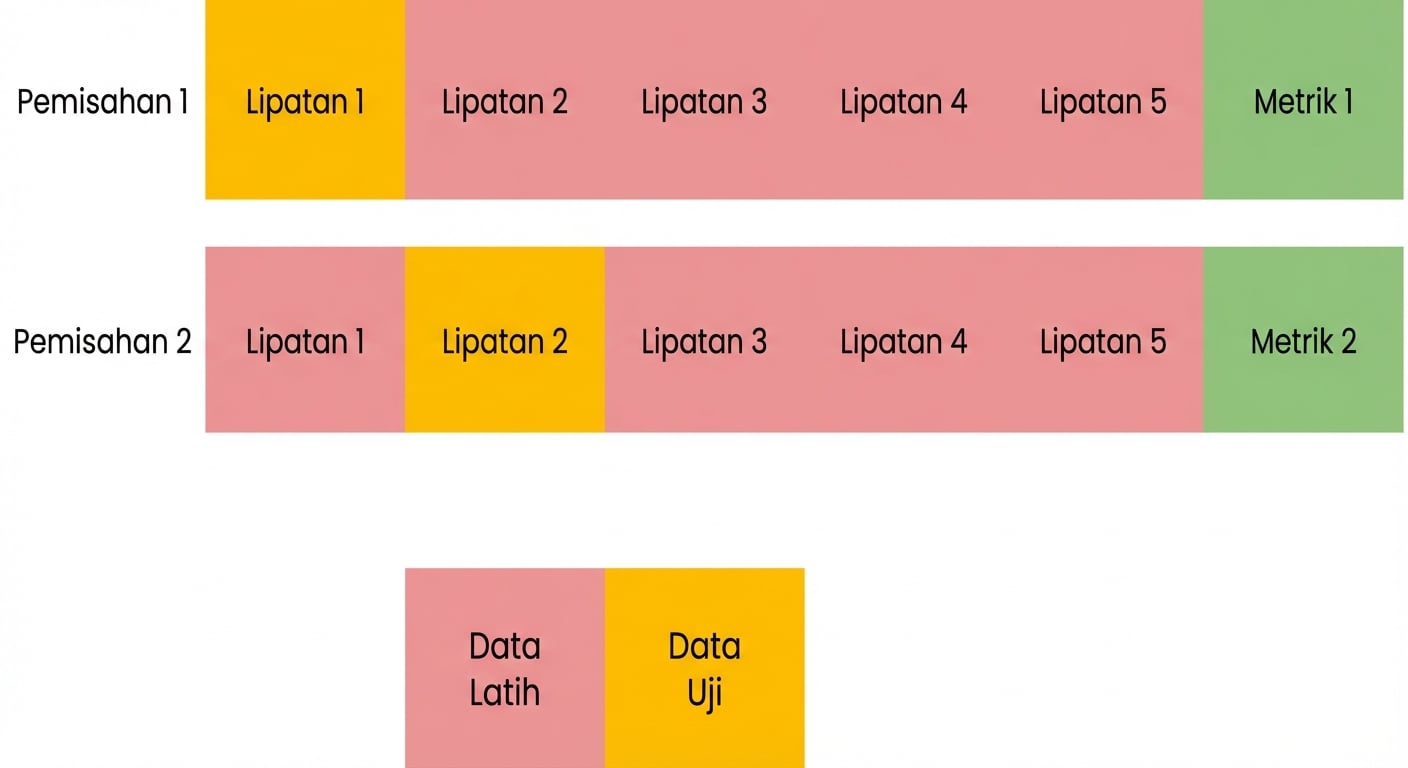
Dasar validasi silang
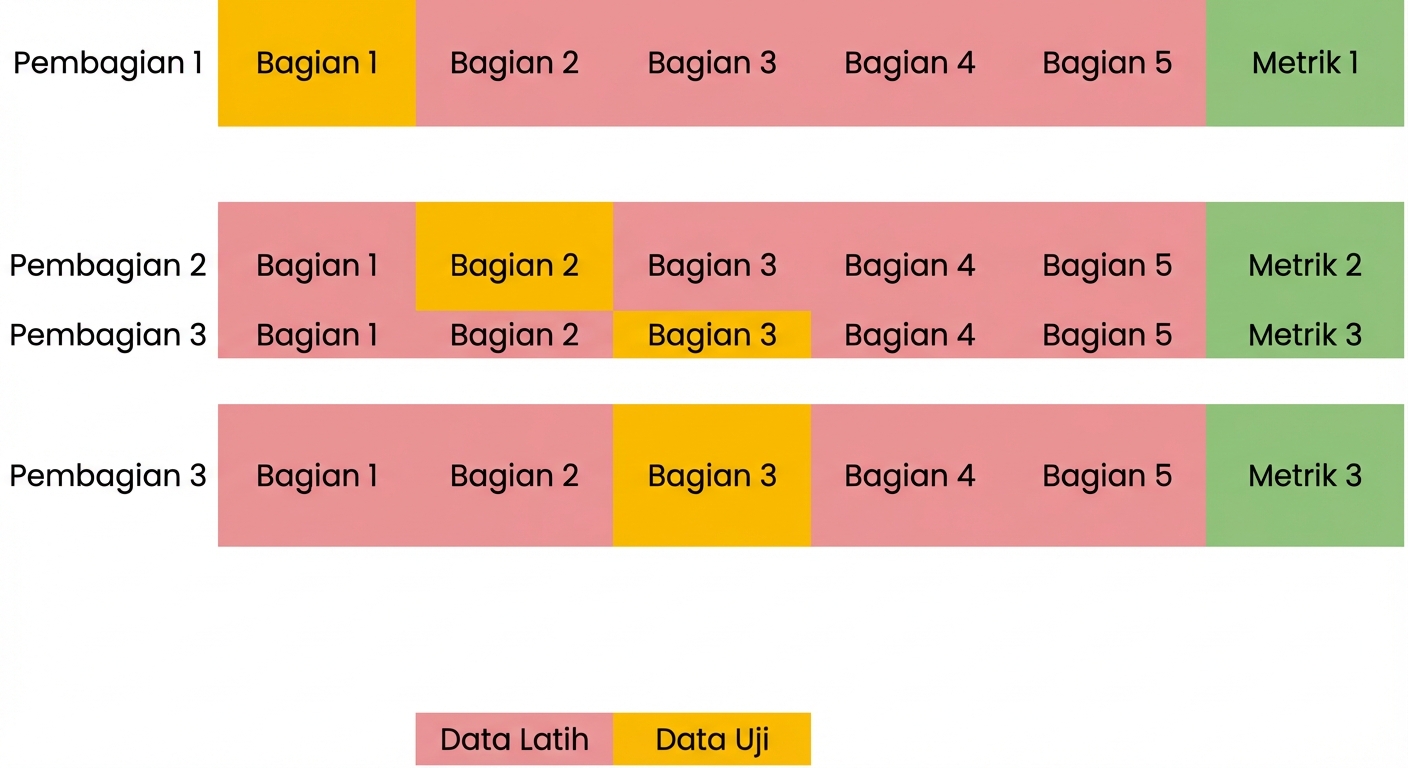
Dasar validasi silang
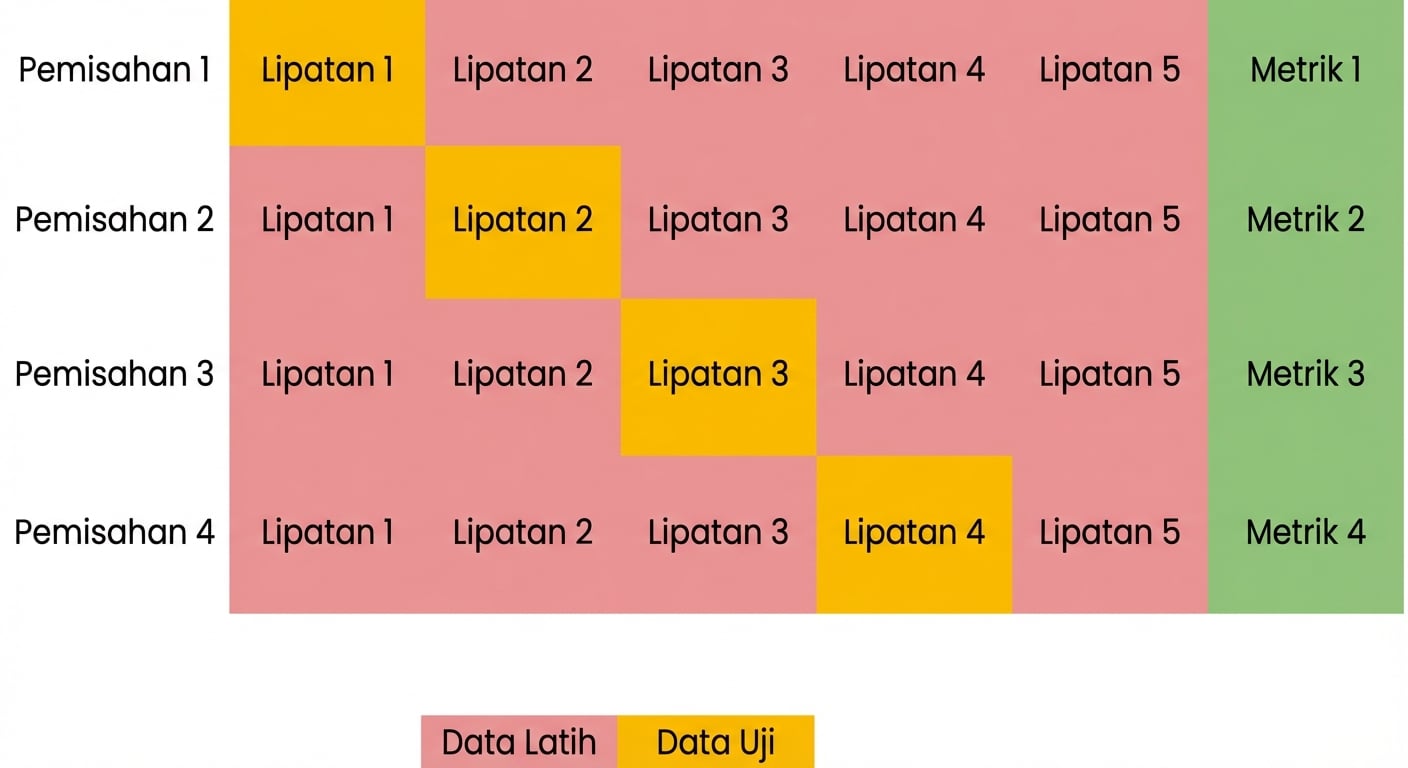
Dasar validasi silang