Laju belajar dan momentum
Pengantar Deep Learning dengan PyTorch

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
Dampak laju belajar: laju optimal
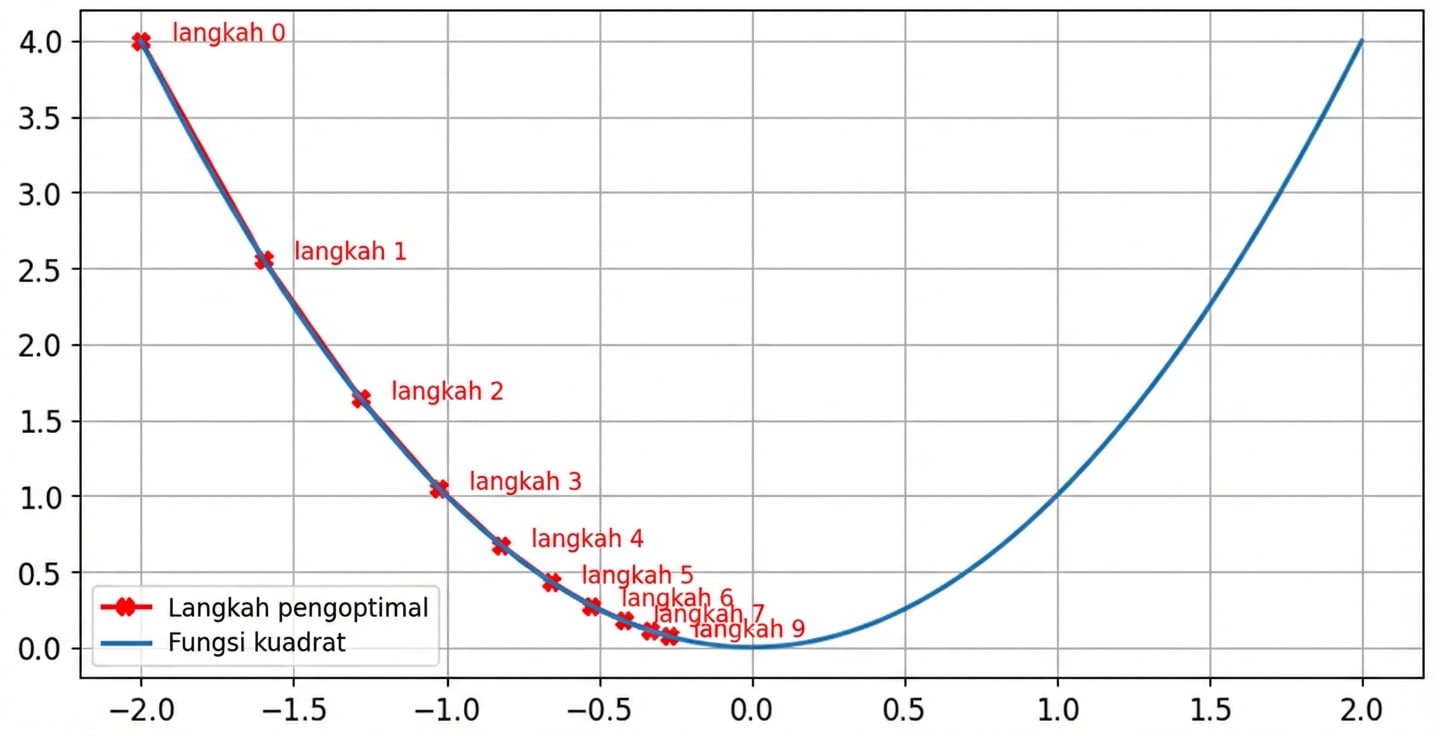
- Ukuran langkah mengecil dekat nol saat gradien mengecil
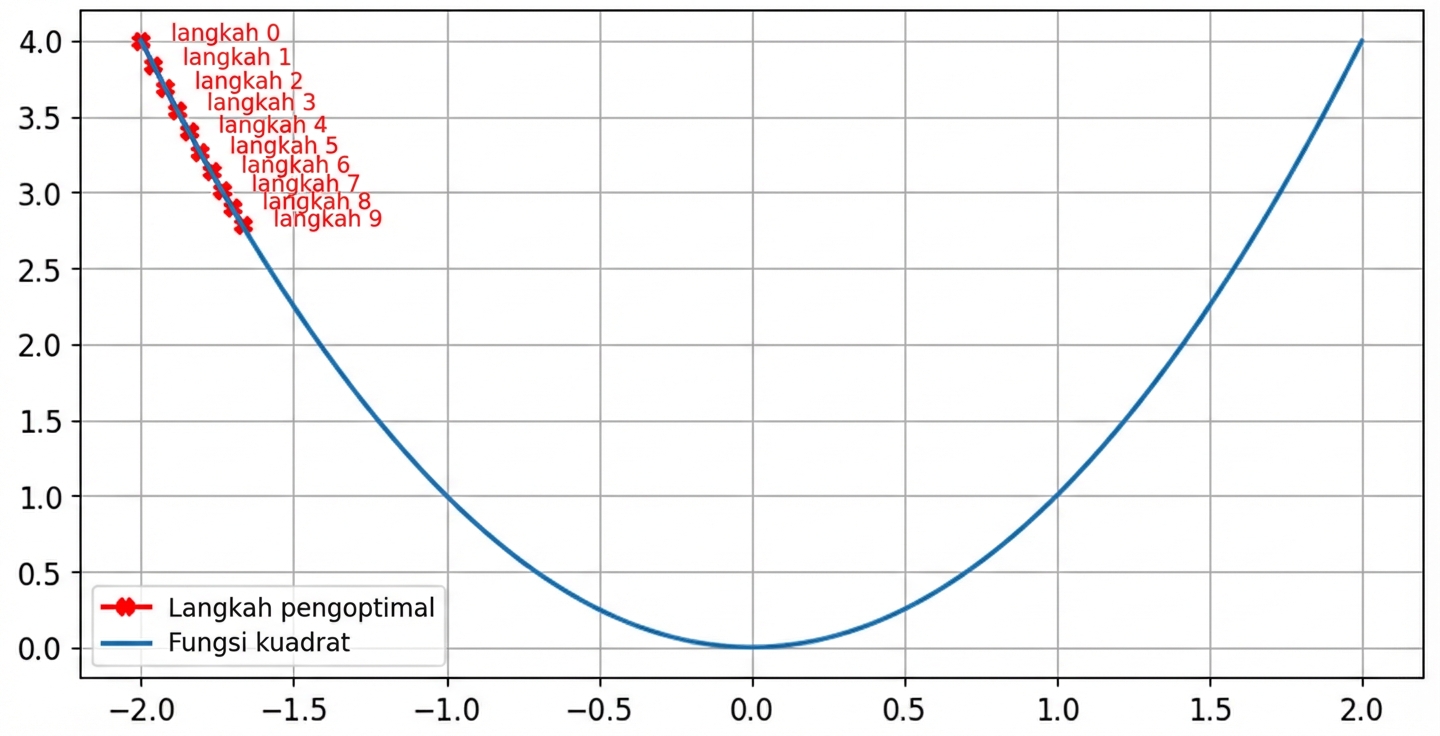
Dampak laju belajar: laju kecil
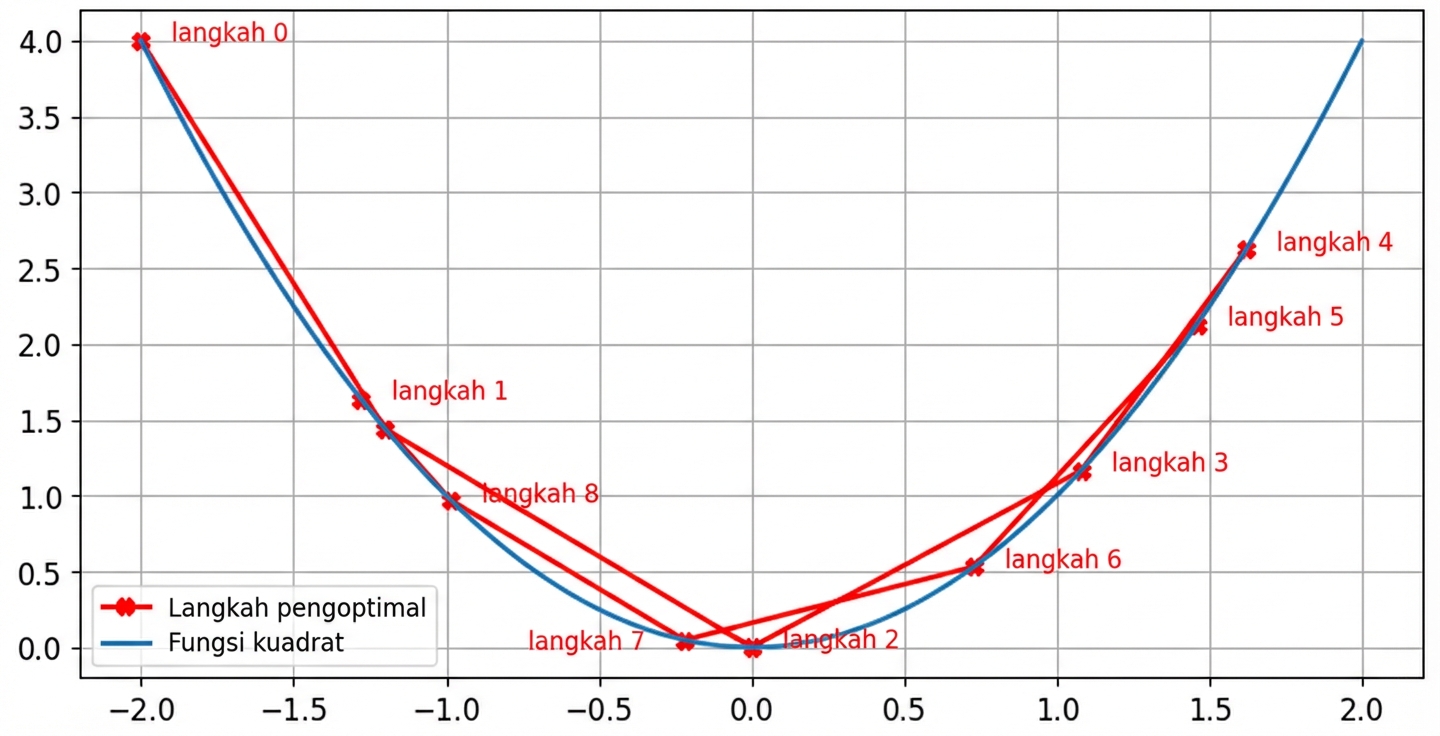
Dampak laju belajar: laju tinggi
Fungsi konveks dan non-konveks
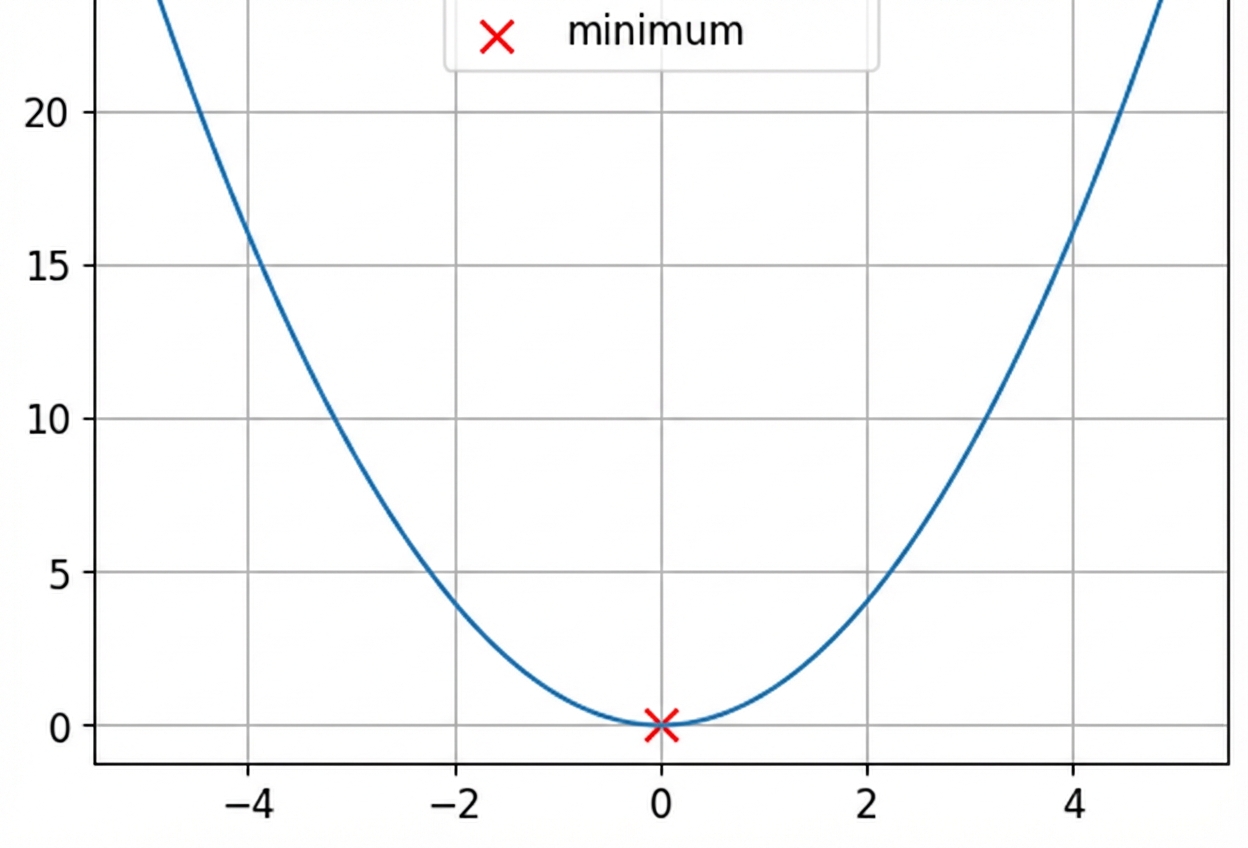
Ini adalah fungsi konveks.
Ini adalah fungsi non-konveks.
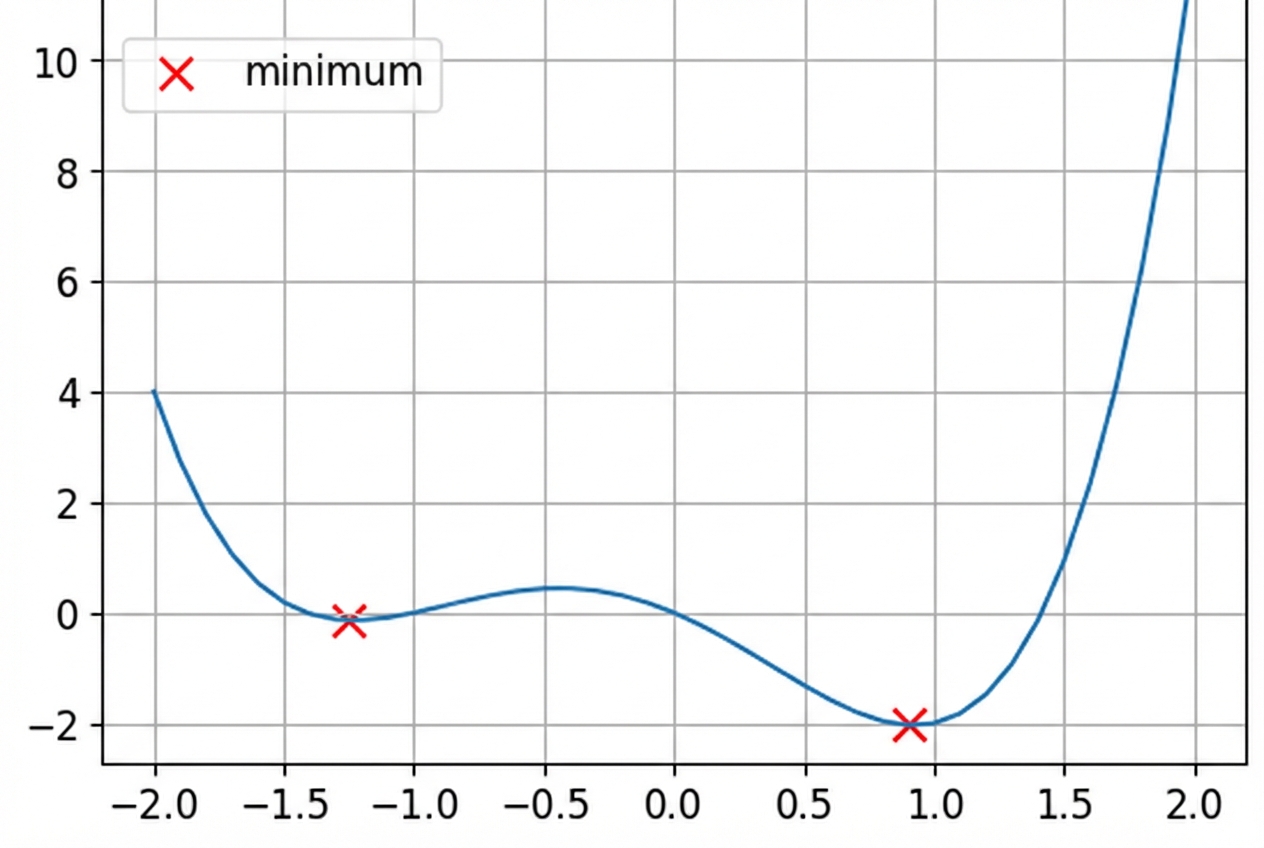
- Fungsi loss bersifat non-konveks
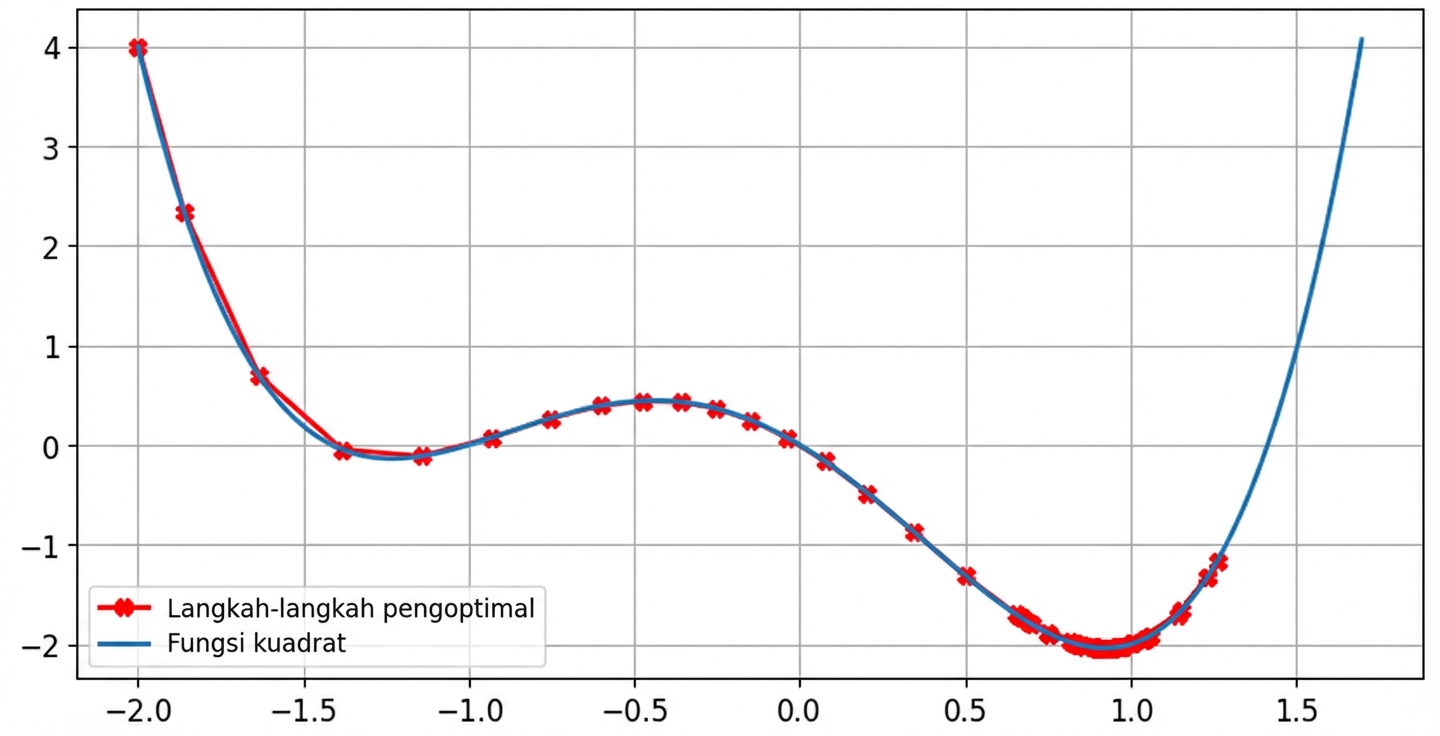
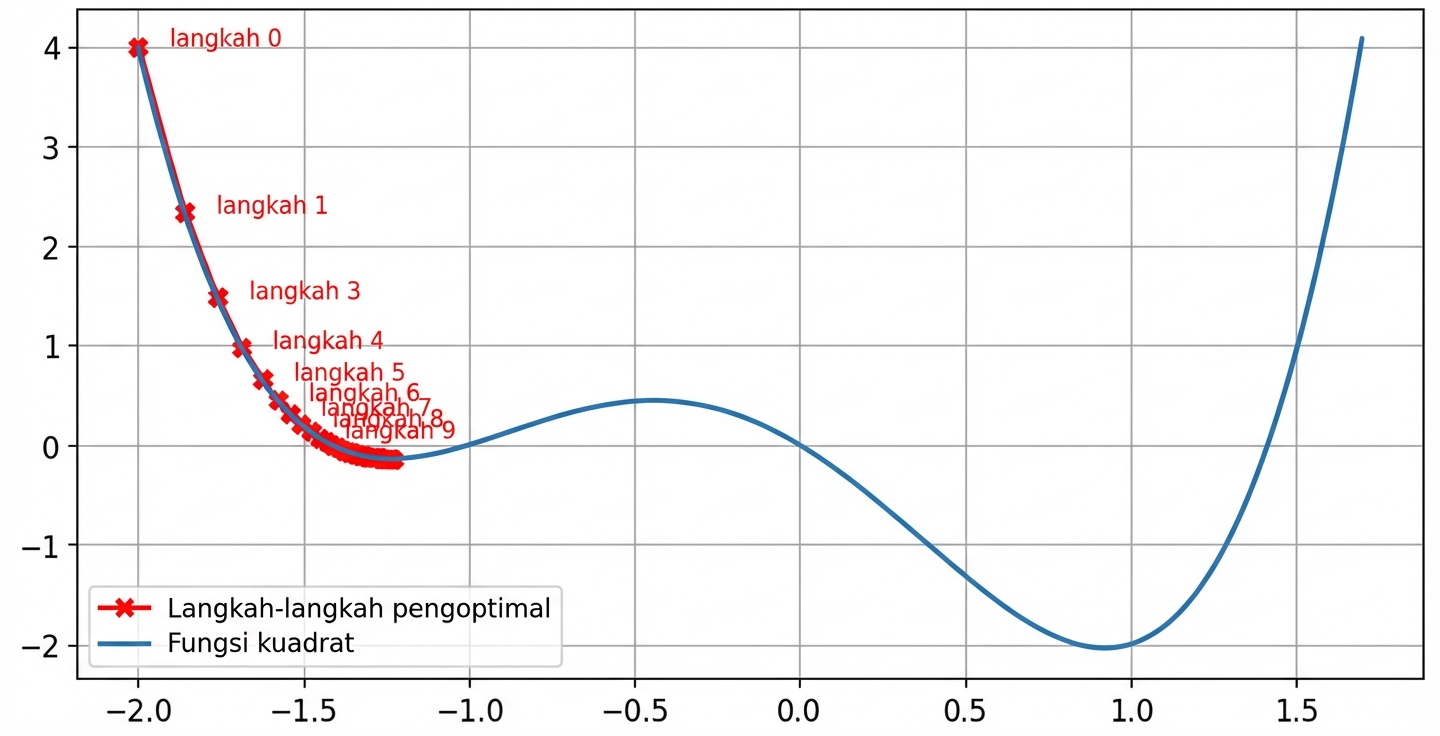
Tanpa momentum
lr = 0.01momentum = 0, setelah 100 langkah minimum ditemukan padax = -1.23dany = -0.14
Dengan momentum
lr = 0.01momentum = 0.9, setelah 100 langkah minimum ditemukan padax = 0.92dany = -2.04