Teorema limit pusat
Pengantar Statistika di Python

Maggie Matsui
Content Developer, DataCamp
Melempar dadu 5 kali

Distribusi penarikan
Distribusi penarikan dari rerata sampel
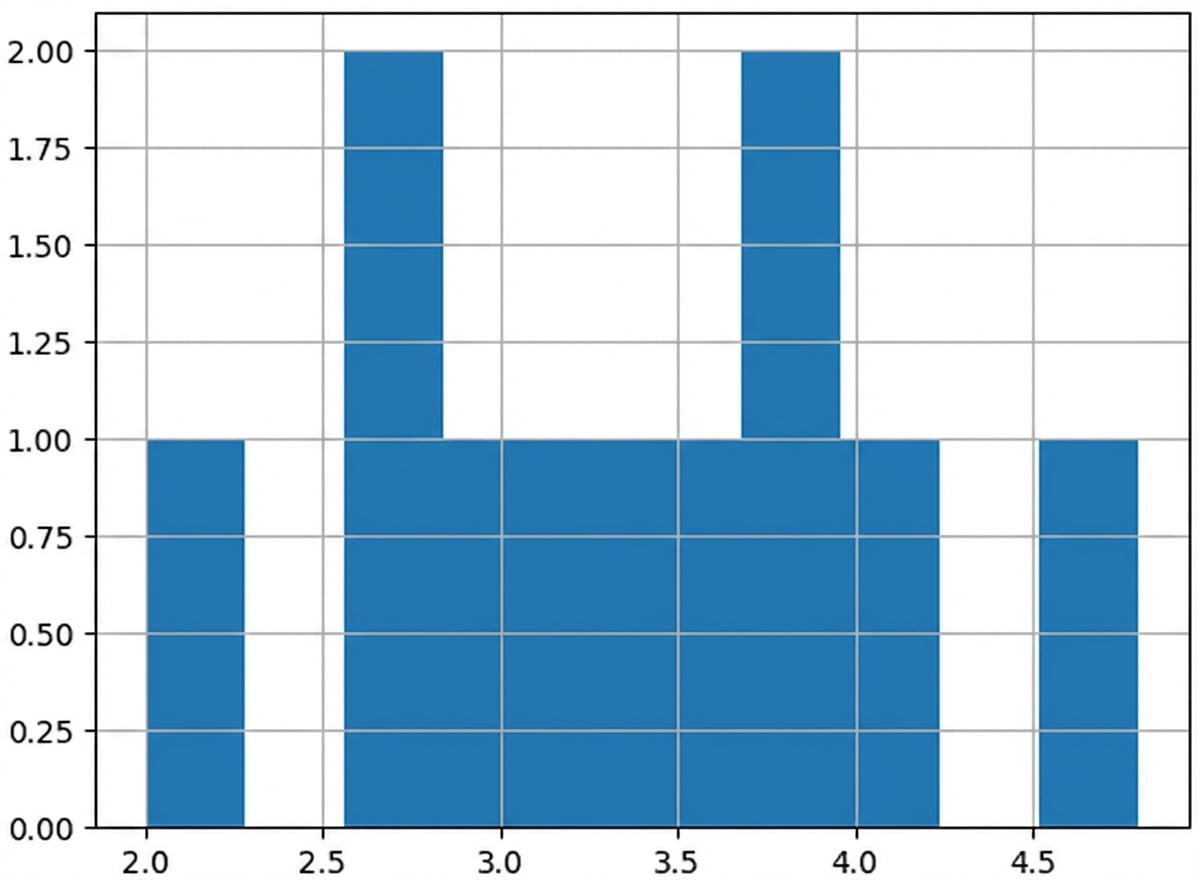
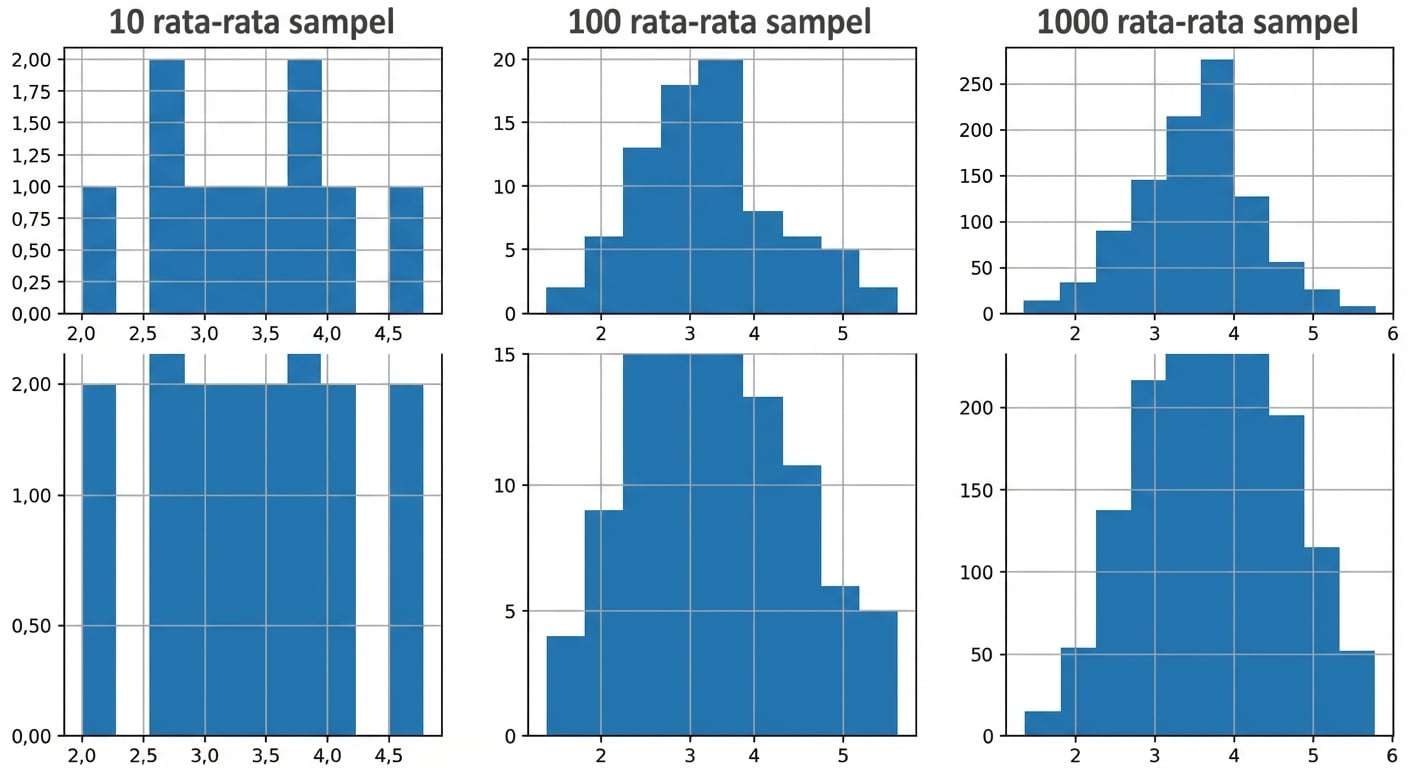
100 rerata sampel
sample_means = []
for i in range(100):
sample_means.append(np.mean(die.sample(5, replace=True)))
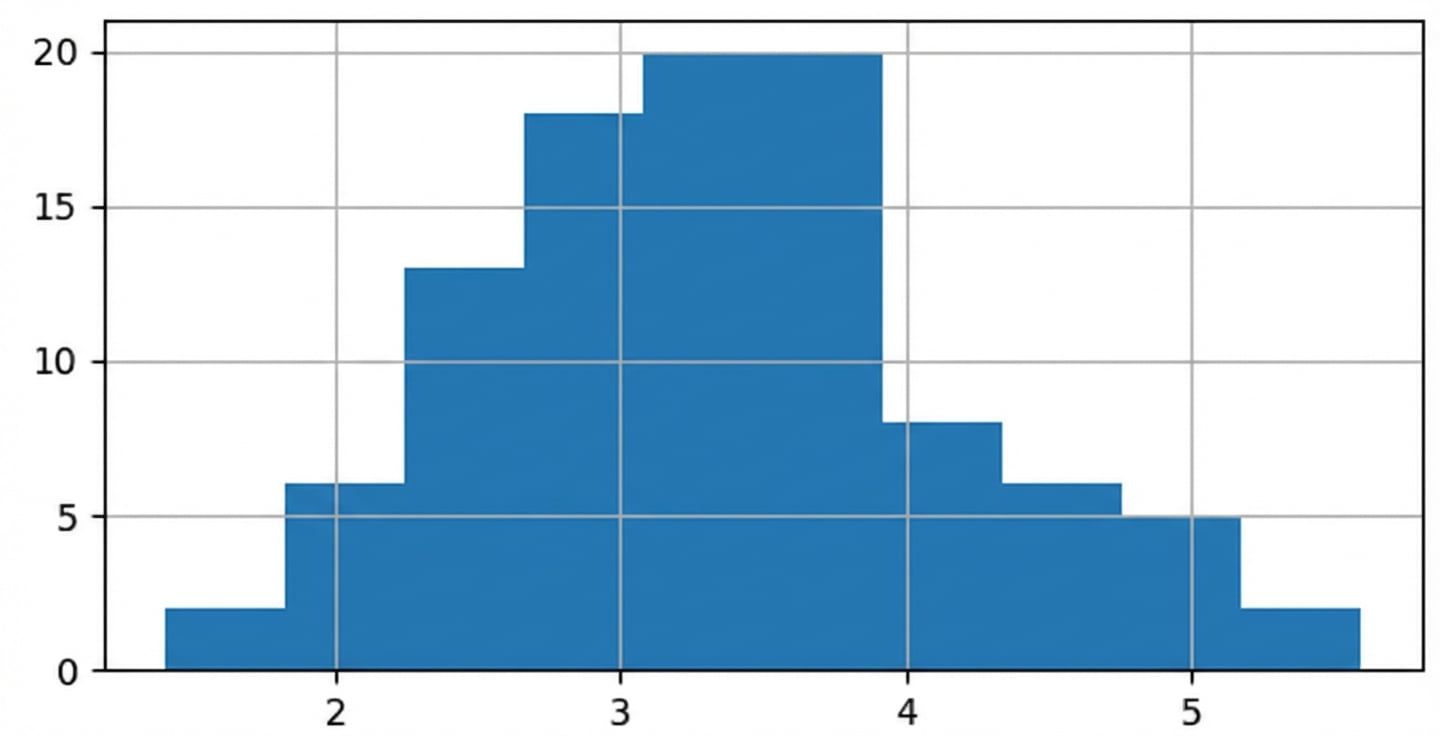
1000 rerata sampel
sample_means = []
for i in range(1000):
sample_means.append(np.mean(die.sample(5, replace=True)))
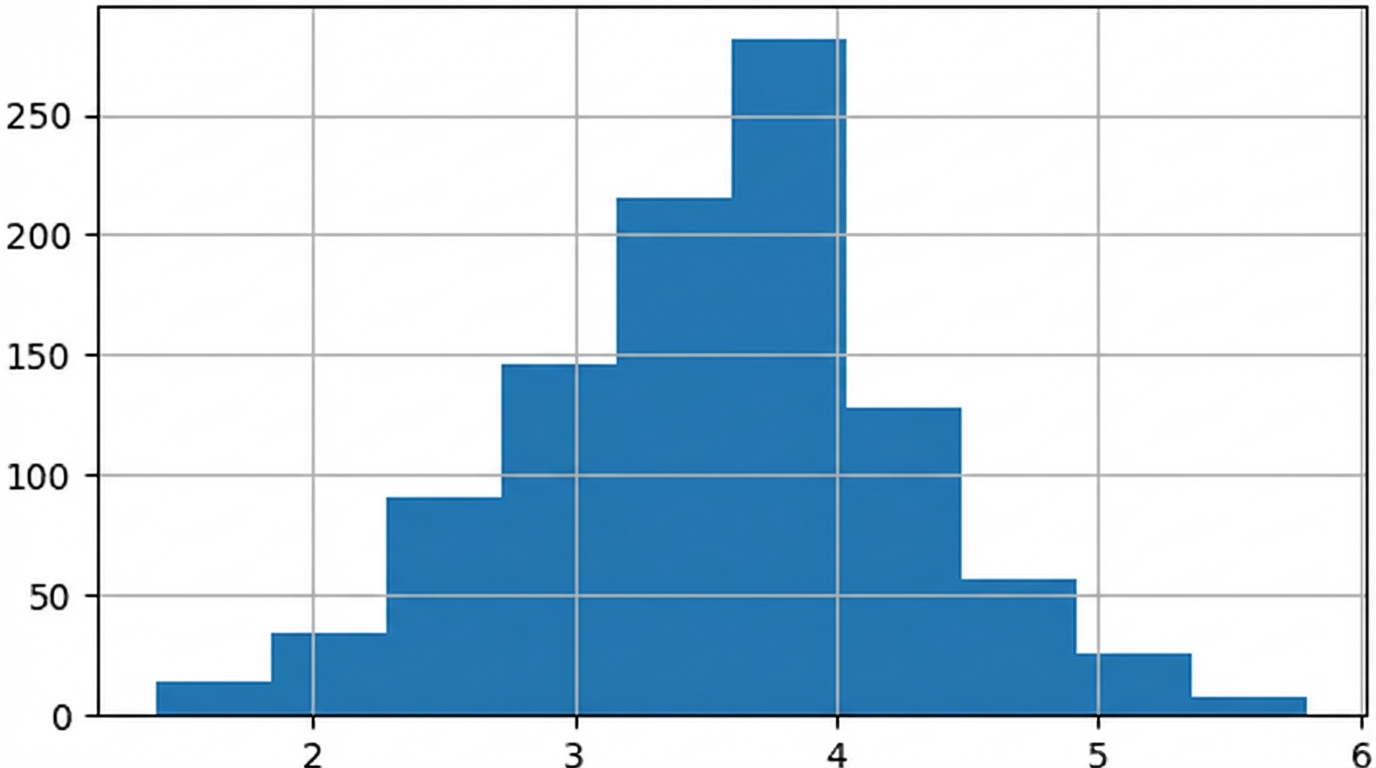
Teorema limit pusat
Distribusi penarikan suatu statistik makin mendekati distribusi normal saat jumlah percobaan meningkat.
* Sampel harus acak dan independen
Simpangan baku dan TLP
sample_sds = []
for i in range(1000):
sample_sds.append(np.std(die.sample(5, replace=True)))
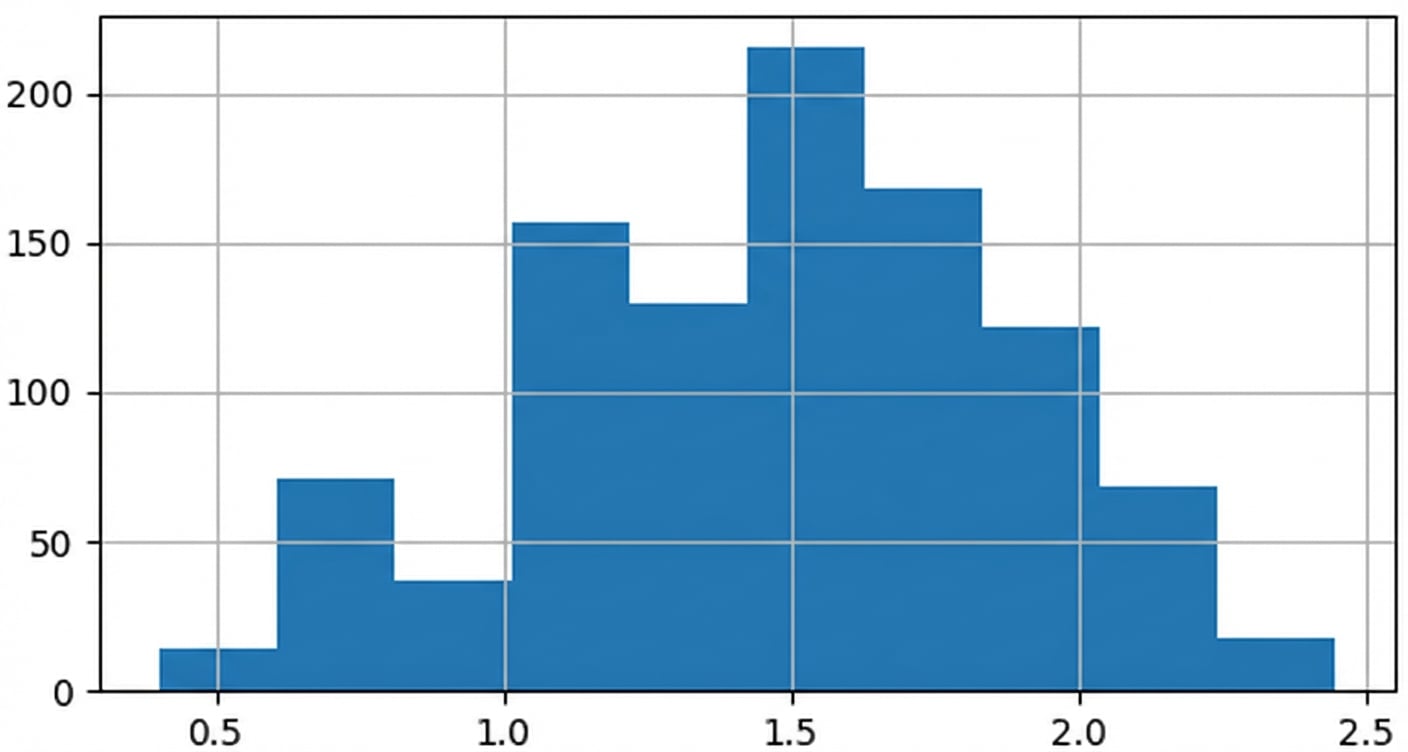
Distribusi penarikan proporsi
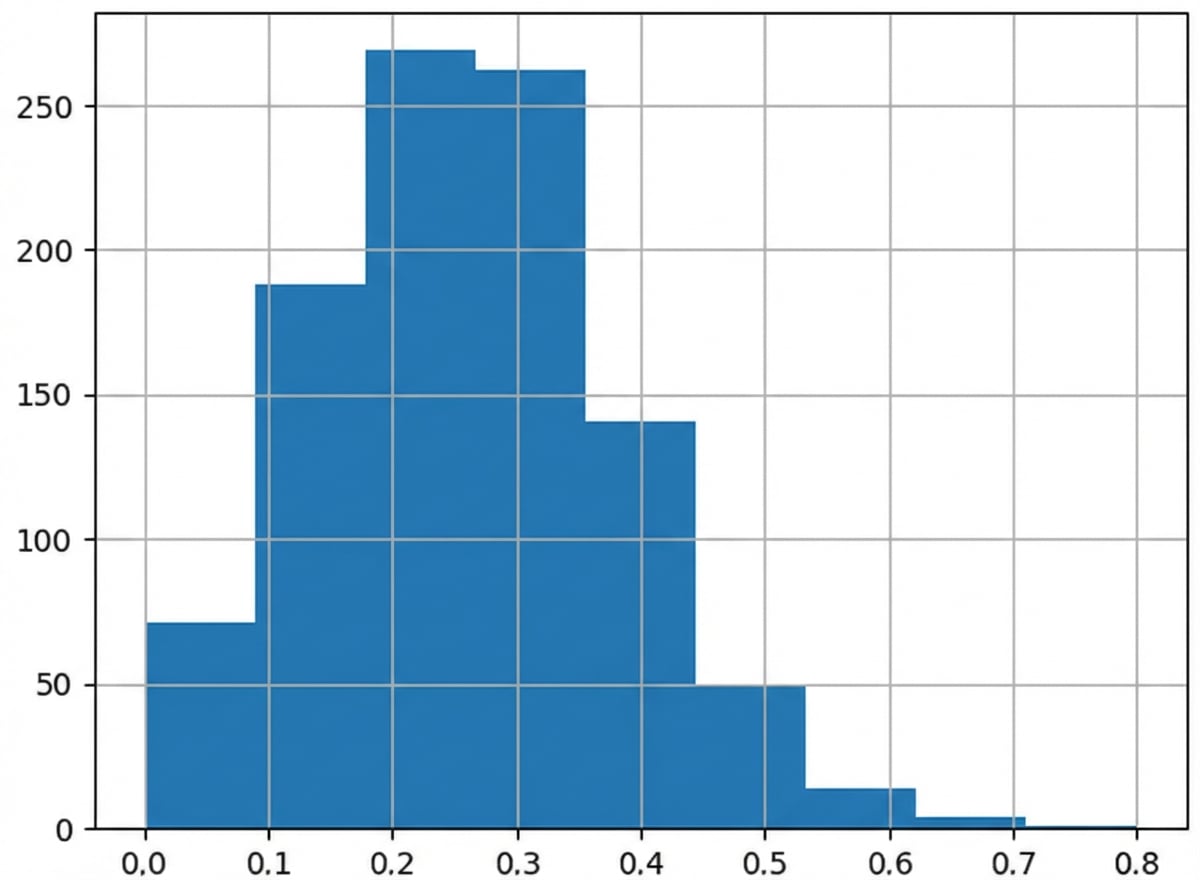
Rerata distribusi penarikan
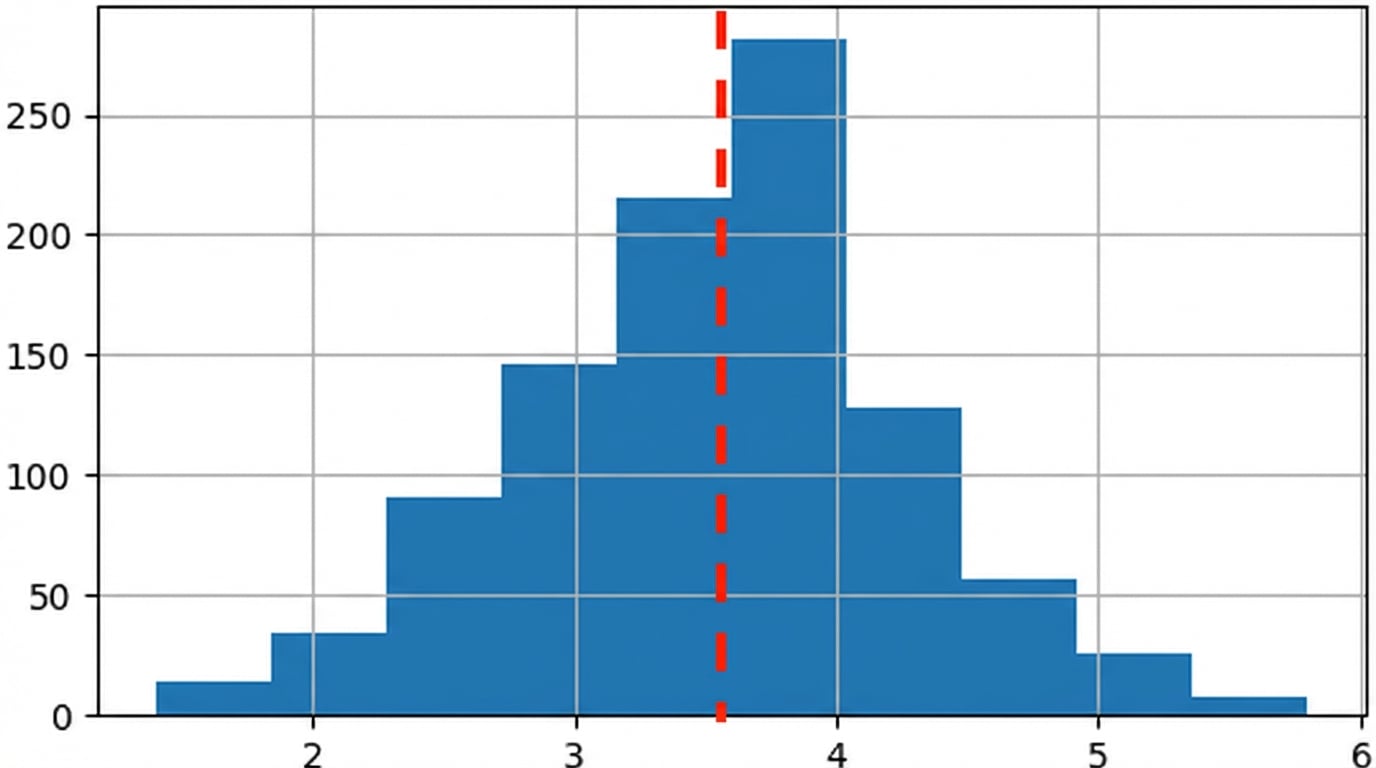
- Perkirakan karakteristik distribusi dasar yang tidak diketahui
- Lebih mudah memperkirakan karakteristik populasi besar

