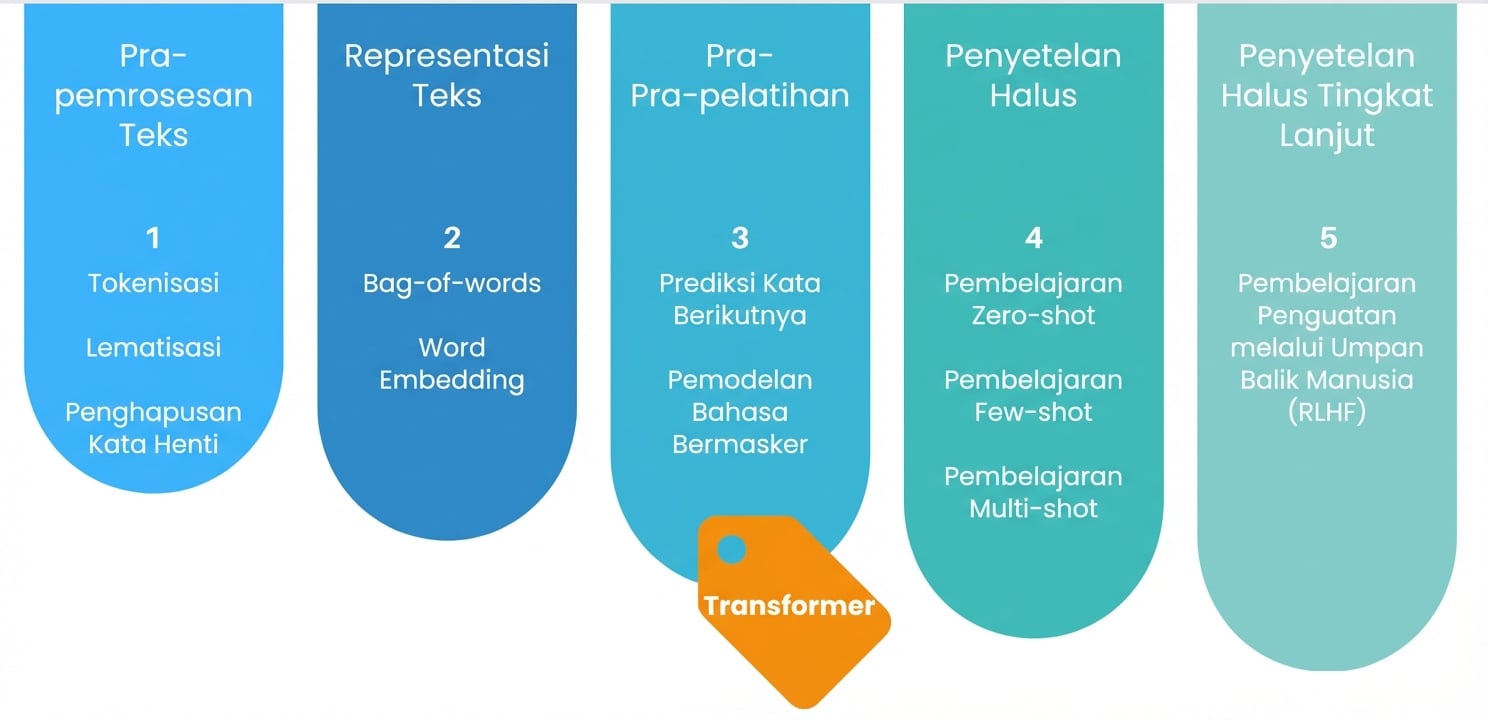
Fine-tuning lanjutan
Konsep Large Language Models (LLM)

Vidhi Chugh
AI strategist and ethicist
Kita di mana?
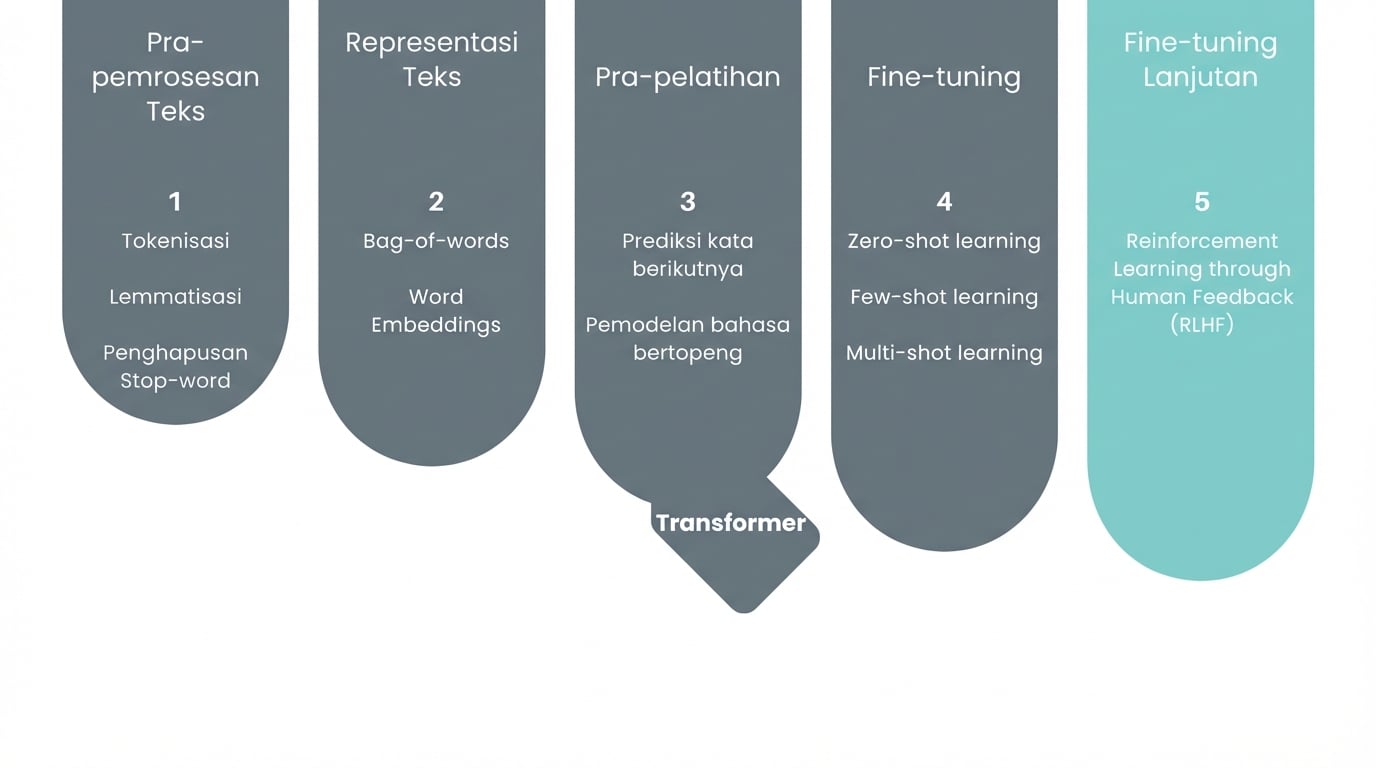
Reinforcement Learning melalui Umpan Balik Manusia

Pre-training

1 Freepik
Fine-tuning

Mengapa RLHF?

Menyederhanakan RLHF

Masuk pakar manusia

Waktunya umpan balik
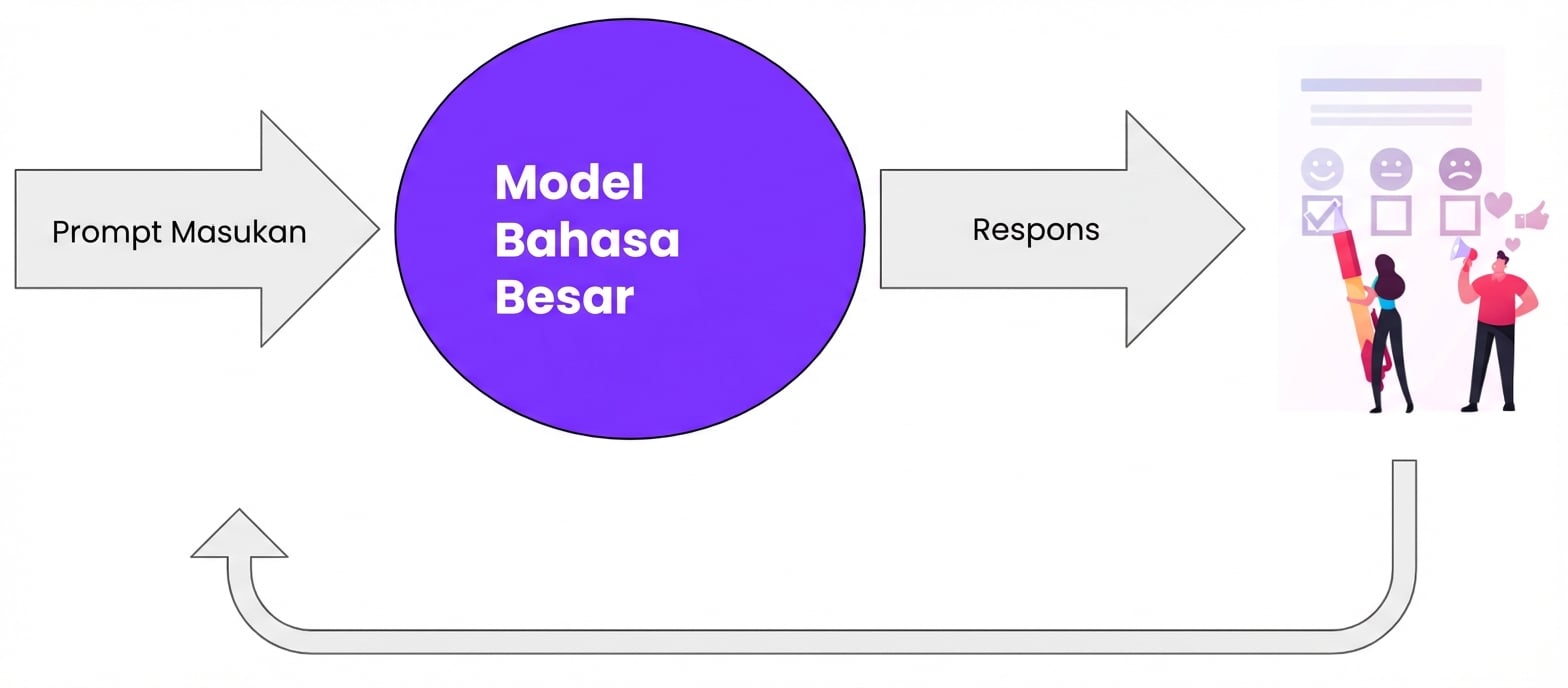
Menyelesaikan LLM