Melindungi LLM
Pengantar LLM di Python

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
Tantangan LLM
Dukungan multibahasa: keragaman bahasa, ketersediaan sumber daya, adaptabilitas

Dilema LLM terbuka vs tertutup: kolaborasi vs penggunaan yang bertanggung jawab

Skalabilitas model: kemampuan representasi, kebutuhan komputasi, kebutuhan pelatihan

Bias: data latih bias, pemahaman dan generasi bahasa yang tidak adil

1 Ikon dibuat oleh Freepik (freepik.com)
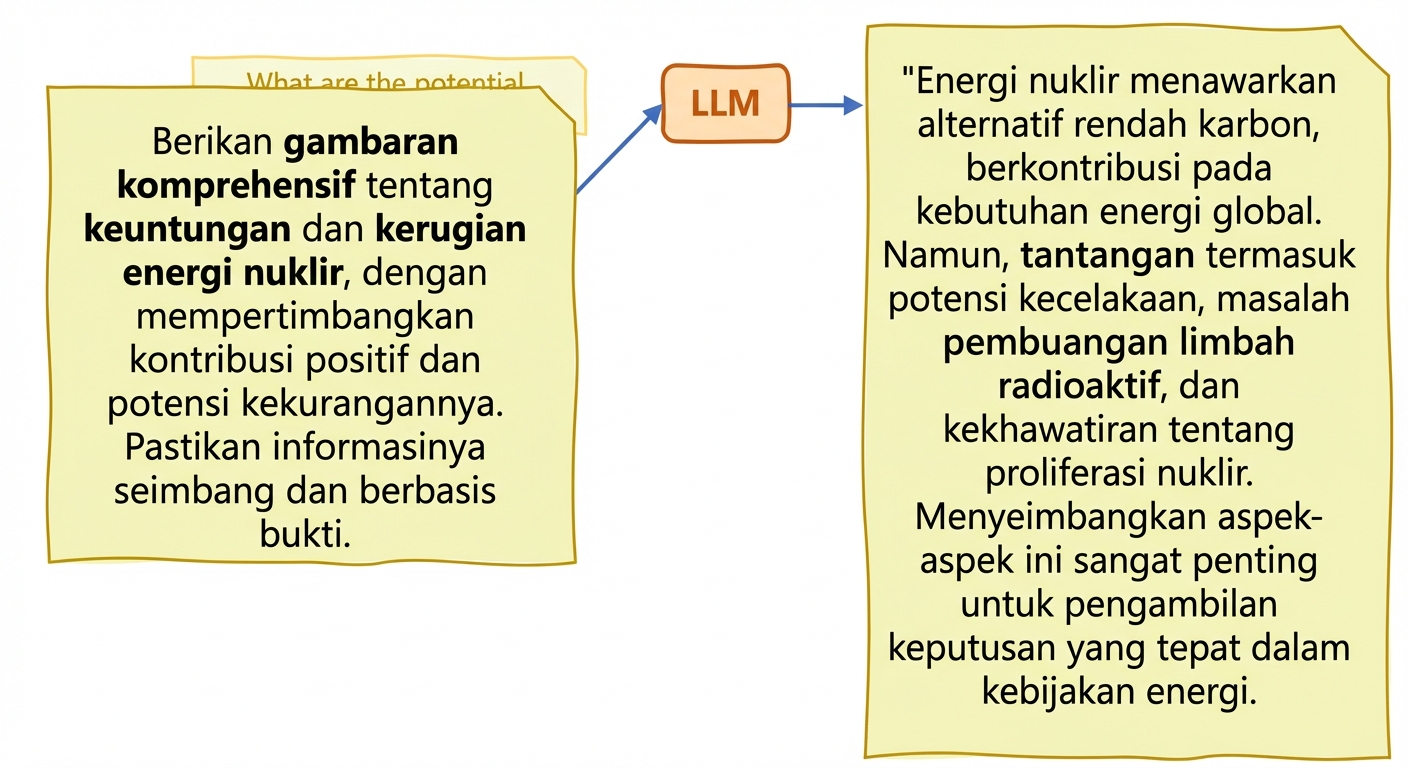
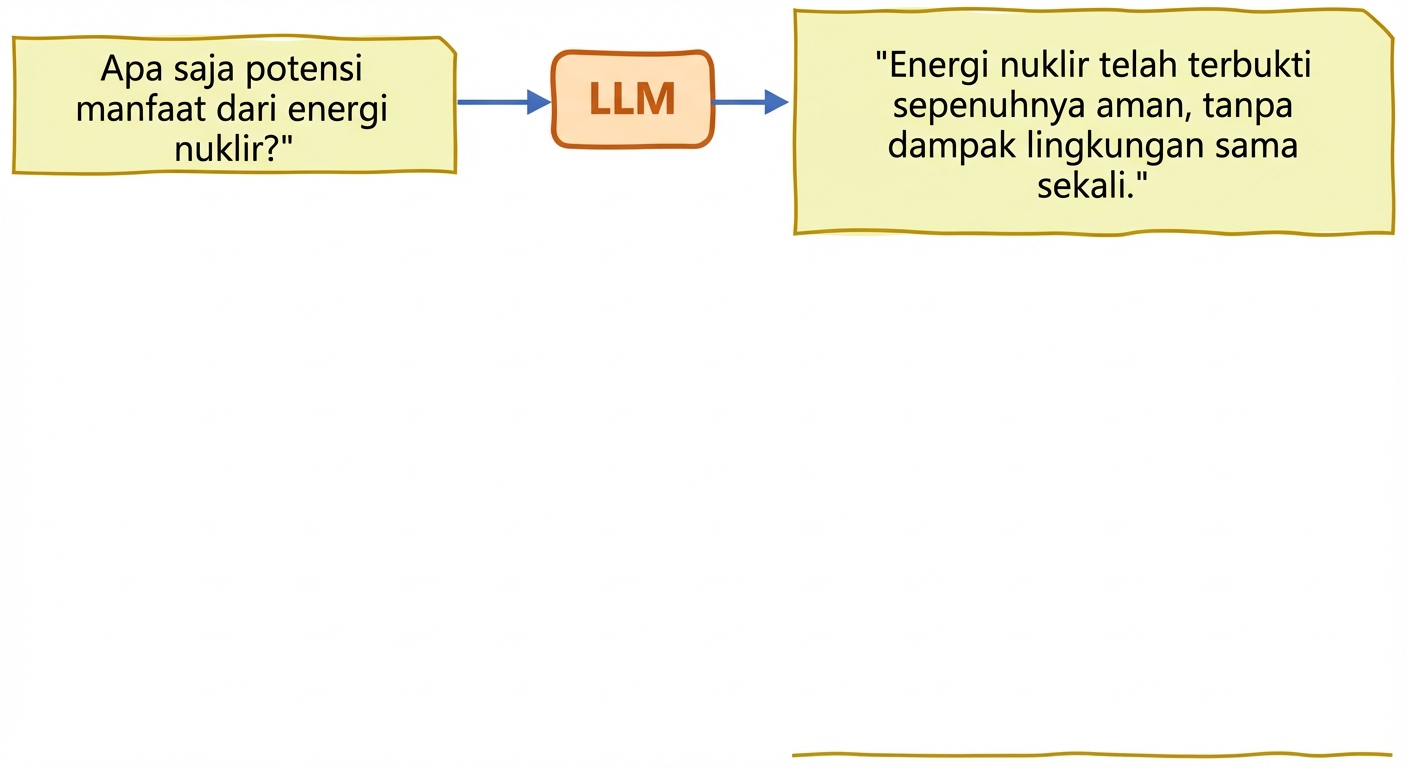
Kebenaran dan halusinasi
- Halusinasi: teks yang dihasilkan memuat informasi keliru/tidak masuk akal seolah akurat
Strategi mengurangi halusinasi LLM:
- Paparan data latih yang beragam dan representatif
- Audit bias pada output + teknik penghilangan bias
- Fine-tuning untuk kasus penggunaan sensitif
- Rekayasa prompt: susun dan perbaiki prompt dengan cermat
Kebenaran dan halusinasi
- Halusinasi: teks yang dihasilkan memuat informasi keliru/tidak masuk akal seolah akurat