Persiapan fine-tuning
Pengantar LLM di Python

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
Pipelines dan kelas Auto
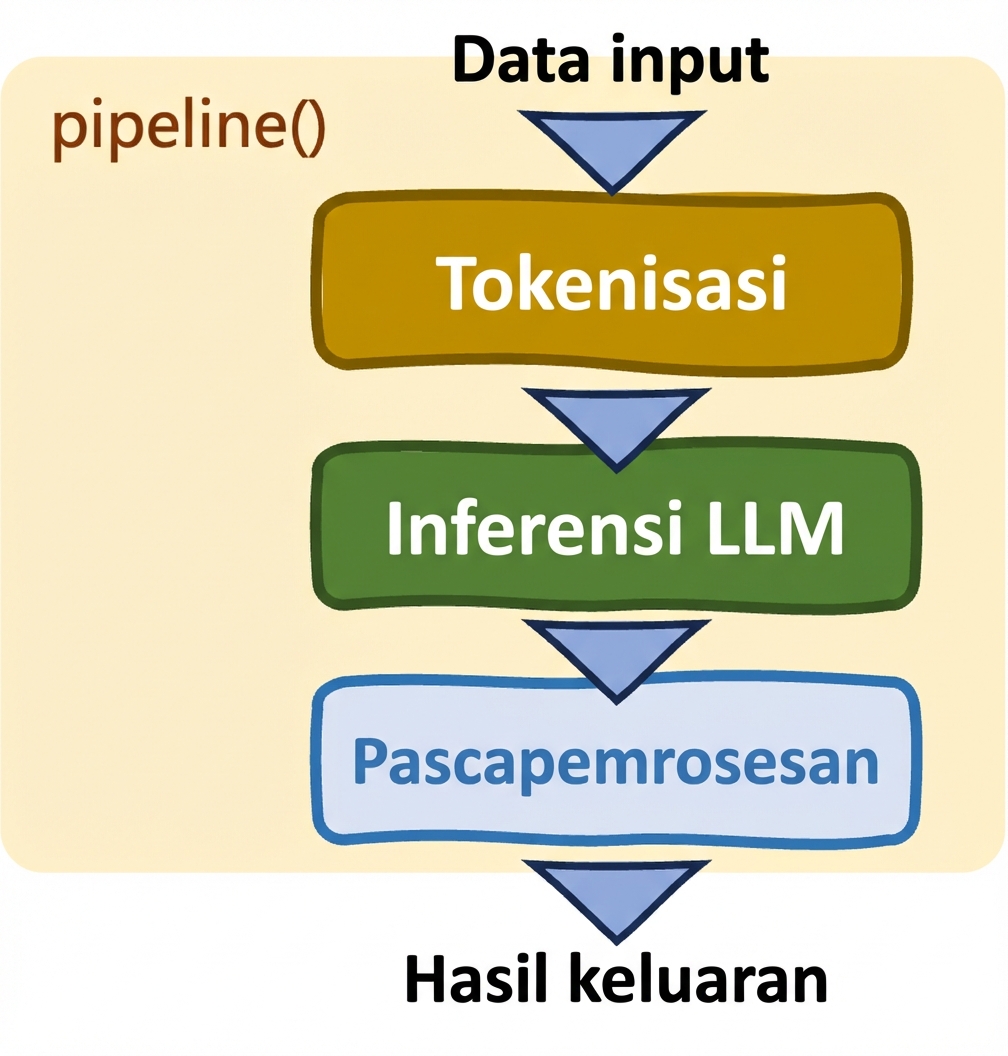
Pipelines: pipeline()
- Mempermudah tugas
- Pemilihan model dan tokenizer otomatis
- Kontrol terbatas
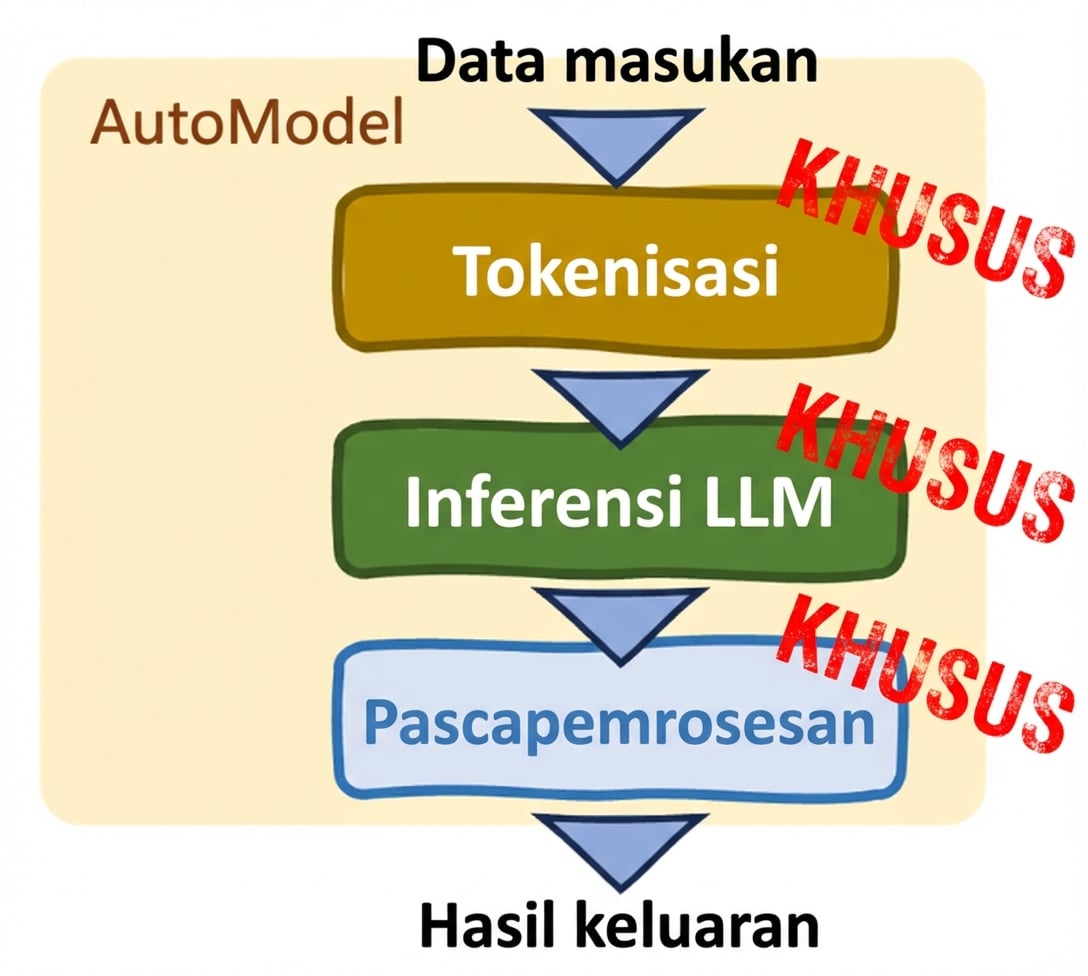
Kelas Auto (AutoModel class)
- Kustomisasi
- Penyesuaian manual
- Mendukung fine-tuning
Siklus hidup LLM
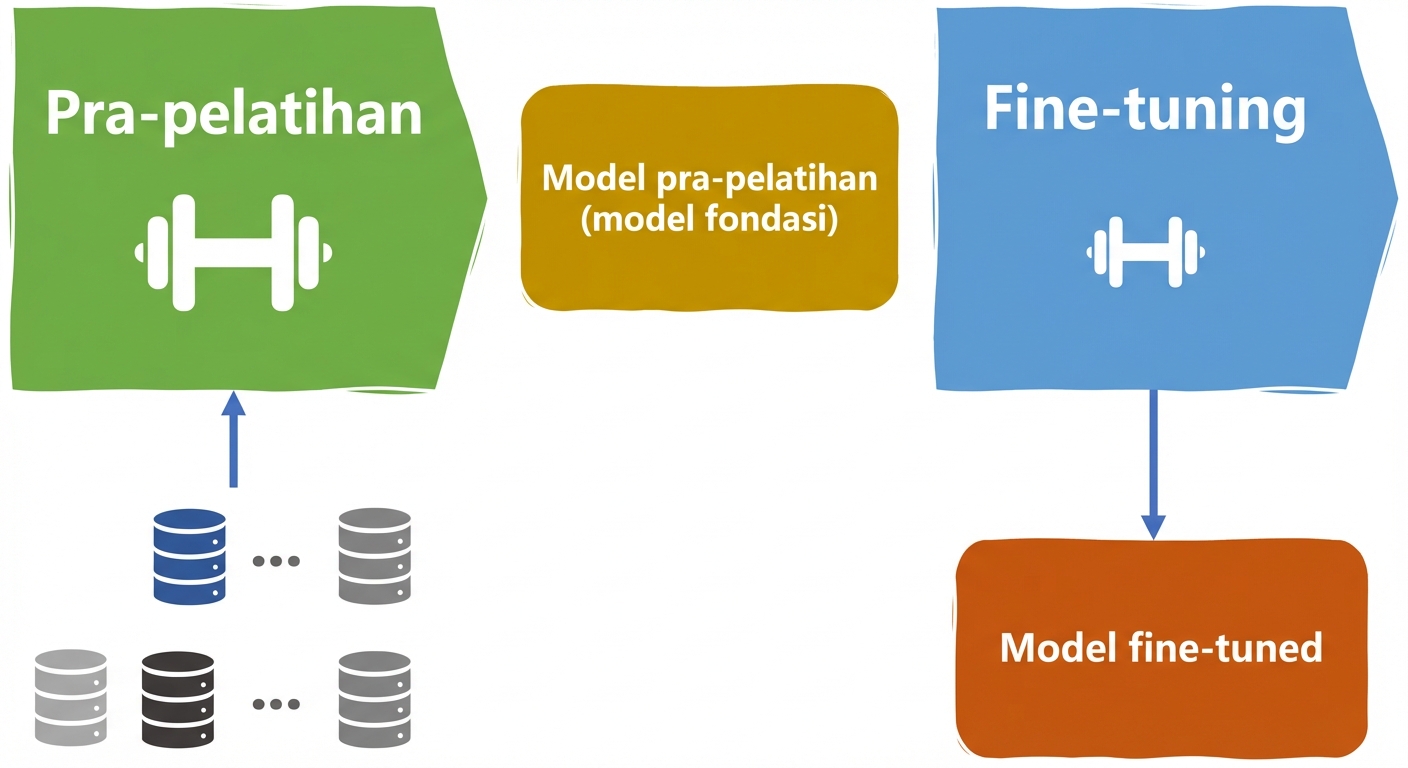
Siklus hidup LLM
Tokenisasi subword
- Umum pada tokenizer modern
- Kata dipecah menjadi sub-bagian bermakna

Tokenisasi subword
- Umum pada tokenizer modern
- Kata dipecah menjadi sub-bagian bermakna


