Transformasi fitur untuk klaster yang lebih baik
Unsupervised Learning in Python

Benjamin Wilson
Director of Research at lateral.io
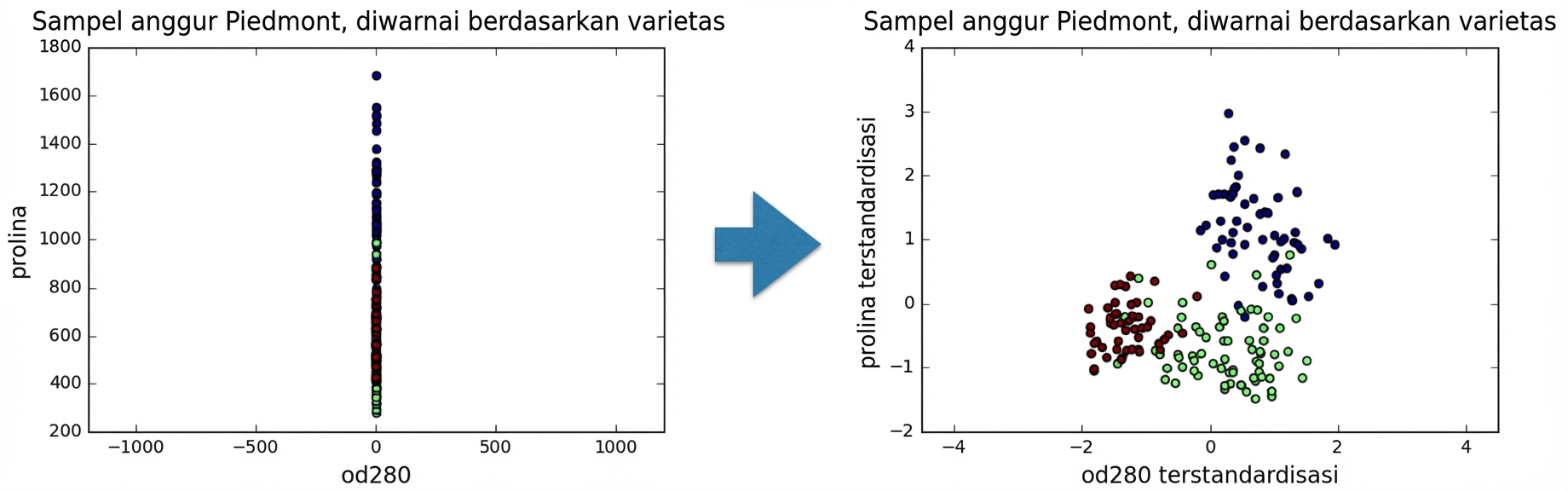
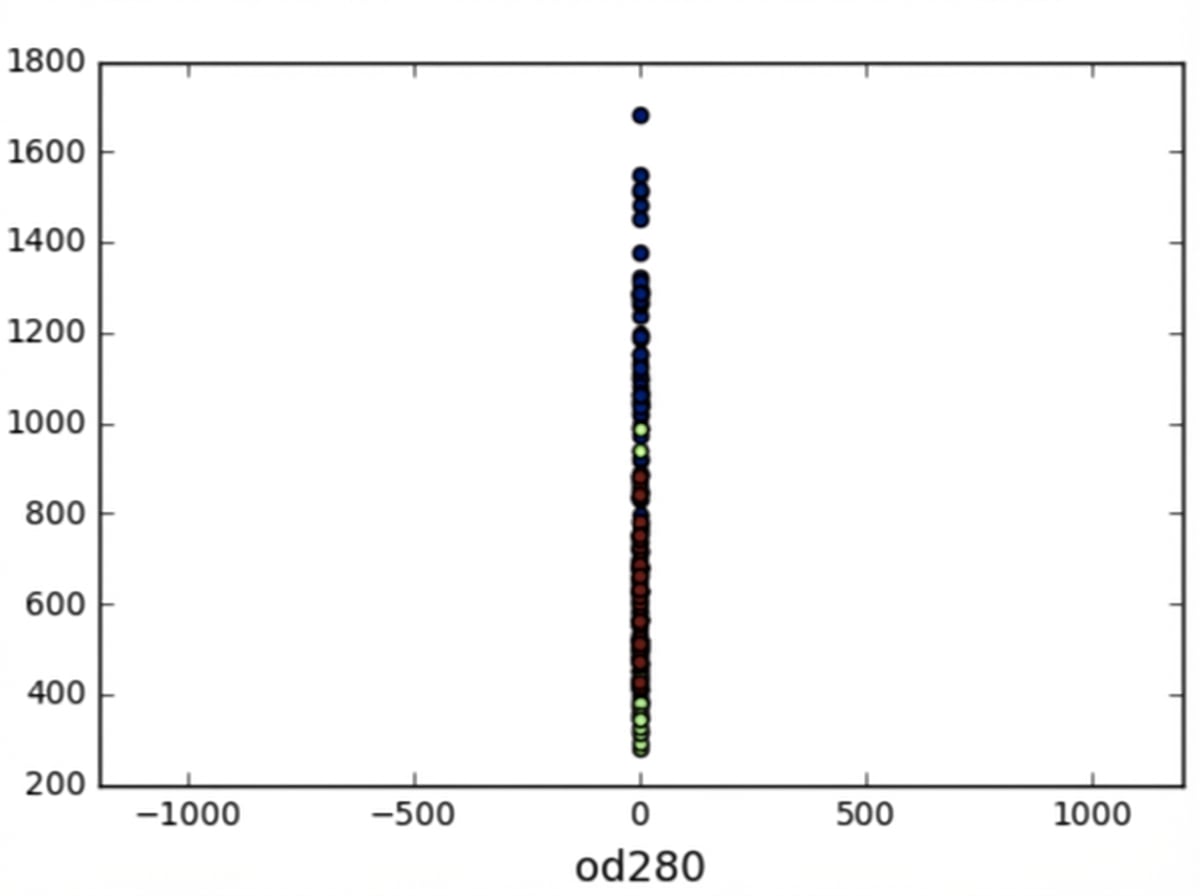
Varians fitur
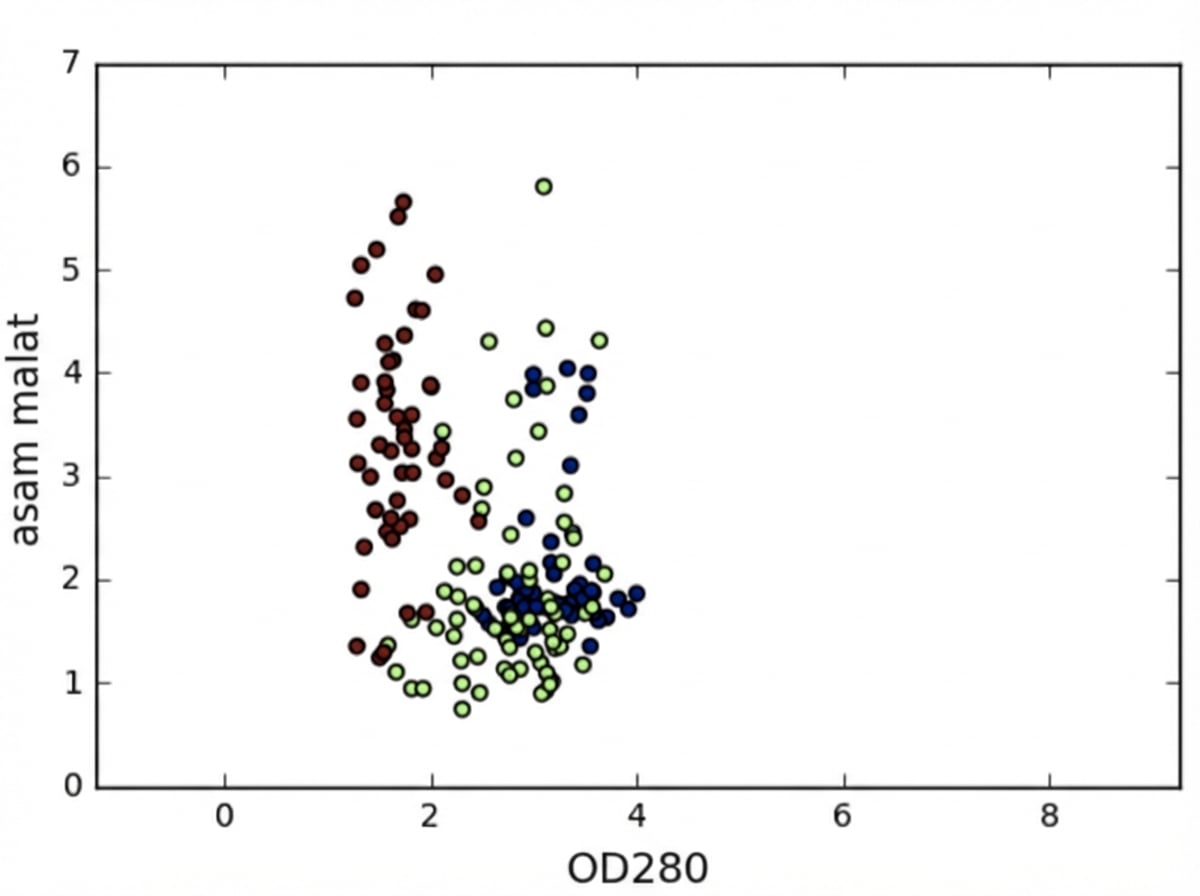
Varians fitur
StandardScaler
Di kmeans: varians fitur = pengaruh fitur
StandardScalermengubah tiap fitur agar mean 0 dan varians 1Fitur disebut "distandardisasi"