Mendiagnosis Masalah Bias dan Varians
Machine Learning dengan Model Berbasis Pohon di Python

Elie Kawerk
Data Scientist
Mengestimasi Error Generalisasi
Bagaimana kita mengestimasi error generalisasi model?
Tidak bisa langsung karena:
$f$ tidak diketahui,
biasanya hanya ada satu dataset,
noise tidak terduga.
Mengestimasi Error Generalisasi
Solusi:
- bagi data menjadi latih dan uji,
- latih $\hat{f}$ pada data latih,
- evaluasi error $\hat{f}$ pada data uji yang belum terlihat.
- error generalisasi $\hat{f} \approx$ error data uji $\hat{f}$.
Evaluasi Model yang Lebih Baik dengan Cross-Validation
Set uji tidak boleh disentuh sampai kita yakin atas kinerja $\hat{f}$.
Evaluasi $\hat{f}$ pada data latih: estimasi bias, $\hat{f}$ sudah melihat semua titik latih.
Solusi $\rightarrow$ Cross-Validation (CV):
K-Fold CV,
Hold-Out CV.
K-Fold CV
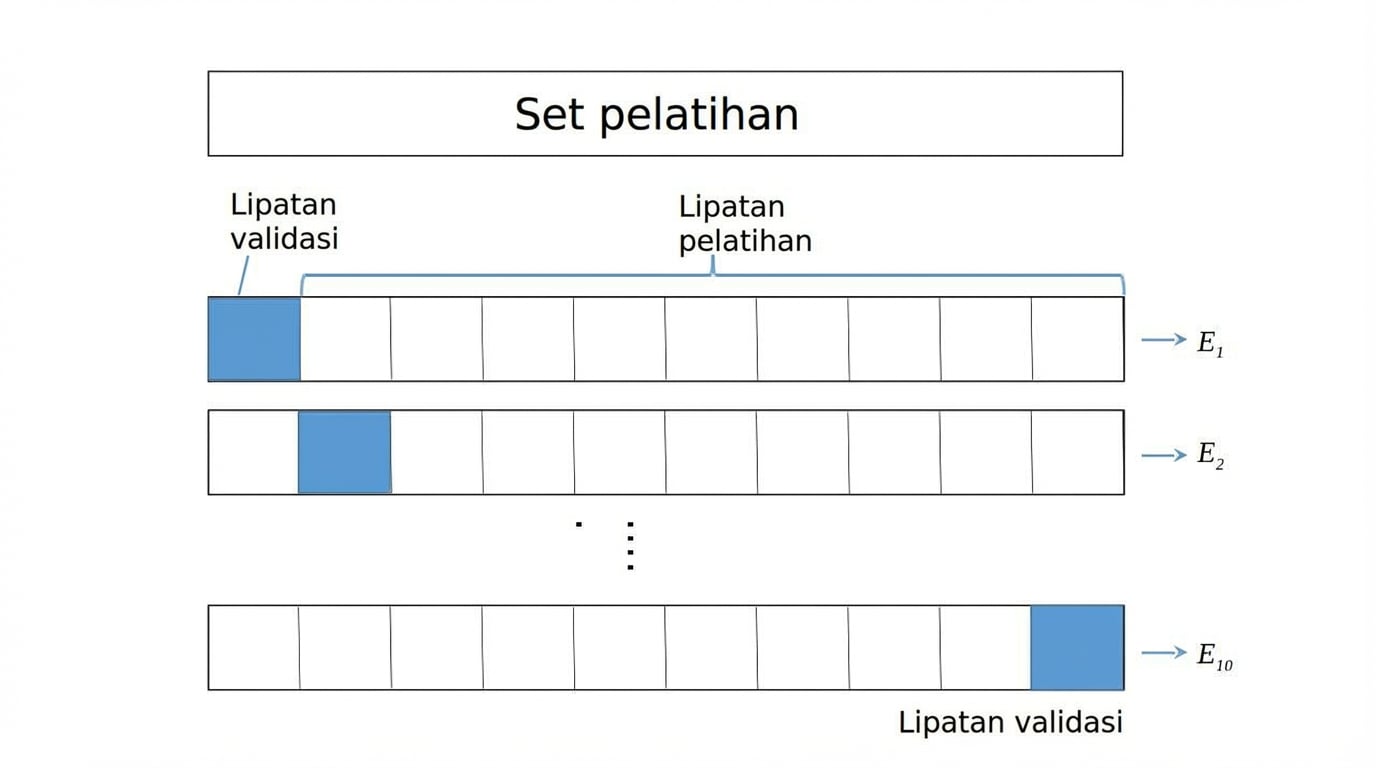
K-Fold CV
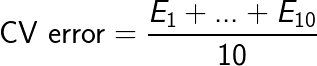
Mendiagnosis Masalah Varians
Jika $\hat{f}$ mengalami varians tinggi:
Error CV $\hat{f}$ > error data latih $\hat{f}$.
- $\hat{f}$ disebut overfit pada data latih. Cara mengatasinya:
- kurangi kompleksitas model,
- mis: kurangi kedalaman maks, naikkan min sampel per daun, ...
- kumpulkan lebih banyak data, ..
Mendiagnosis Masalah Bias
Jika $\hat{f}$ mengalami bias tinggi:
Error CV $\hat{f} \approx$ error data latih $\hat{f} >>$ error yang diinginkan.
$\hat{f}$ disebut underfit pada data latih. Cara mengatasinya:
- tingkatkan kompleksitas model
- mis: tingkatkan kedalaman maks, turunkan min sampel per daun, ...
- kumpulkan fitur yang lebih relevan
K-Fold CV di sklearn pada Dataset Auto
from sklearn.tree import DecisionTreeRegressor from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error as MSE from sklearn.model_selection import cross_val_score# Set seed for reproducibility SEED = 123 # Split data into 70% train and 30% test X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.3, random_state=SEED)# Instantiate decision tree regressor and assign it to 'dt' dt = DecisionTreeRegressor(max_depth=4, min_samples_leaf=0.14, random_state=SEED)
K-Fold CV di sklearn pada Dataset Auto
# Evaluate the list of MSE ontained by 10-fold CV # Set n_jobs to -1 in order to exploit all CPU cores in computation MSE_CV = - cross_val_score(dt, X_train, y_train, cv= 10, scoring='neg_mean_squared_error', n_jobs = -1)# Fit 'dt' to the training set dt.fit(X_train, y_train) # Predict the labels of training set y_predict_train = dt.predict(X_train) # Predict the labels of test set y_predict_test = dt.predict(X_test)
# CV MSE
print('CV MSE: {:.2f}'.format(MSE_CV.mean()))
CV MSE: 20.51
# Training set MSE
print('Train MSE: {:.2f}'.format(MSE(y_train, y_predict_train)))
Train MSE: 15.30
# Test set MSE
print('Test MSE: {:.2f}'.format(MSE(y_test, y_predict_test)))
Test MSE: 20.92
Ayo berlatih!
Machine Learning dengan Model Berbasis Pohon di Python

