Gradien menghilang dan meledak
Deep Learning Lanjutan dengan PyTorch

Michal Oleszak
Machine Learning Engineer
Gradien menghilang
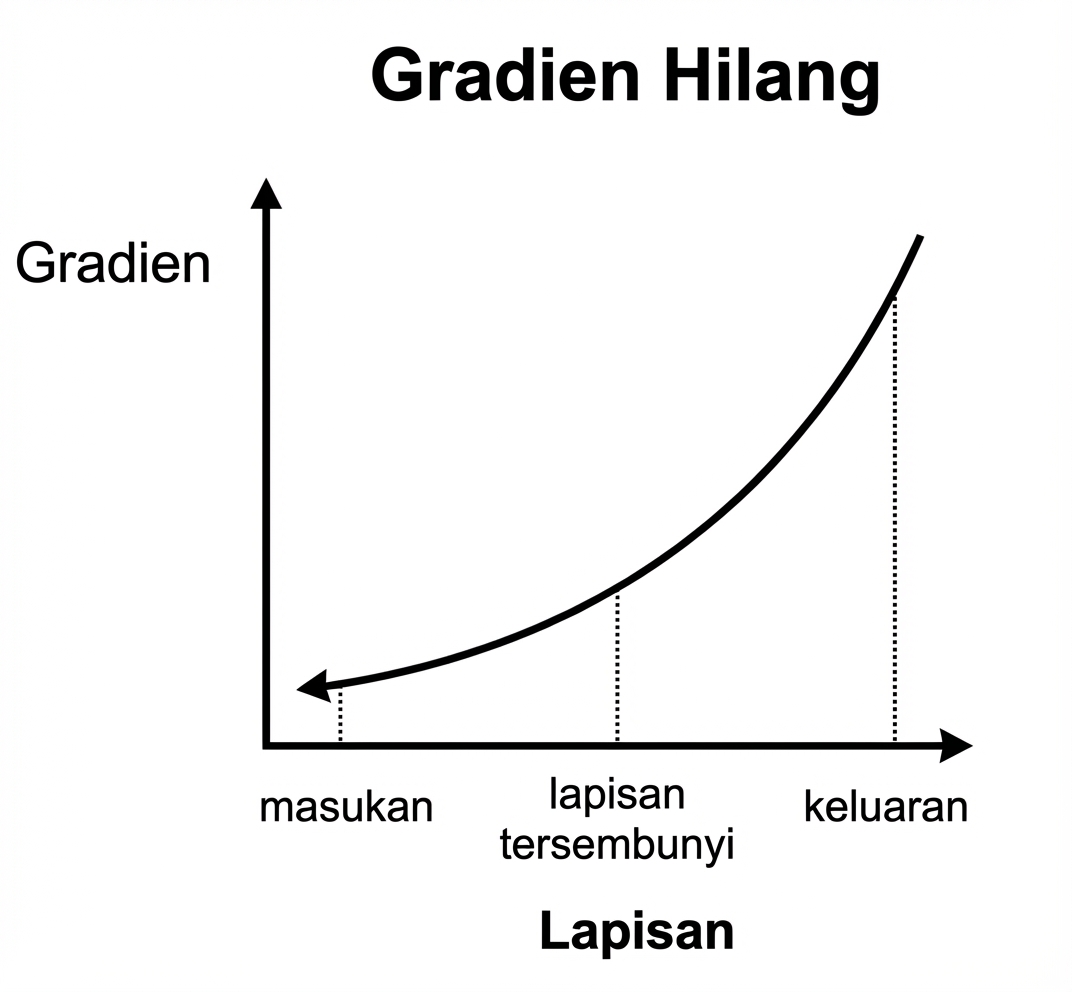
Gradien meledak
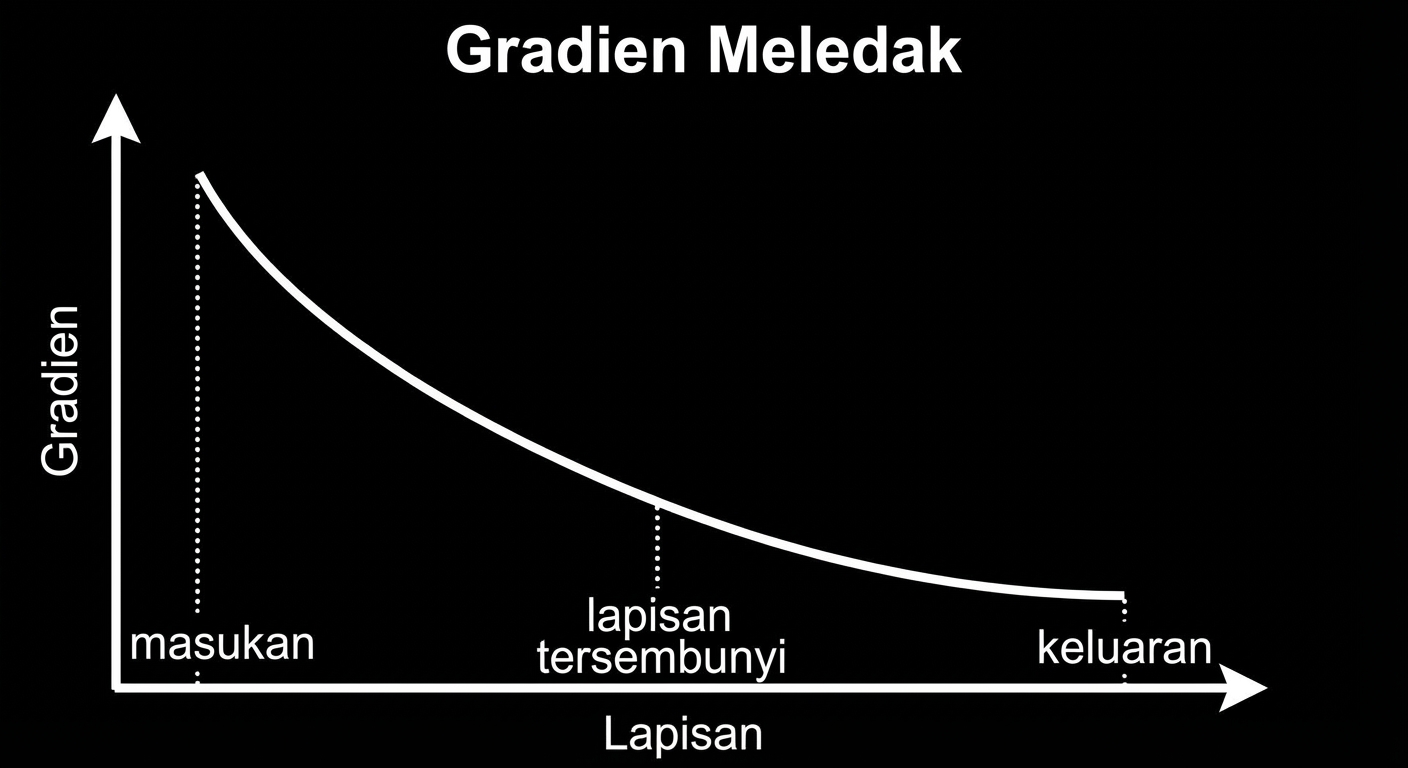
Solusi untuk gradien tidak stabil
- Inisialisasi bobot yang tepat
- Aktivasi yang baik
- Batch normalization

Fungsi aktivasi
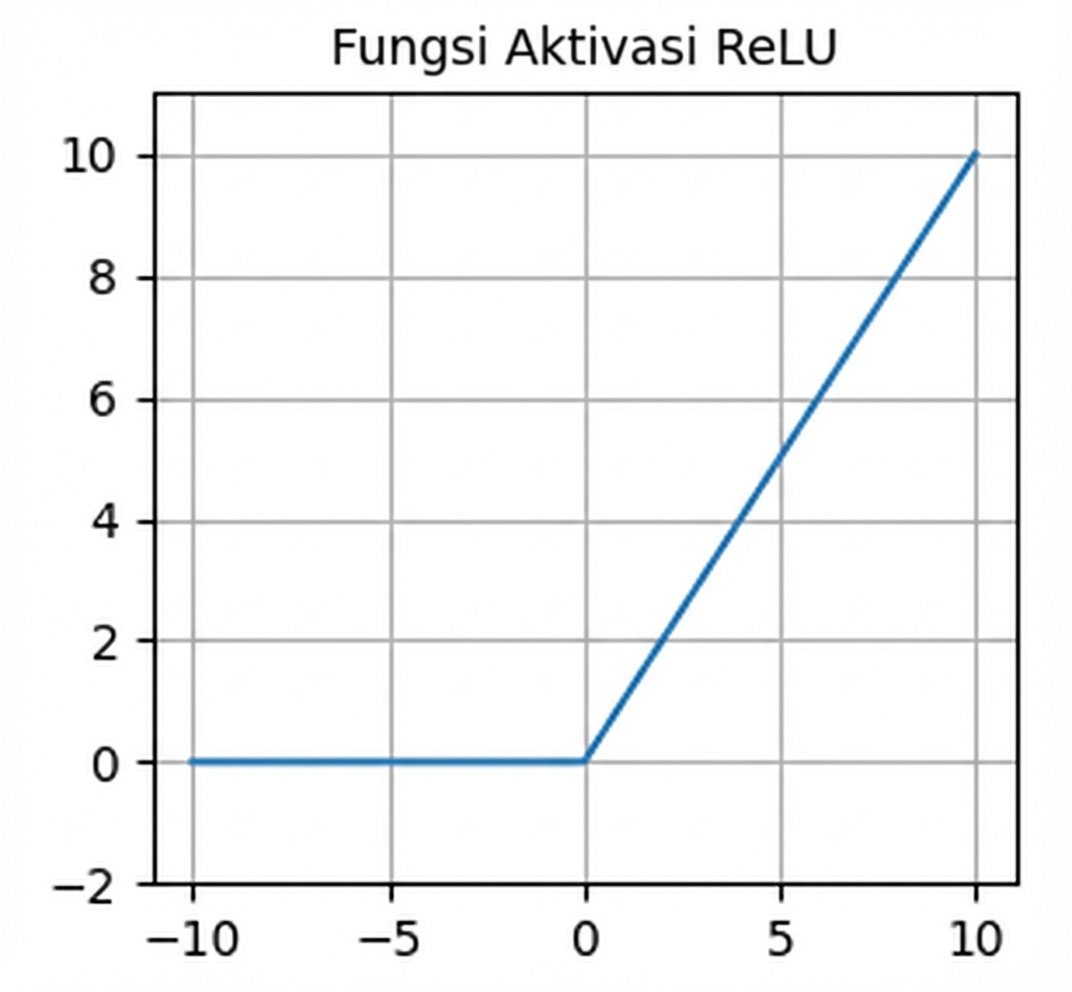
- Sering jadi aktivasi default
nn.functional.relu()- Nol untuk input negatif — neuron mati
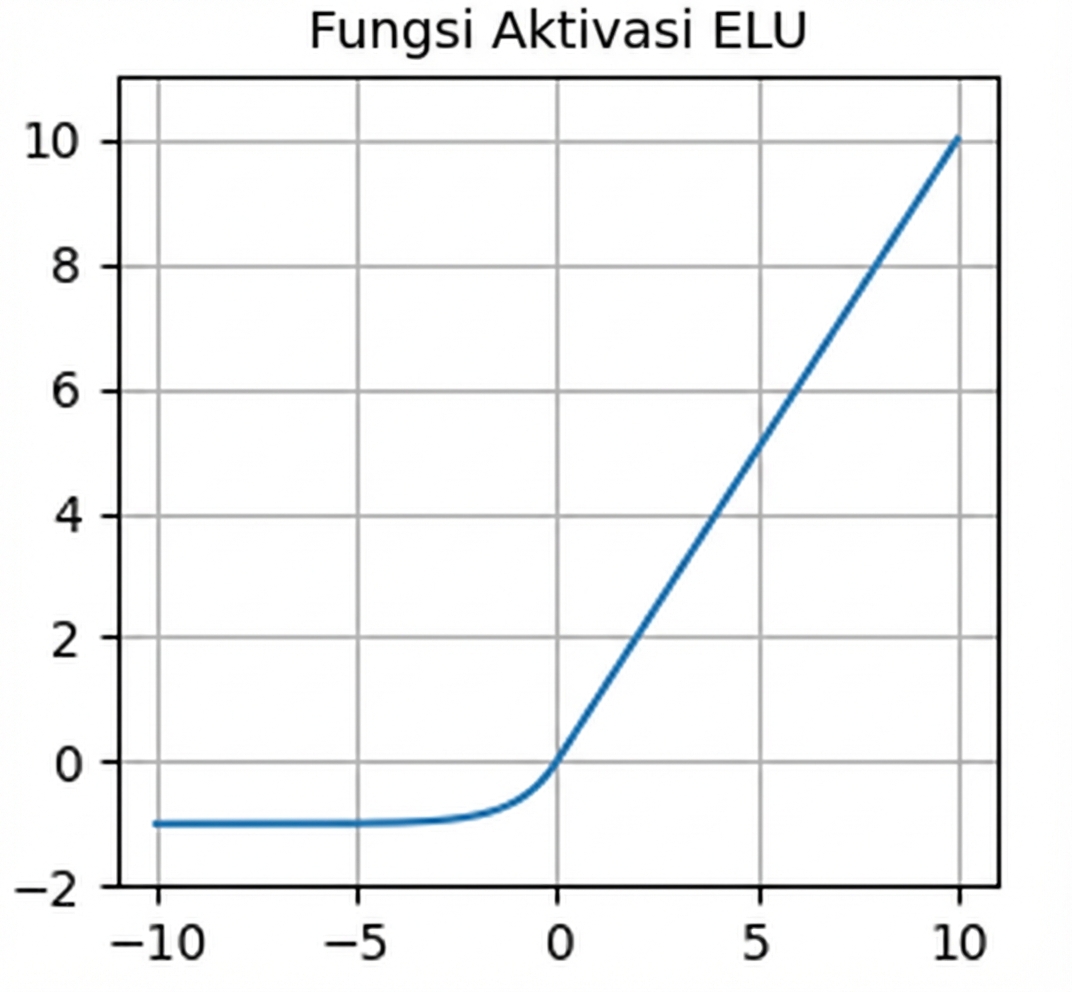
nn.functional.elu()- Gradien tidak nol untuk nilai negatif — mengatasi neuron mati
- Rata-rata output sekitar nol — bantu cegah gradien menghilang

