Galat baku dan Teorema Limit Pusat
Sampling di Python

James Chapman
Curriculum Manager, DataCamp
Distribusi penarikan contoh rata-rata cup points
Ukuran sampel: 5
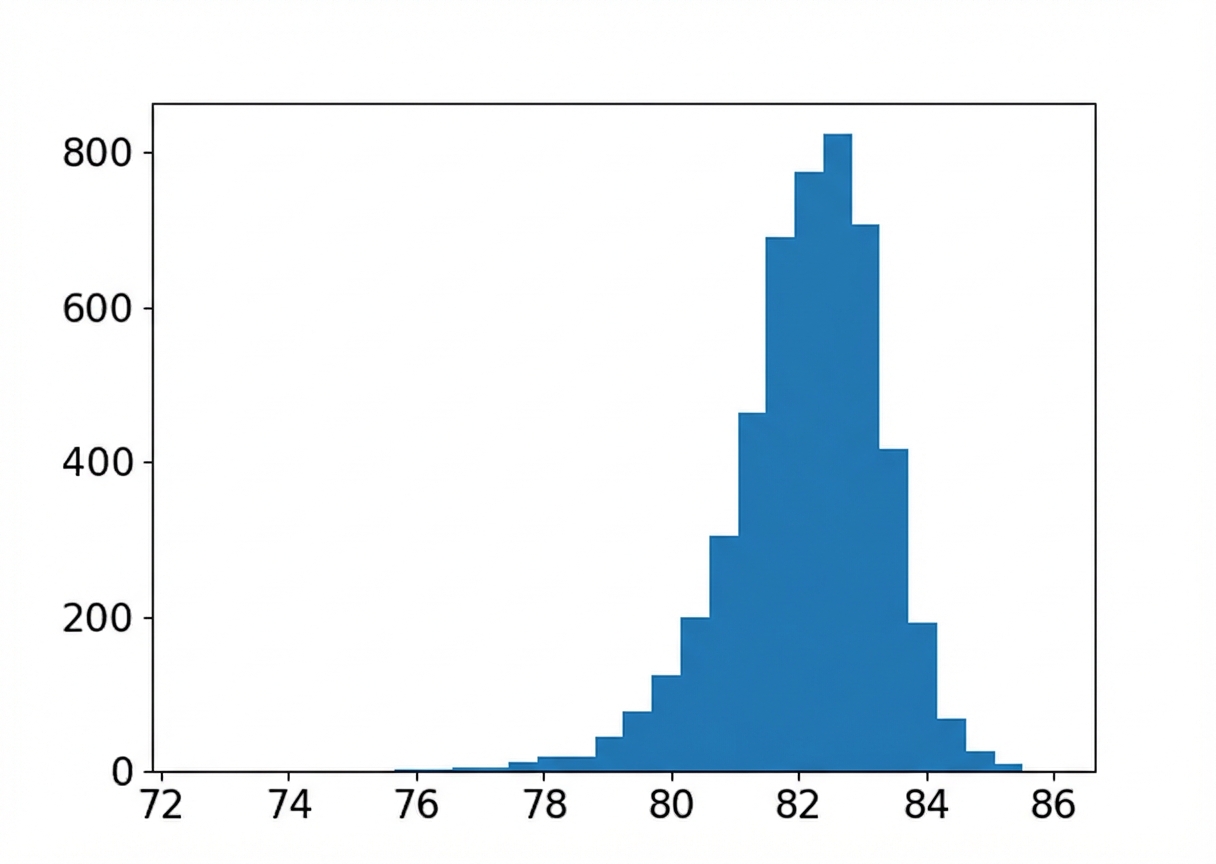
Ukuran sampel: 20
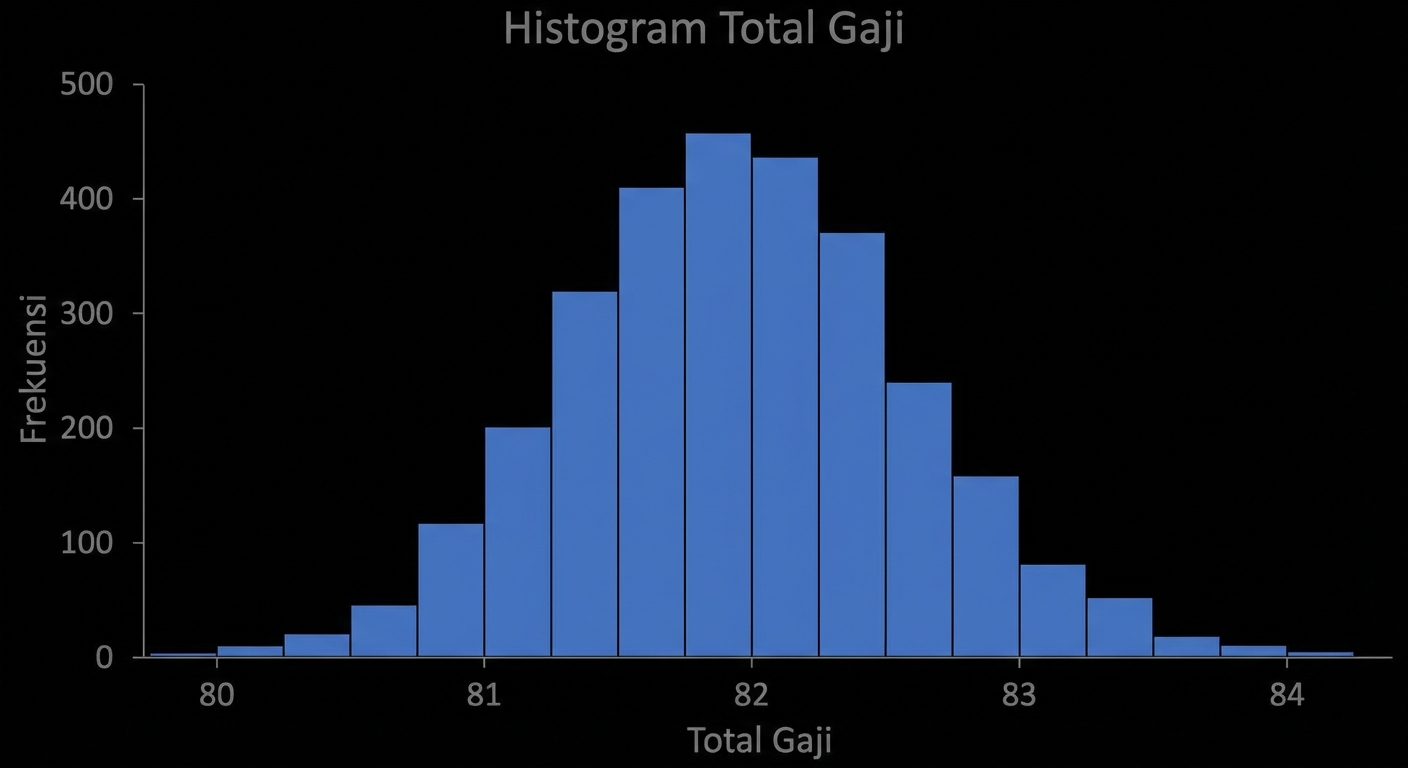
Ukuran sampel: 80
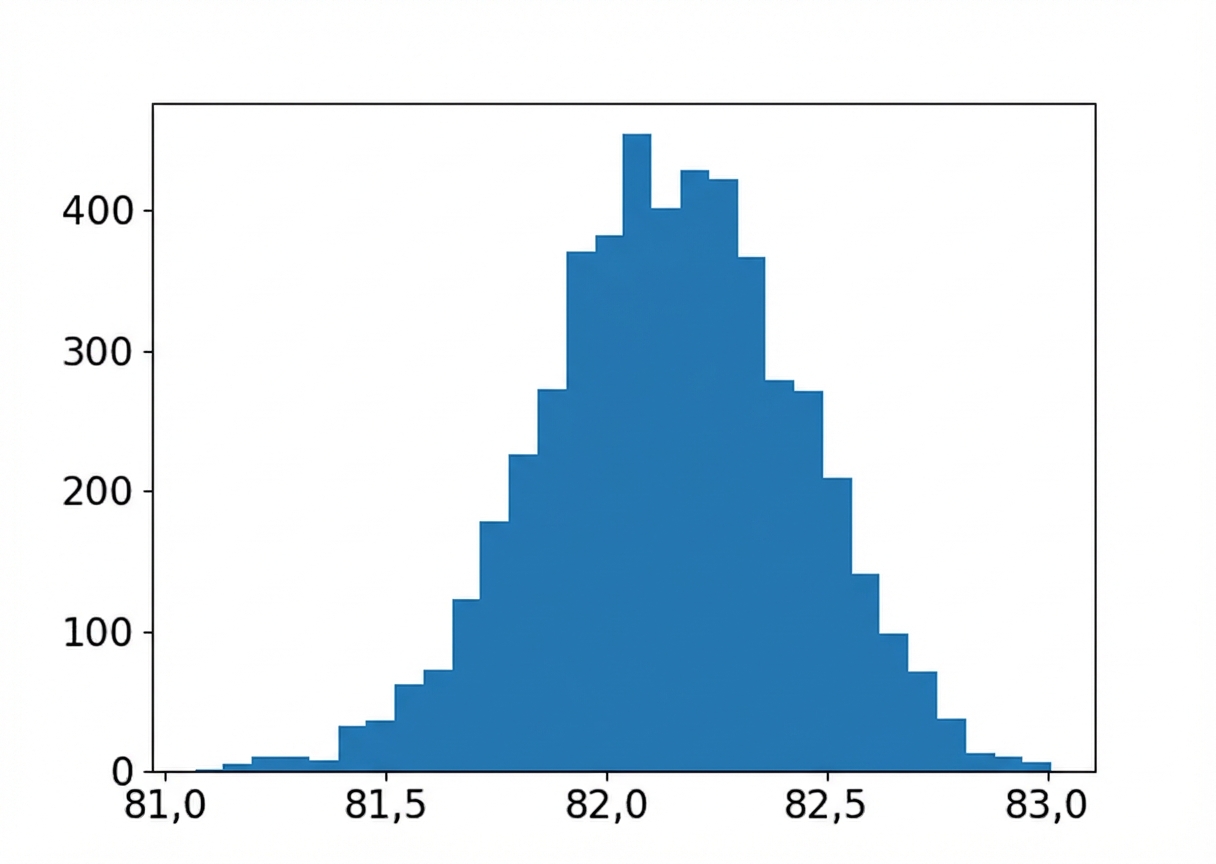
Ukuran sampel: 320
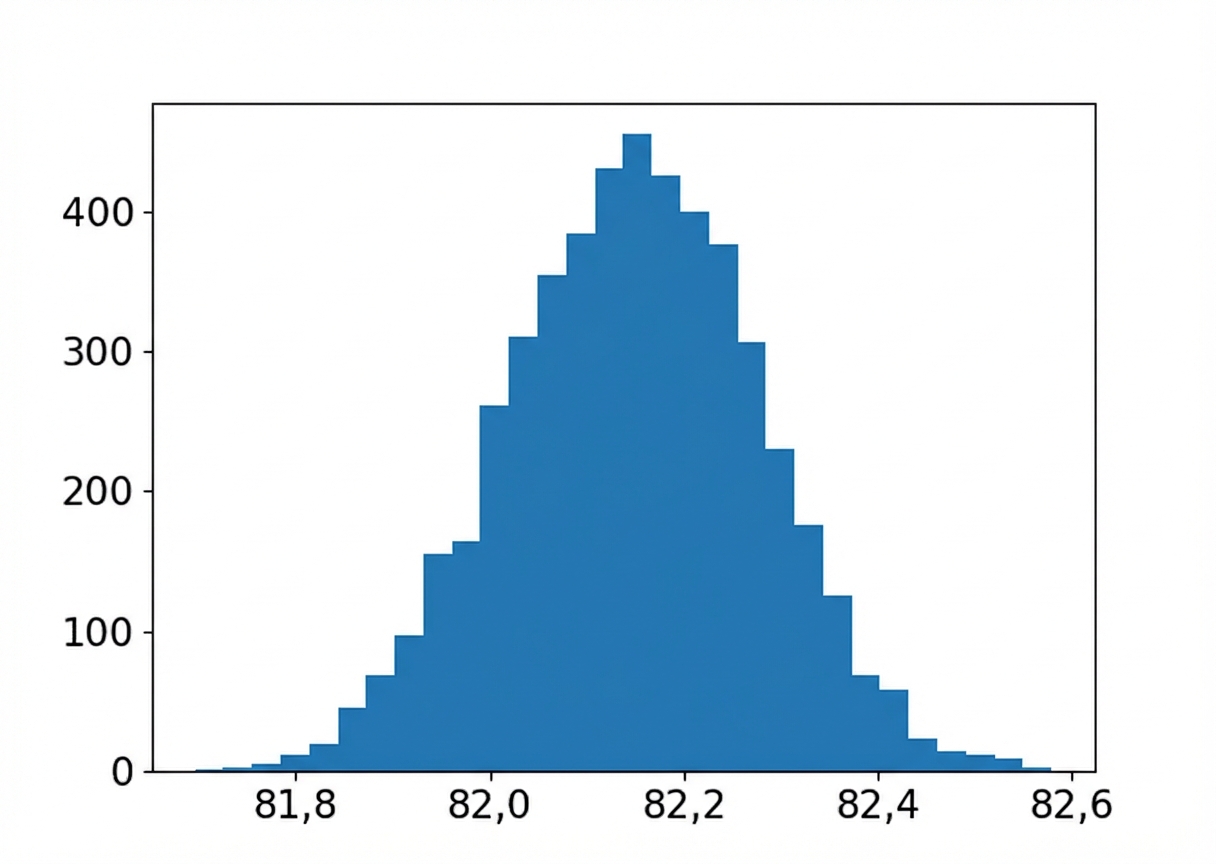
Sampling di Python
James Chapman
Curriculum Manager, DataCamp
Ukuran sampel: 5
Ukuran sampel: 20
Ukuran sampel: 80
Ukuran sampel: 320

