Membandingkan distribusi sampel dan bootstrap
Sampling di Python

James Chapman
Curriculum Manager, DataCamp
Subset fokus kopi
coffee_sample = coffee_ratings[["variety", "country_of_origin", "flavor"]]\
.reset_index().sample(n=500)
index variety country_of_origin flavor
132 132 Other Costa Rica 7.58
51 51 None United States (Hawaii) 8.17
42 42 Yellow Bourbon Brazil 7.92
569 569 Bourbon Guatemala 7.67
.. ... ... ... ...
643 643 Catuai Costa Rica 7.42
356 356 Caturra Colombia 7.58
494 494 None Indonesia 7.58
169 169 None Brazil 7.81
[500 baris x 4 kolom]
Bootstrap mean cita rasa kopi
import numpy as np
mean_flavors_5000 = []
for i in range(5000):
mean_flavors_5000.append(
np.mean(coffee_sample.sample(frac=1, replace=True)['flavor'])
)
bootstrap_distn = mean_flavors_5000
Distribusi bootstrap mean cita rasa
import matplotlib.pyplot as plt
plt.hist(bootstrap_distn, bins=15)
plt.show()
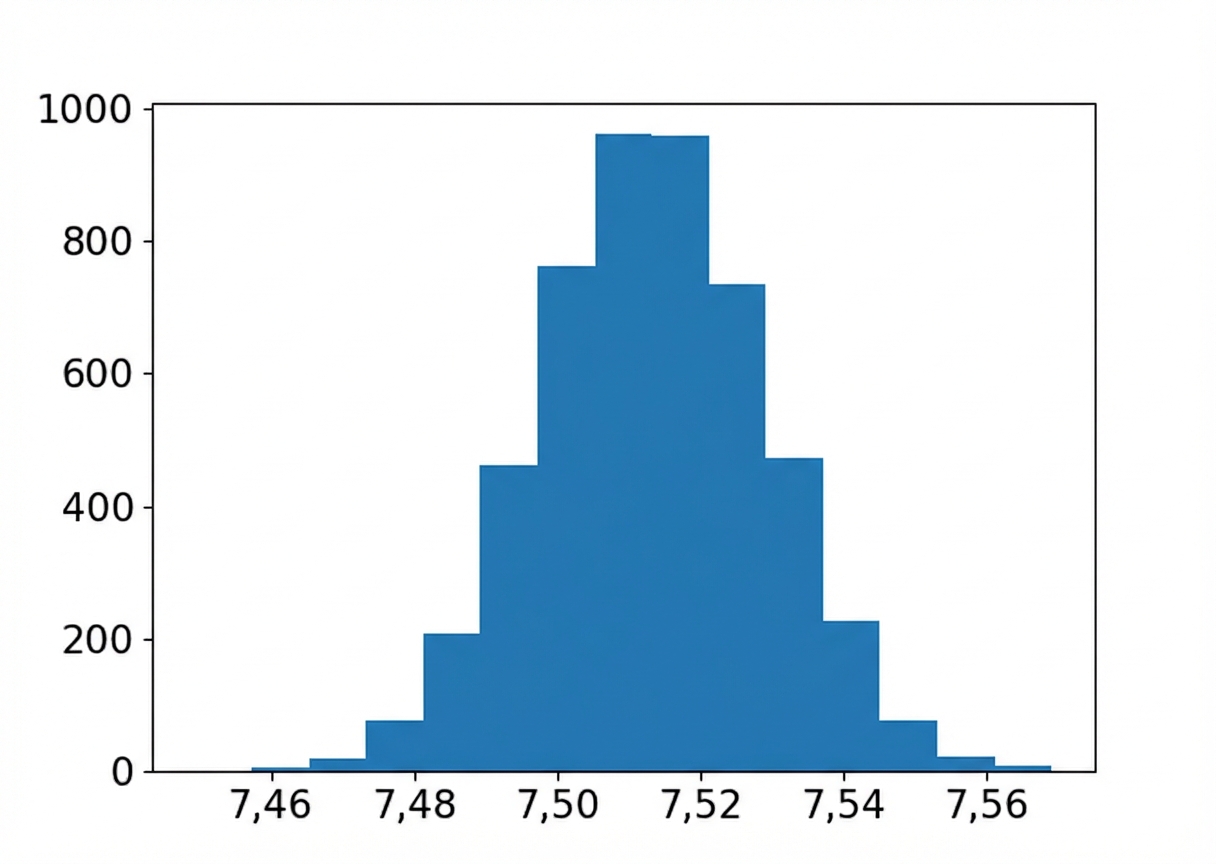
Mean sampel, distribusi bootstrap, dan populasi
Mean sampel:
coffee_sample['flavor'].mean()
7.5132200000000005
Perkiraan mean populasi:
np.mean(bootstrap_distn)
7.513357731999999
Mean populasi sebenarnya:
coffee_ratings['flavor'].mean()
7.526046337817639
Menafsirkan mean
Rata-rata distribusi bootstrap:
- Biasanya dekat dengan mean sampel
- Mungkin bukan perkiraan yang baik untuk mean populasi
Bootstrapping tidak dapat mengoreksi bias dari pengambilan sampel
SD sampel vs. SD distribusi bootstrap
Simpangan baku sampel:
coffee_sample['flavor'].std()
0.3540883911928703
Perkiraan simpangan baku populasi?
np.std(bootstrap_distn, ddof=1)
0.015768474367958217
SD sampel, distribusi bootstrap, dan populasi
Simpangan baku sampel:
coffee_sample['flavor'].std()
0.3540883911928703
Perkiraan simpangan baku populasi:
standard_error = np.std(bootstrap_distn, ddof=1)
Standard error adalah simpangan baku dari statistik yang diminati
Simpangan baku sebenarnya:
coffee_ratings['flavor'].std(ddof=0)
0.34125481224622645
standard_error * np.sqrt(500)
0.3525938058821761
Standard error dikali akar ukuran sampel memperkirakan simpangan baku populasi
Menafsirkan standard error
- Standard error terestimasi → simpangan baku distribusi bootstrap untuk suatu statistik sampel
- $\text{Simp. baku populasi} \approx \text{Standard error} \times \sqrt{\text{Ukuran sampel}}$
Ayo berlatih!
Sampling di Python

