Uji hipotesis dan z-score
Pengujian Hipotesis dengan Python

James Chapman
Curriculum Manager, DataCamp
A/B testing

1 Kredit gambar: "Electronic Arts" oleh majaX1 CC BY-NC-SA 2.0
Uji A/B laman ritel
Kontrol:

Perlakuan:
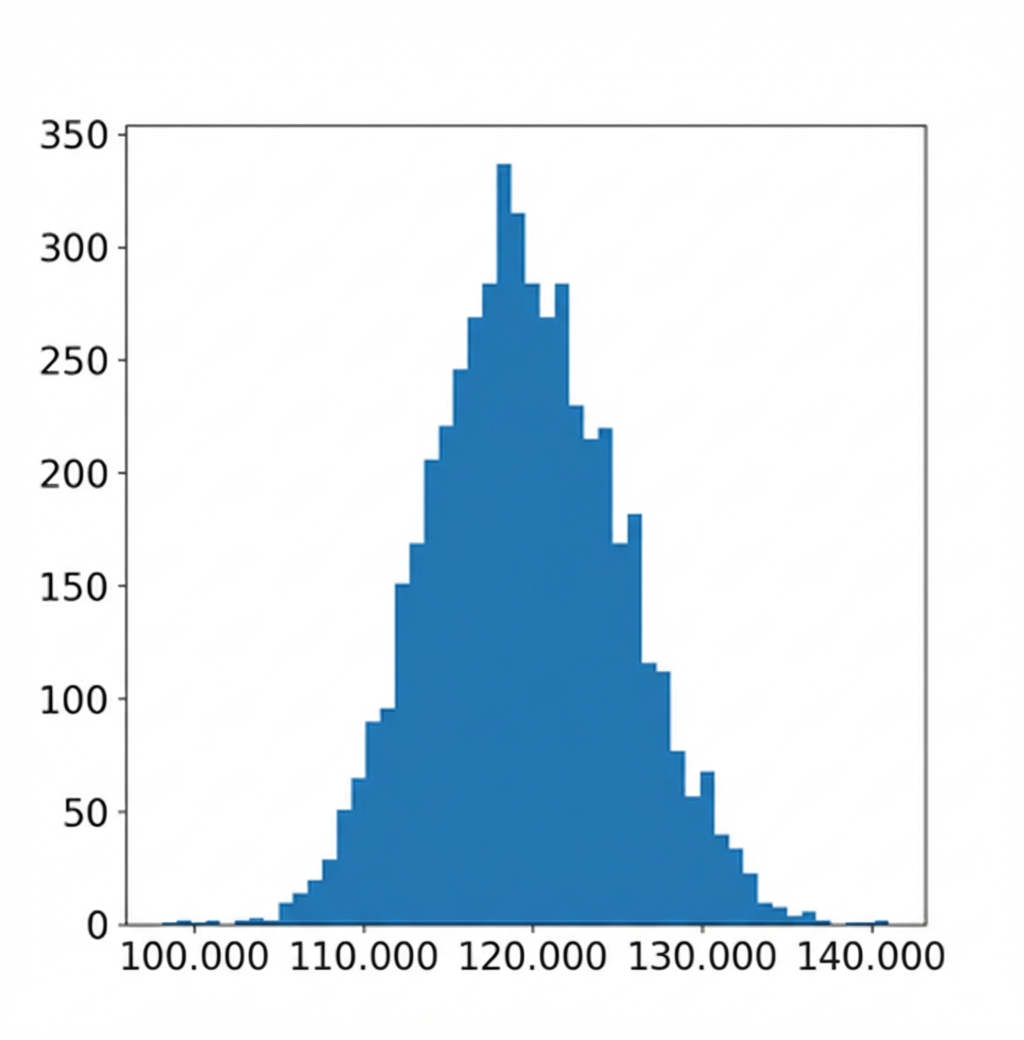
Visualisasi distribusi bootstrap
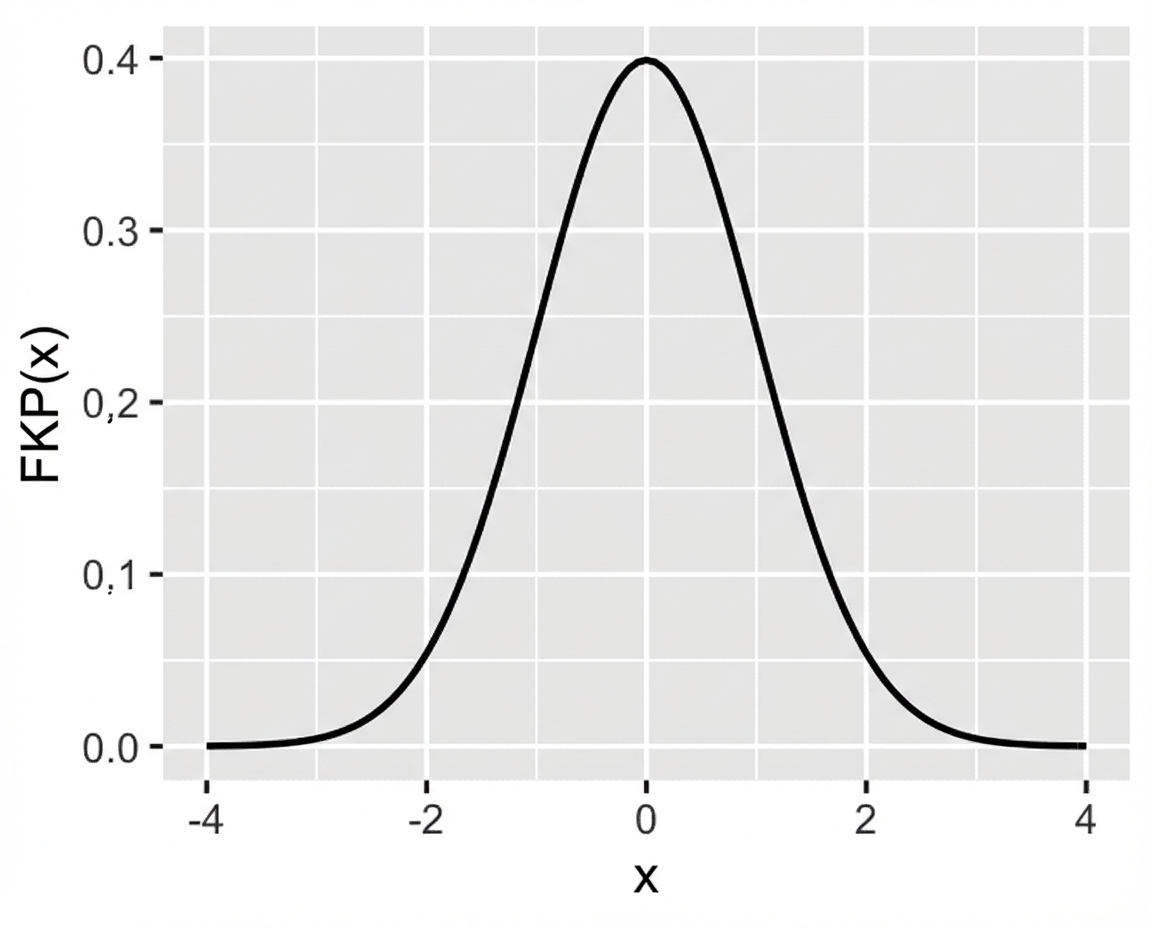
Distribusi normal standar (z)
Distribusi normal standar: normal dengan mean = 0 dan simpangan baku = 1