Metode pemisahan lanjutan
Retrieval Augmented Generation (RAG) dengan LangChain

Meri Nova
Machine Learning Engineer
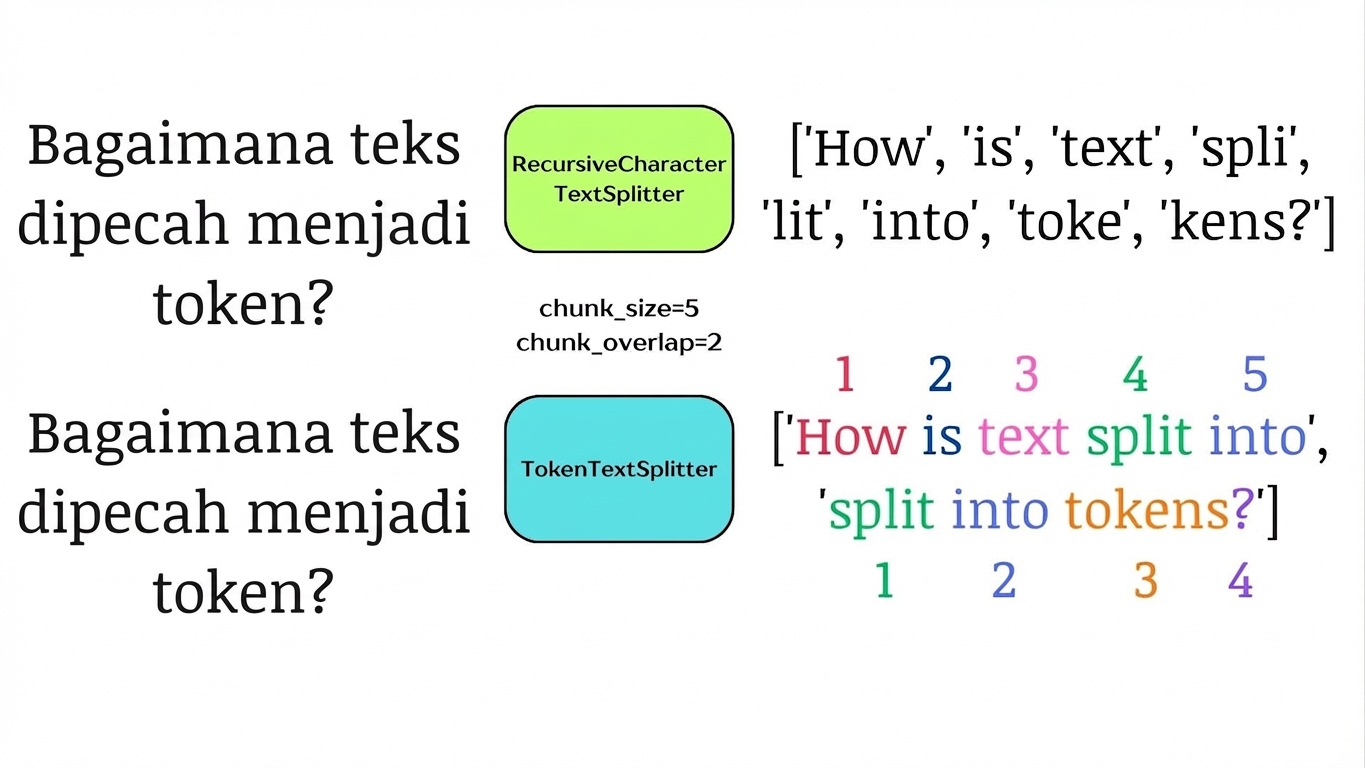
Pemisahan berdasarkan token

Pemisahan berdasarkan token
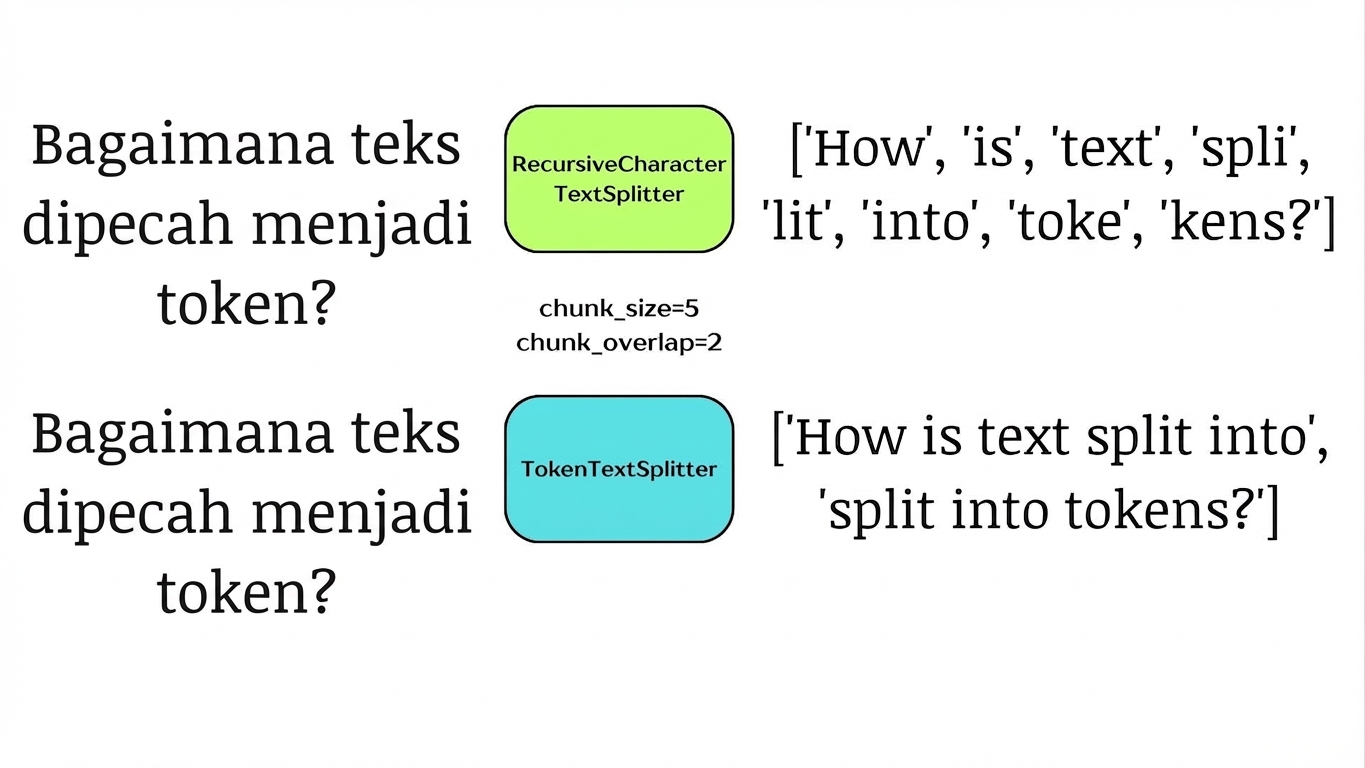
Pemisahan berdasarkan token
Pemisahan semantik

Pemisahan semantik

Pemisahan semantik


