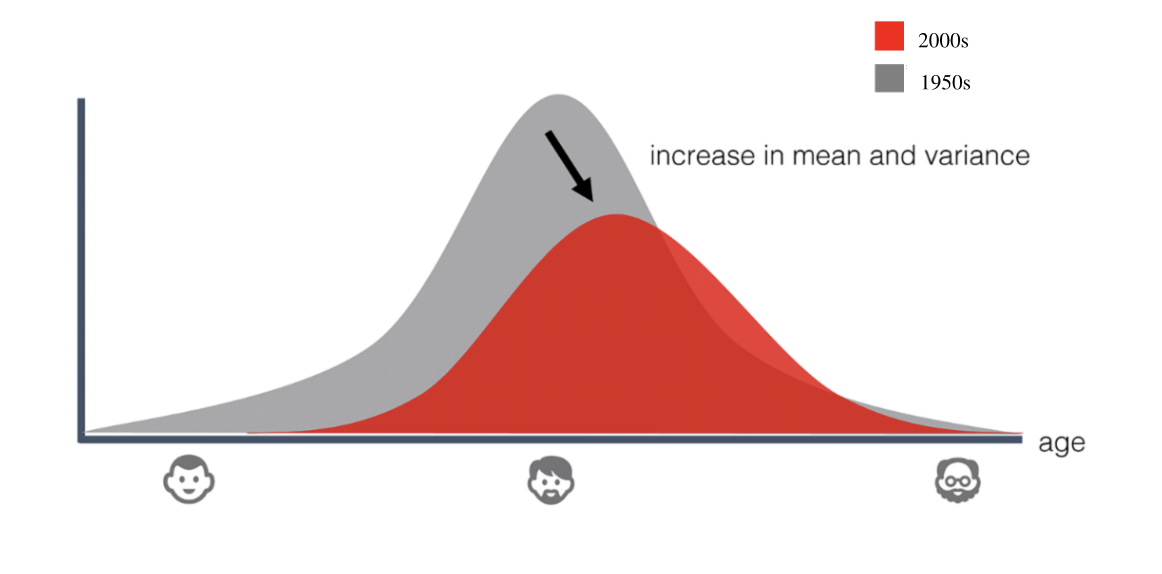
Perubahan data (data drift)
Machine Learning Ujung ke Ujung

Joshua Stapleton
Machine Learning Engineer
Kebutuhan deteksi data drift
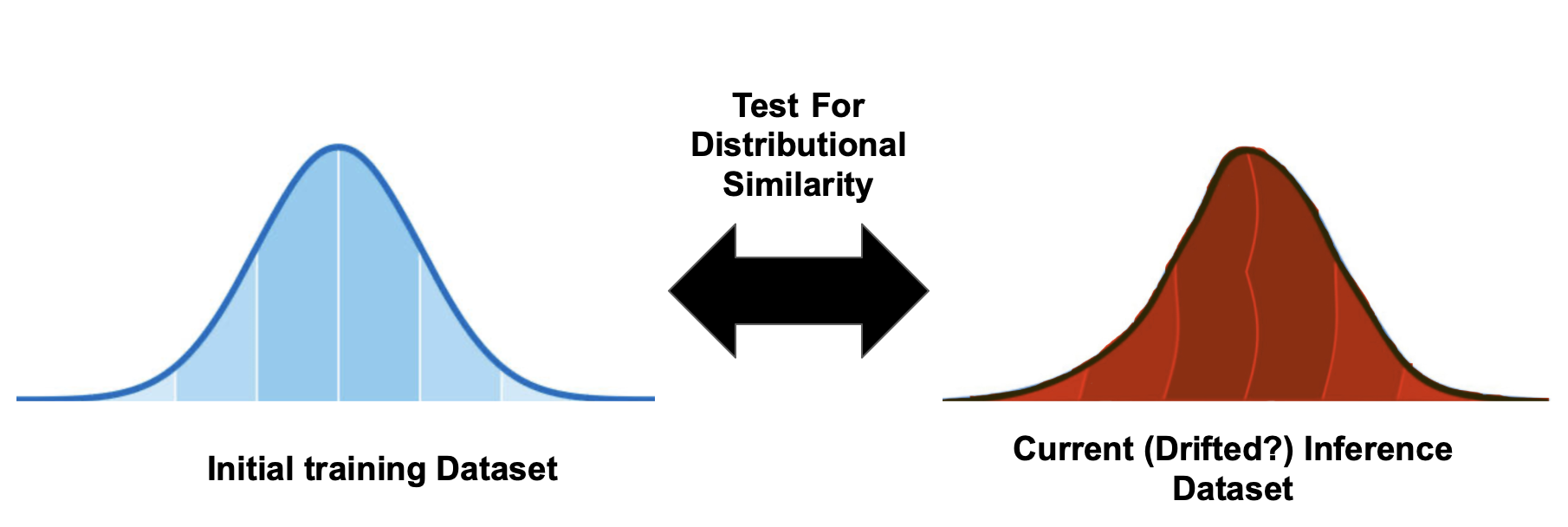
Uji Kolmogorov–Smirnov
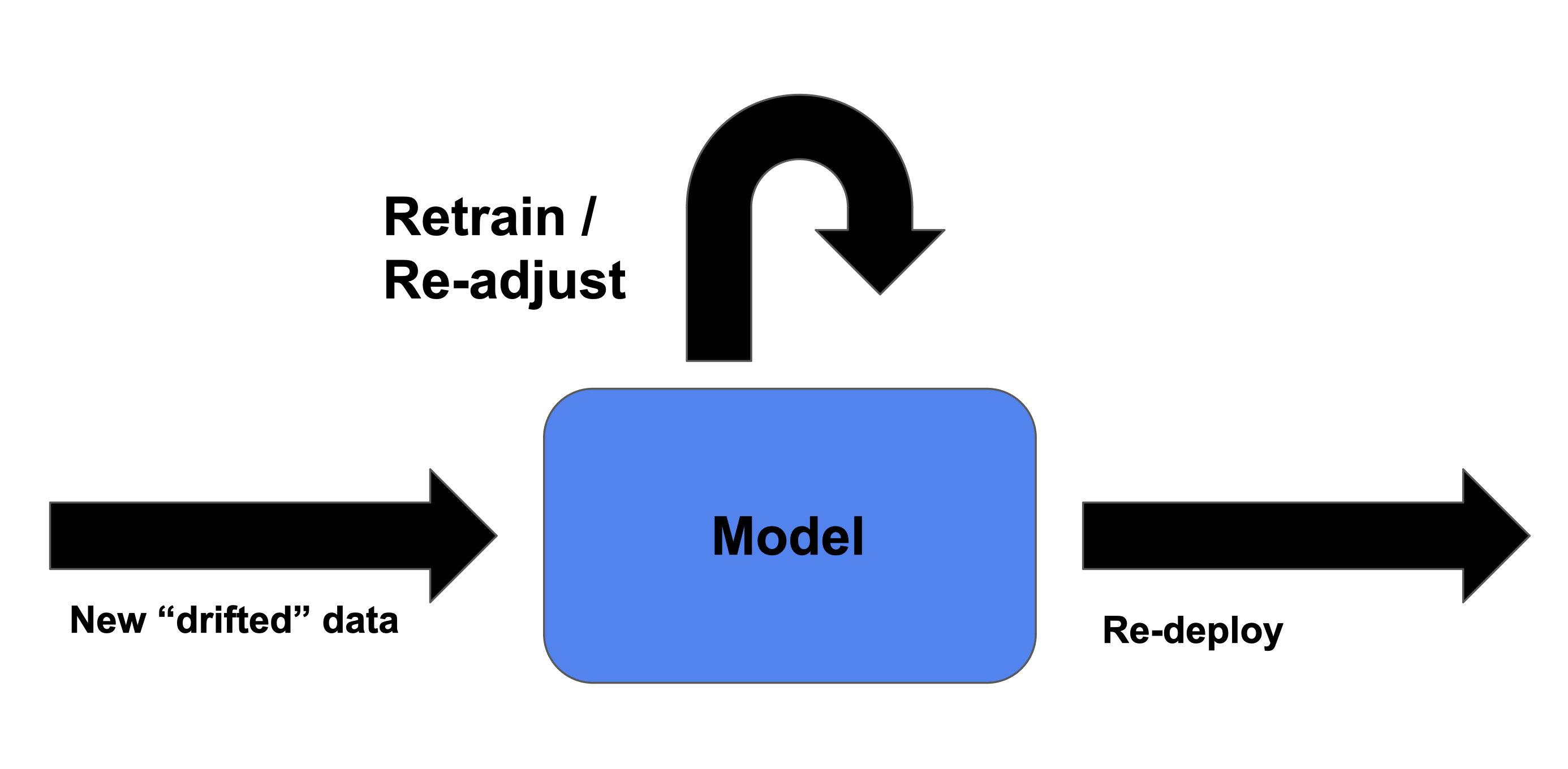
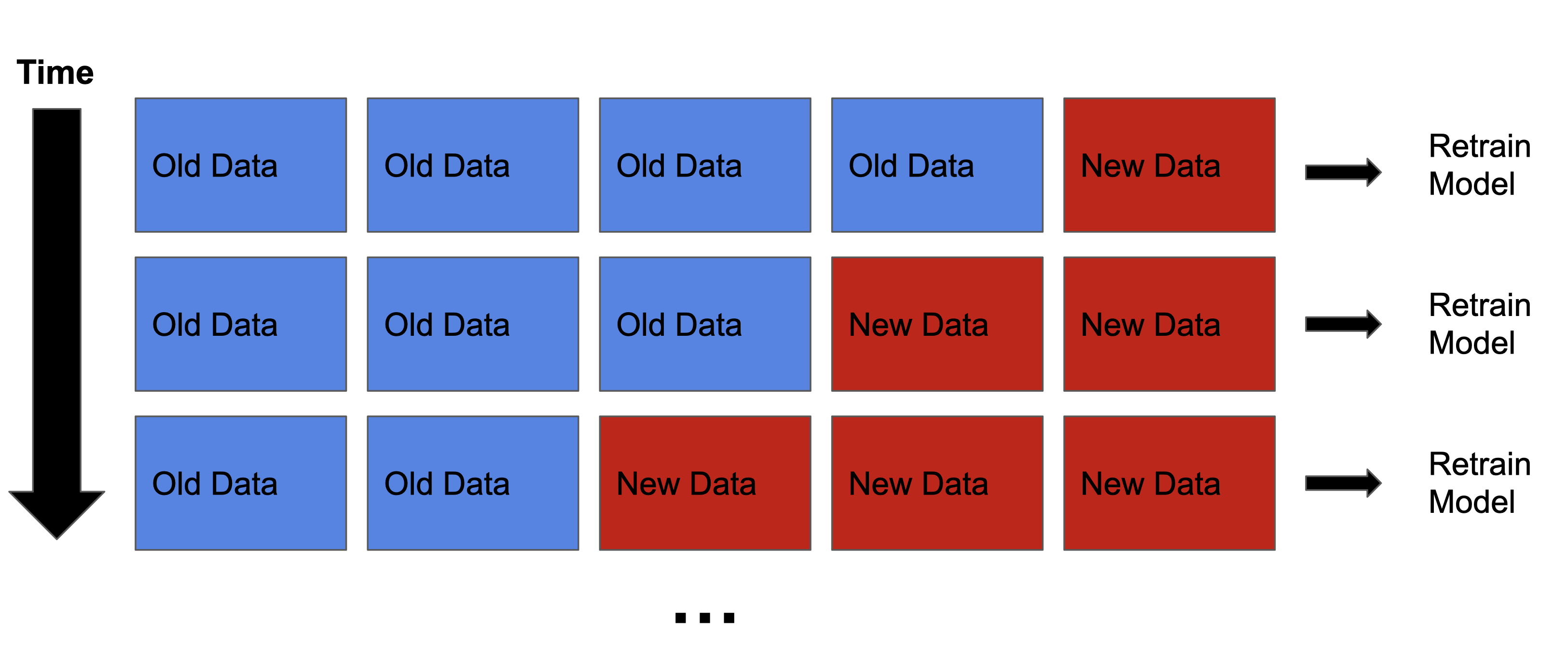
Mengoreksi data drift
Machine Learning Ujung ke Ujung
Joshua Stapleton
Machine Learning Engineer

