Evaluasi dan visualisasi model
Machine Learning Ujung ke Ujung

Joshua Stapleton
Machine Learning Engineer
Akurasi
- Metrik akurasi yang tepat penting untuk evaluasi model yang andal
- Mudah disalahartikan atau menutupi hasil
Akurasi standar:
- Akurasi standar = jumlah benar / jumlah prediksi
- Sering kurang informatif
Contoh:
# achieves ~99% accuracy for imbalanced dataset of 99 positive and 1 negative
for patient_datapoint in heart_disease_dataset:
model.prediction(patient_datapoint) = 'positive'
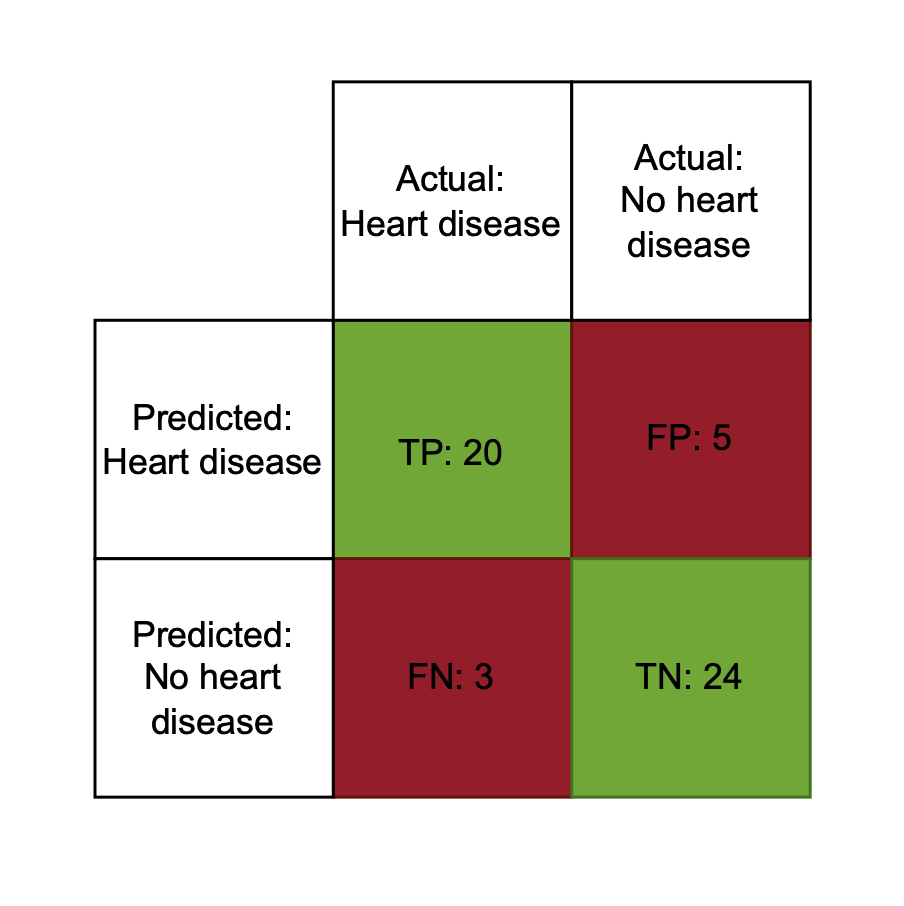
Confusion matrix
True positives (TP)
- Prediksi model = kelas aktual = positif
- Model memprediksi penyakit jantung, pasien benar-benar sakit jantung
False positives (FP)
- Prediksi model = positif, kelas aktual = negatif
- Model memprediksi penyakit jantung, pasien tidak sakit jantung
False negatives (FN)
- Prediksi model = negatif, kelas aktual = positif
- Model memprediksi tidak sakit jantung, pasien sakit jantung
True negatives (TN)
- Prediksi model = kelas aktual = negatif
- Model memprediksi tidak sakit jantung, pasien tidak sakit jantung
Balanced accuracy
- Lebih baik daripada akurasi biasa untuk sebagian besar model klasifikasi biner
- Rata-rata tertimbang di dua kelas
- Balanced accuracy = (TP + TN) / 2
from sklearn.metrics import balanced_accuracy_score
# Assume y_test is the true labels and y_pred are the predicted labels
y_pred = model.predict(X_test)
bal_accuracy = balanced_accuracy_score(y_test, y_pred)
print(f"Balanced Accuracy: {bal_accuracy:.2f}")
Balanced Accuracy: 0.85
Penggunaan confusion matrix
Cross validation
Cross-validation
- Prosedur resampling
- Memastikan hasil lebih andal
k-fold cross-validation
- Parameter 'k' = jumlah pembagian dataset
- Resampling train/test baru tiap run pemodelan
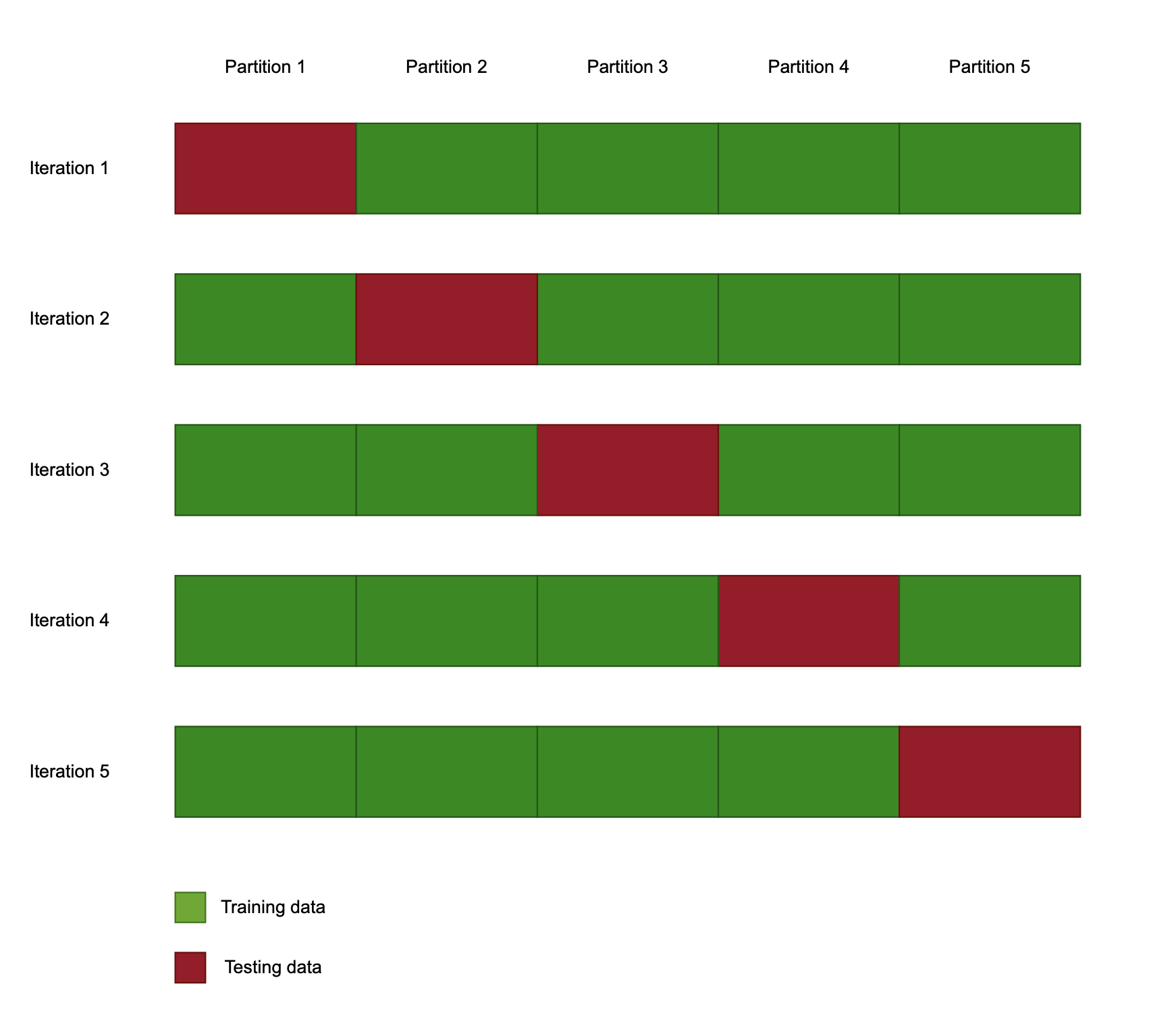
Penggunaan cross validation
- Implementasi k-fold cross validation yang sederhana dengan sklearn
- Skor agnostik model
Penggunaan:
from sklearn.model_selection import cross_val_score, KFold # split the data into 10 equal parts kfold = KFold(n_splits=5, shuffle=True, random_state=42)# get the cross validation accuracy for a given model cv_results = cross_val_score(model, heart_disease_X, heart_disease_y, cv=kfold, scoring='balanced_accuracy')
Penyetelan hyperparameter
Hyperparameter:
- Parameter global model (tidak berubah saat training)
- Disetel untuk meningkatkan kinerja model
# Hyperparameters to test
C_values = [0.001, 0.01, 0.1, 1, 10, 100, 1000]
# Manually iterate over the hyperparameters
for C in C_values:
model = LogisticRegression(max_iter=200, C=C)
model.fit(X_train, y_train)
accuracy = cross_val_score(model, X, y, cv=kfold, scoring='balanced_accuracy')
print(f"C = {C}: Bal Acc: {accuracy.mean():.4f} (+/- {accuracy.std():.4f})")
Contoh penyetelan hyperparameter
Contoh output penyetelan hyperparameter:
C = 0.001: Bal Acc: 0.6200 (+/- 0.0215)
C = 0.01: Bal Acc: 0.7325 (+/- 0.0234)
C = 0.1: Bal Acc: 0.7923 (+/- 0.0202)
C = 1: Bal Acc: 0.8050 (+/- 0.0191)
C = 10: Bal Acc: 0.8034 (+/- 0.0185)
C = 100: Bal Acc: 0.8021 (+/- 0.0187)
C = 1000: Bal Acc: 0.8017 (+/- 0.0188)
Ayo berlatih!
Machine Learning Ujung ke Ujung

