Fundamental Big Data dengan PySpark
Upendra Devisetty
Science Analyst, CyVerse
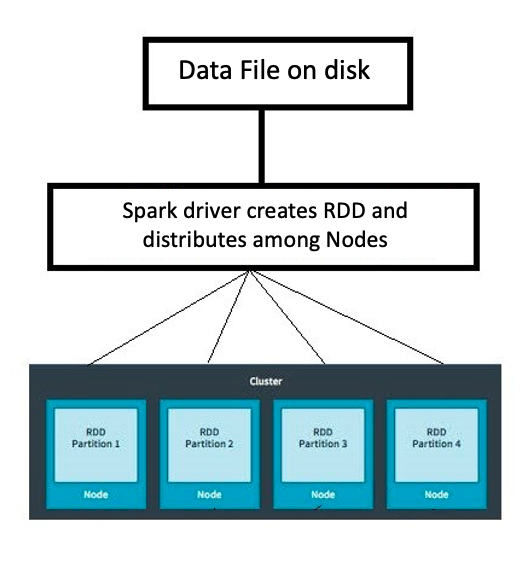
Resilient Distributed Datasets
Resilient: Tahan terhadap kegagalan
Distributed: Meliputi banyak mesin
Datasets: Kumpulan data terpartisi, mis. Array, Tabel, Tuple, dll.
Memparalelkan koleksi objek yang sudah ada
Dataset eksternal:
File di HDFS
Objek di bucket Amazon S3
Baris dalam file teks
Dari RDD yang sudah ada
parallelize()
numRDD = sc.parallelize([1,2,3,4])
helloRDD = sc.parallelize("Hello world")
type(helloRDD)
<class 'pyspark.rdd.PipelinedRDD'>
textFile()
fileRDD = sc.textFile("README.md")
type(fileRDD)
Partisi adalah pembagian logis dari himpunan data terdistribusi besar
Metode parallelize()
numRDD = sc.parallelize(range(10), minPartitions = 6)
fileRDD = sc.textFile("README.md", minPartitions = 6)
getNumPartitions()