Operasi RDD di PySpark
Fundamental Big Data dengan PySpark

Upendra Devisetty
Science Analyst, CyVerse
Gambaran operasi PySpark

- Transformasi membuat RDD baru
- Aksi menjalankan komputasi pada RDD
Transformasi RDD
- Transformasi dievaluasi secara lazy (Lazy evaluation)

Transformasi RDD dasar
map(),filter(),flatMap(), danunion()
Transformasi map()
- Transformasi map() menerapkan fungsi ke semua elemen RDD
![]()
RDD = sc.parallelize([1,2,3,4])
RDD_map = RDD.map(lambda x: x * x)
Transformasi filter()
- Transformasi filter mengembalikan RDD baru hanya dengan elemen yang lolos kondisi

RDD = sc.parallelize([1,2,3,4])
RDD_filter = RDD.filter(lambda x: x > 2)
Transformasi flatMap()
- Transformasi flatMap() mengembalikan banyak nilai untuk tiap elemen RDD asal
![]()
RDD = sc.parallelize(["hello world", "how are you"])
RDD_flatmap = RDD.flatMap(lambda x: x.split(" "))
Transformasi union()
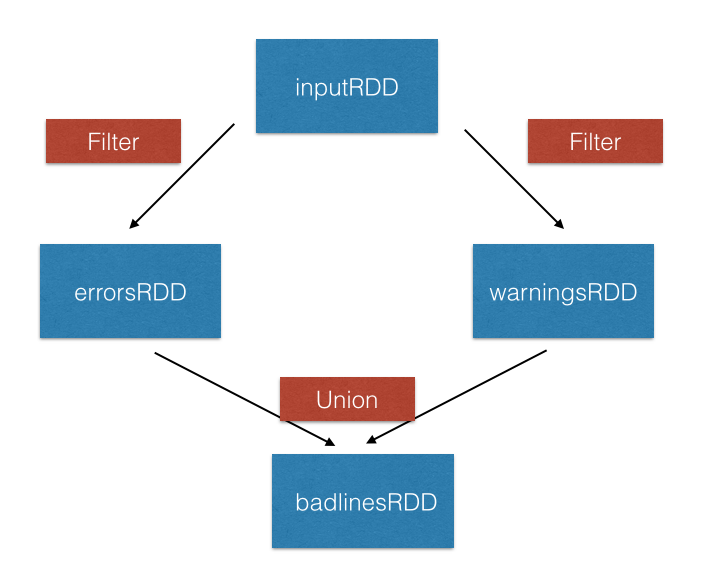
inputRDD = sc.textFile("logs.txt")
errorRDD = inputRDD.filter(lambda x: "error" in x.split())
warningsRDD = inputRDD.filter(lambda x: "warnings" in x.split())
combinedRDD = errorRDD.union(warningsRDD)

