Klasifikasi
Fundamental Big Data dengan PySpark

Upendra Devisetty
Science Analyst, CyVerse
Klasifikasi dengan PySpark MLlib
- Klasifikasi adalah pembelajaran terawasi untuk mengelompokkan data ke kategori berbeda
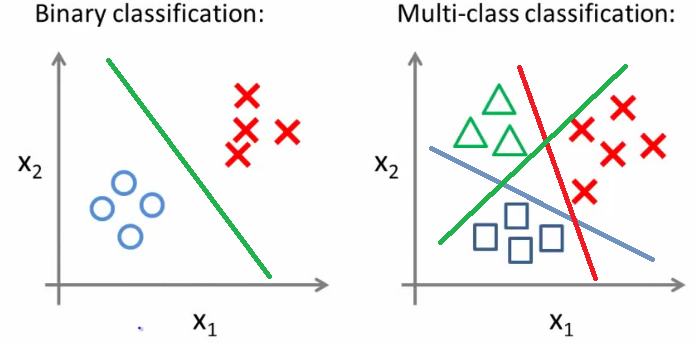
Pengantar Regresi Logistik
- Regresi Logistik memprediksi respons biner dari beberapa variabel