Metode Monte Carlo
Reinforcement Learning dengan Gymnasium di Python

Fouad Trad
Machine Learning Engineer
Rekap: pembelajaran berbasis model
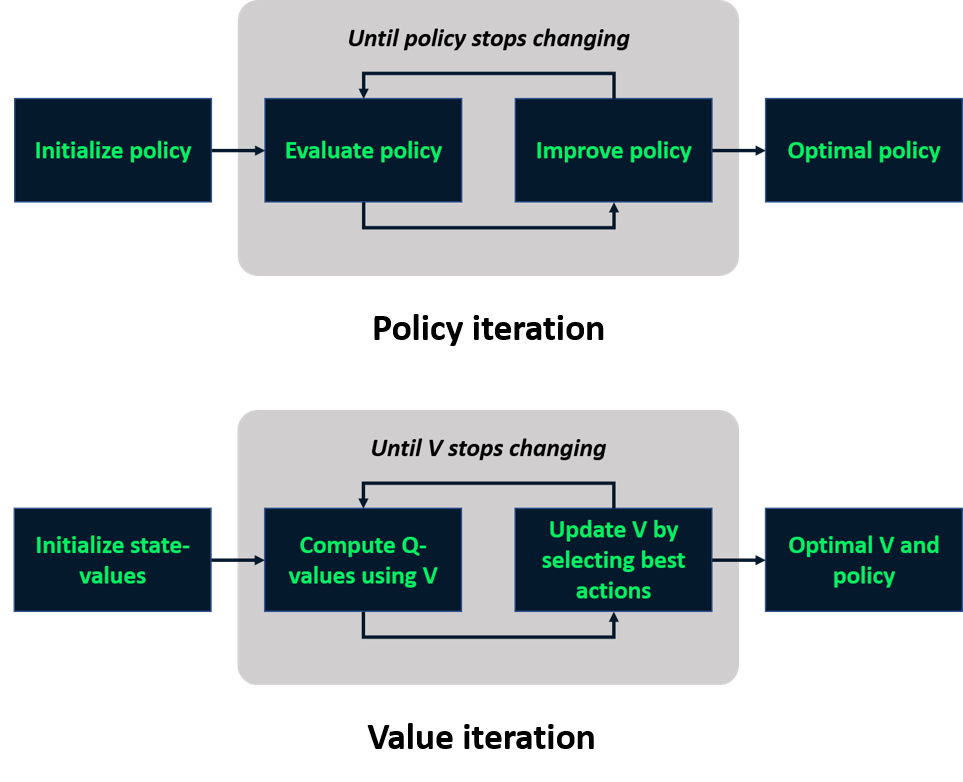
Pembelajaran tanpa model

Metode Monte Carlo
- Teknik tanpa model
- Estimasi nilai Q berbasis episode
Metode Monte Carlo
- Teknik tanpa model
- Estimasi nilai Q berbasis episode

Metode Monte Carlo
- Teknik tanpa model
- Estimasi nilai Q berbasis episode

- Dua metode: kunjungan-pertama, setiap-kunjungan
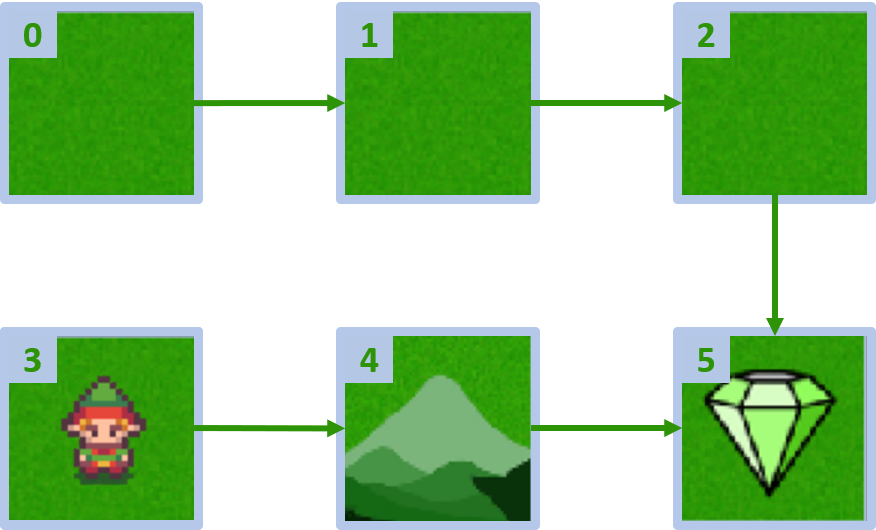
Dunia kisi kustom
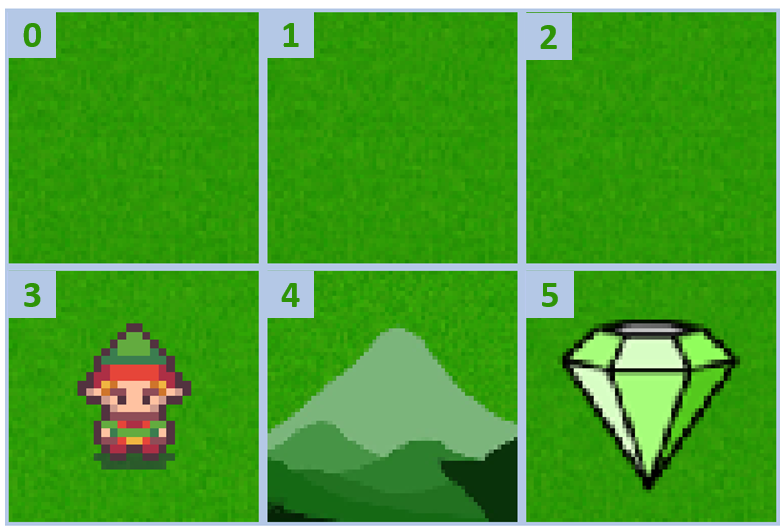
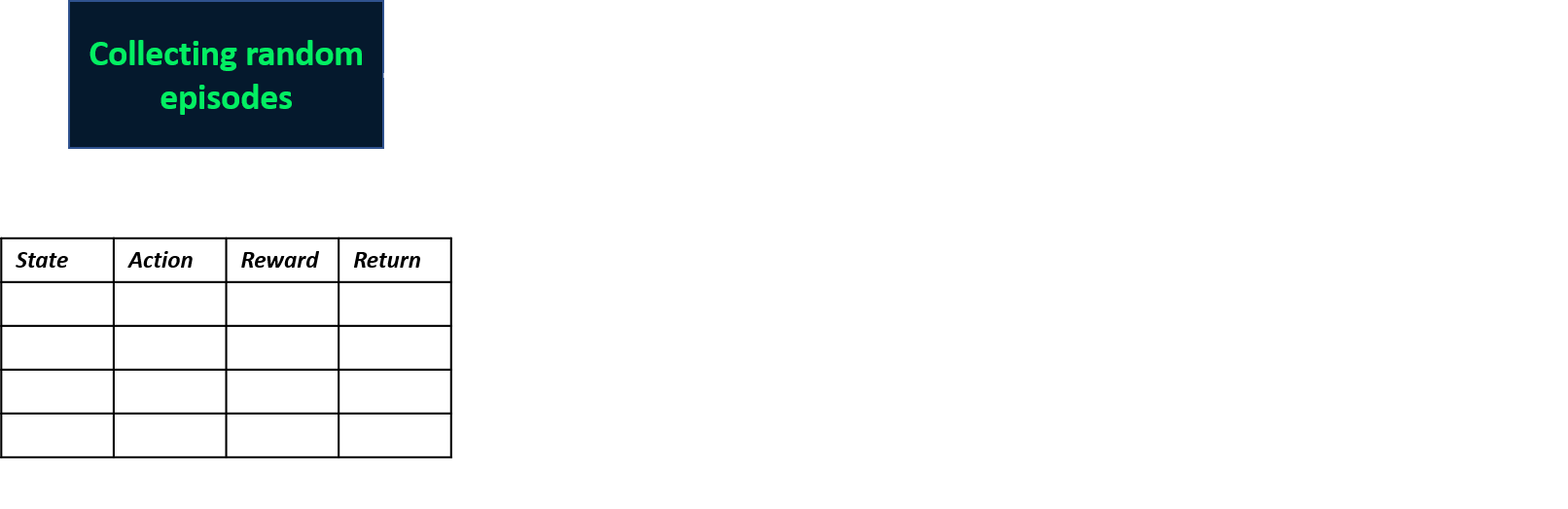
Mengumpulkan dua episode
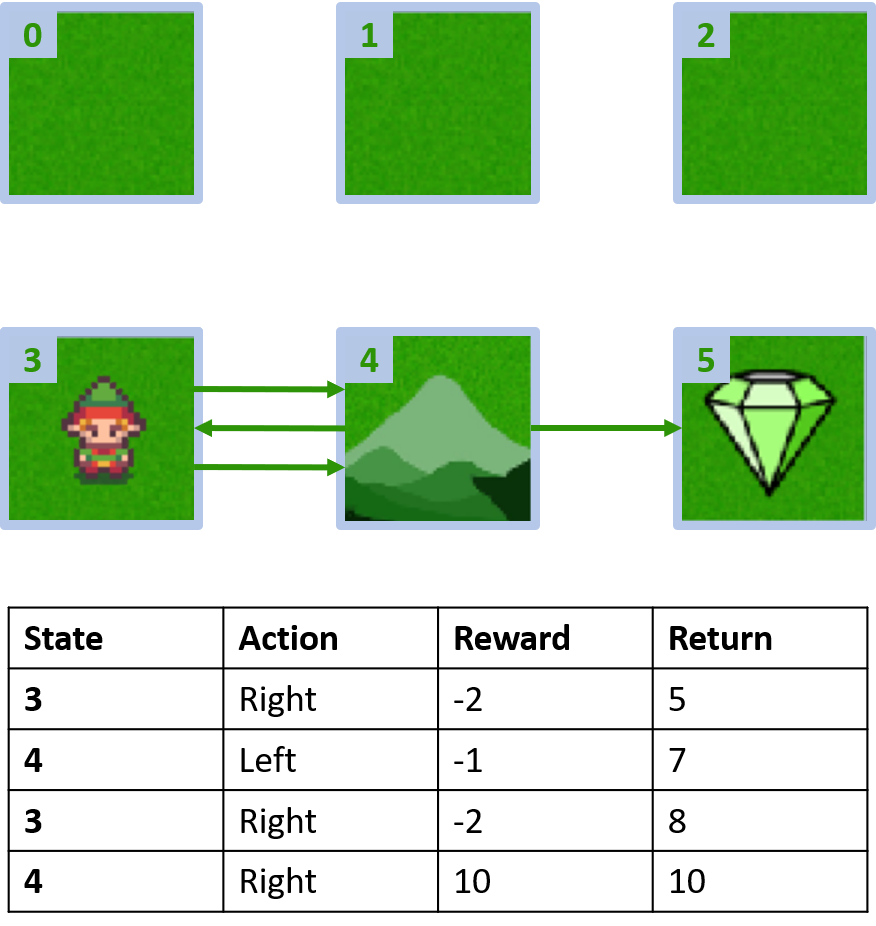
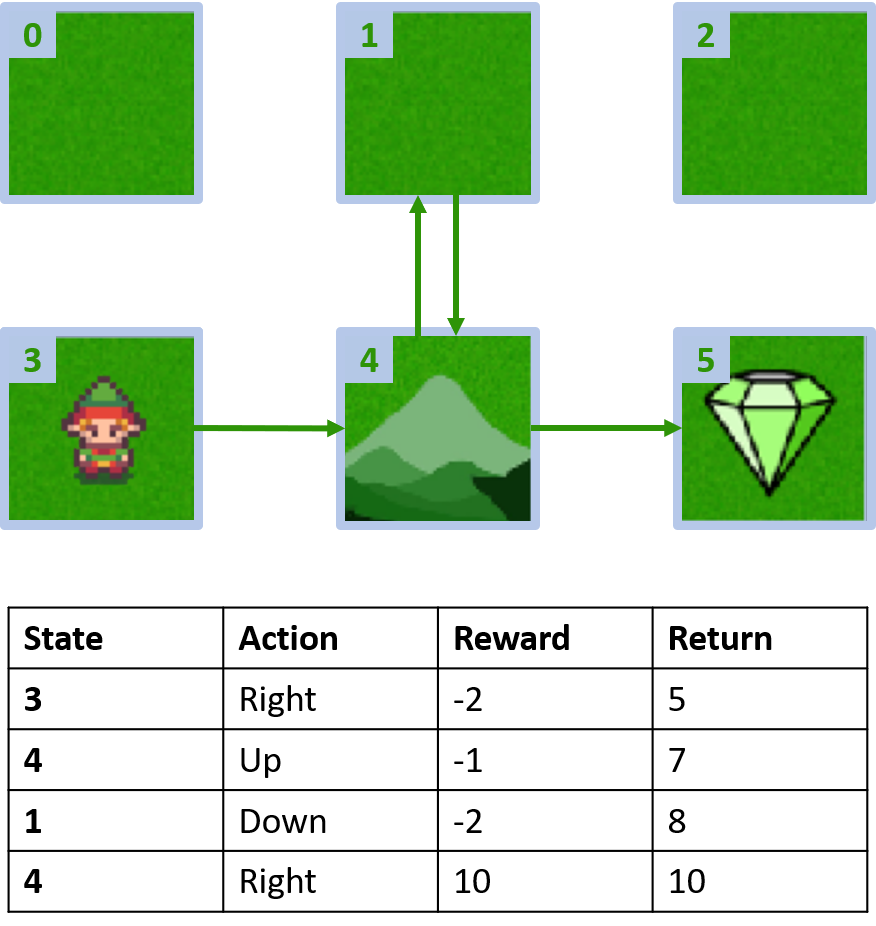
Mengestimasi nilai Q
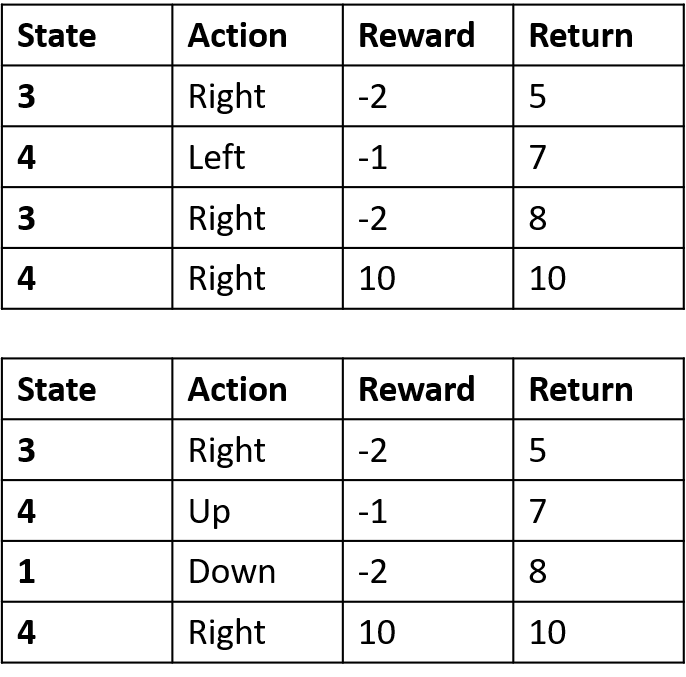
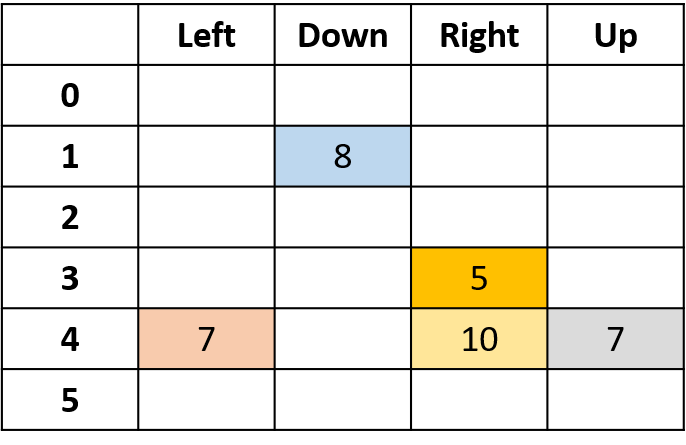
- Tabel Q: tabel untuk nilai Q
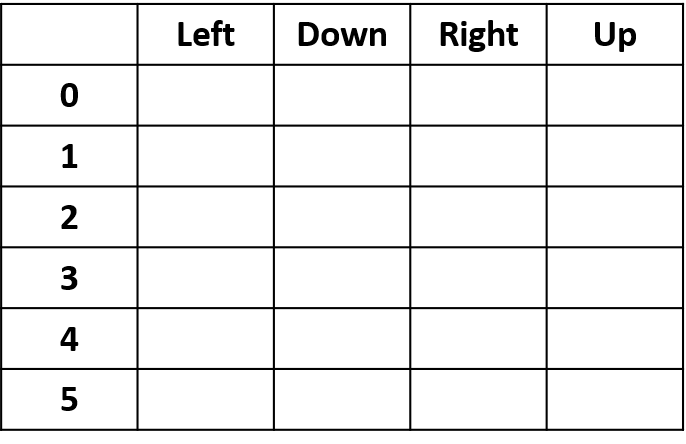
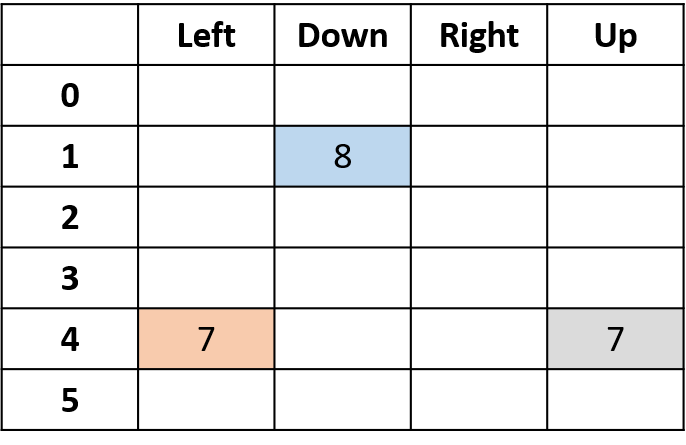
Q(4, kiri), Q(4, atas), dan Q(1, bawah)
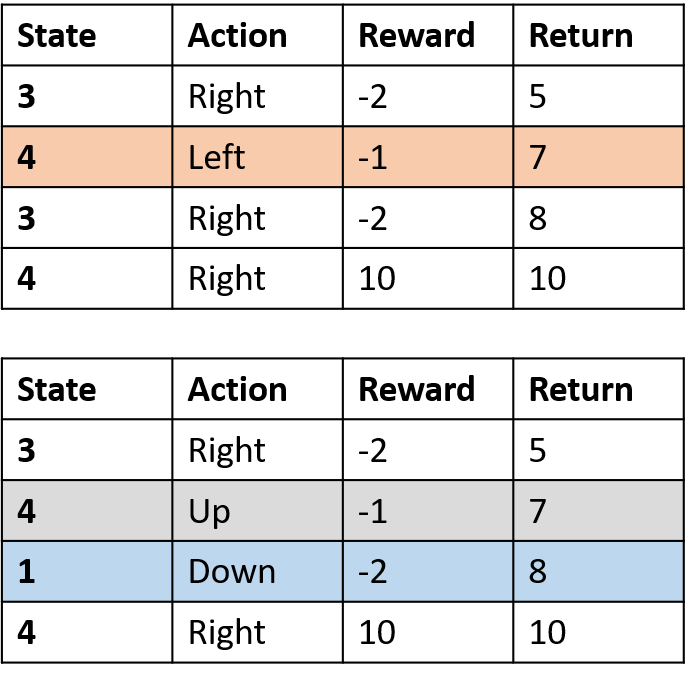
- (s,a) muncul sekali -> isi dengan return
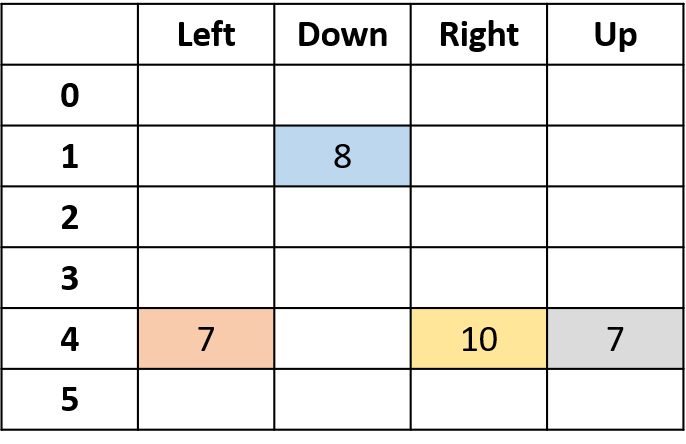
Q(4, kanan)
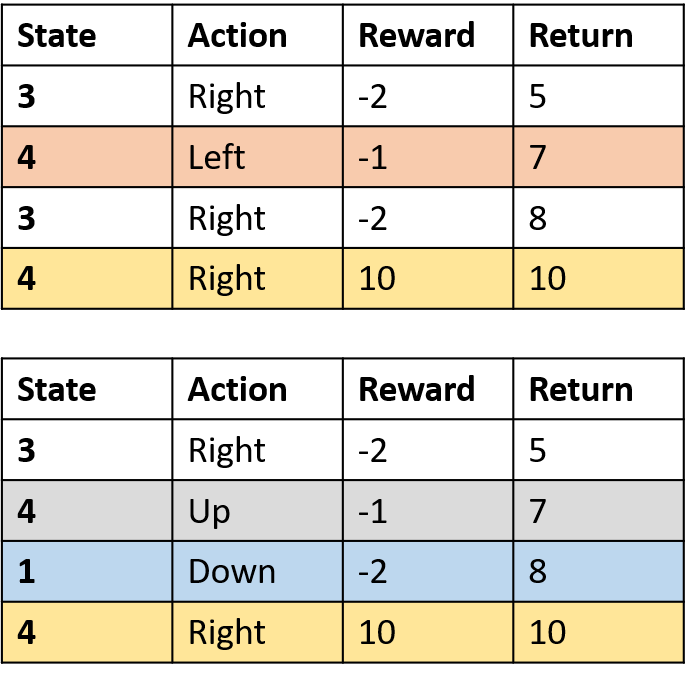
- (s,a) terjadi sekali per episode -> rata-rata
Q(3, kanan) - Monte Carlo kunjungan-pertama
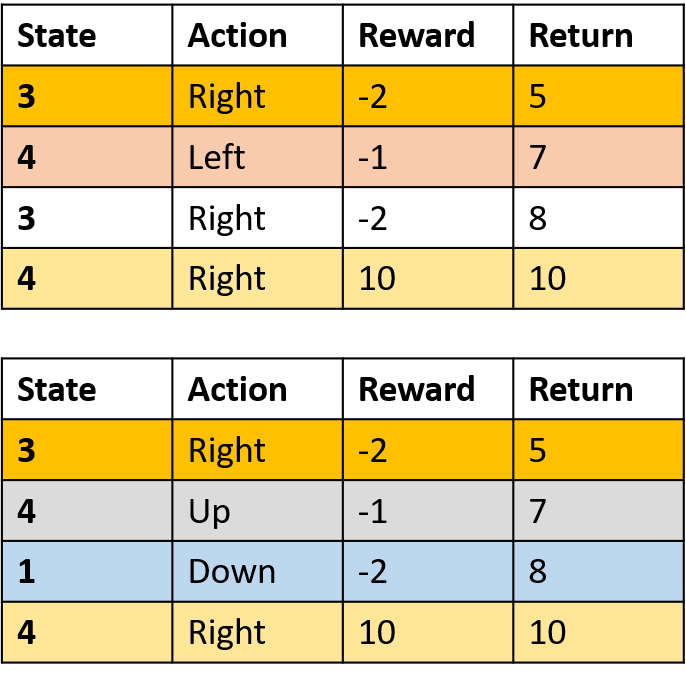
- Rata-rata kunjungan pertama ke (s,a) dalam episode
Q(3, kanan) - Monte Carlo setiap-kunjungan
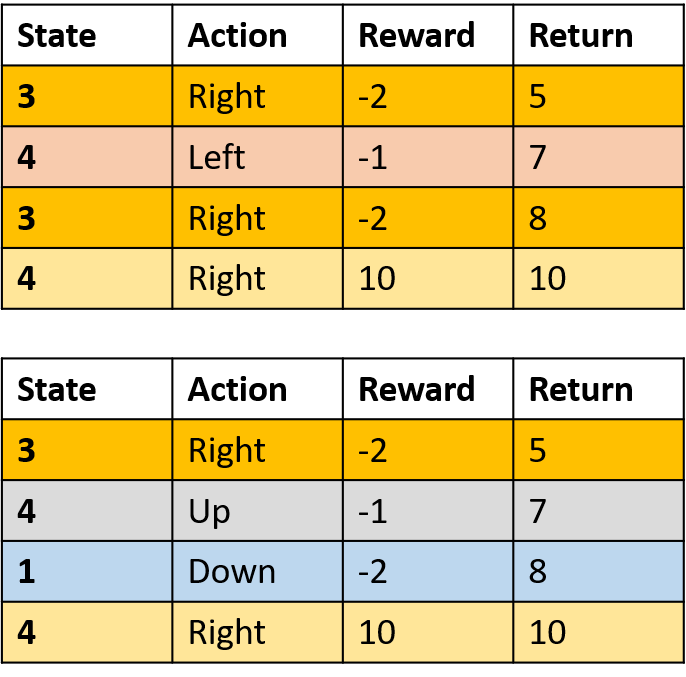
- Rata-rata setiap kunjungan ke (s,a) dalam episode
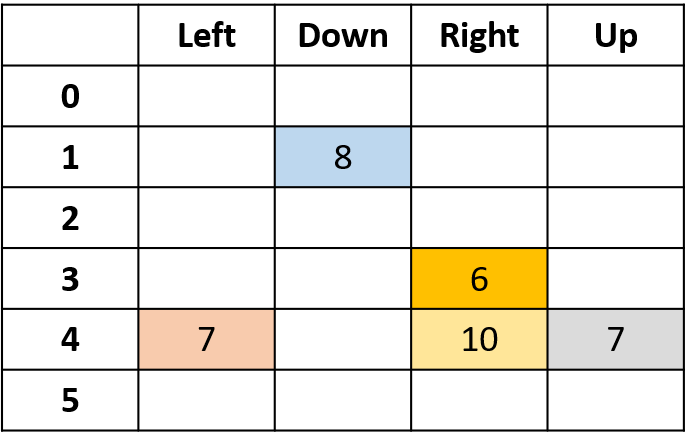
Menggabungkan semuanya