Menyeimbangkan eksplorasi dan eksploitasi
Reinforcement Learning dengan Gymnasium di Python

Fouad Trad
Machine Learning Engineer
Pelatihan dengan aksi acak

Trade-off eksplorasi-eksploitasi

Pilihan tempat makan

Strategi epsilon-greedy
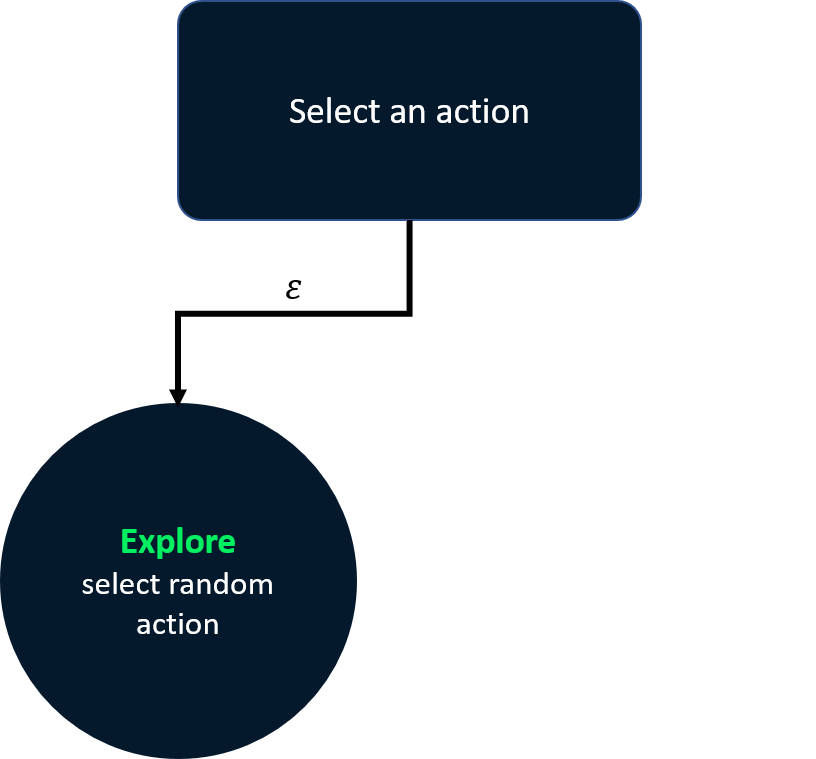
Strategi epsilon-greedy
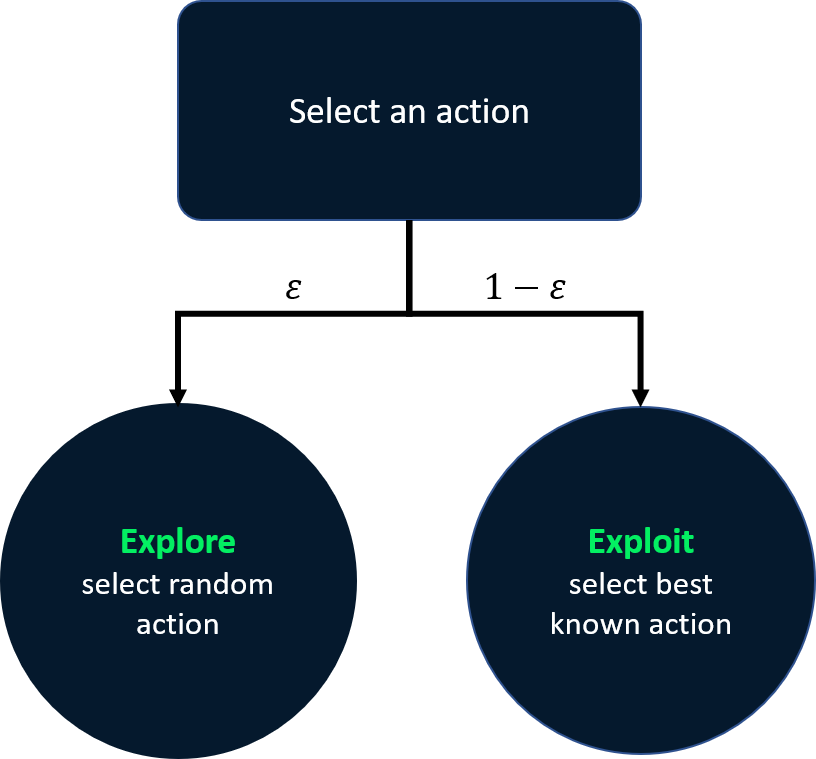
Strategi epsilon-greedy dengan peluruhan

Implementasi dengan Frozen Lake

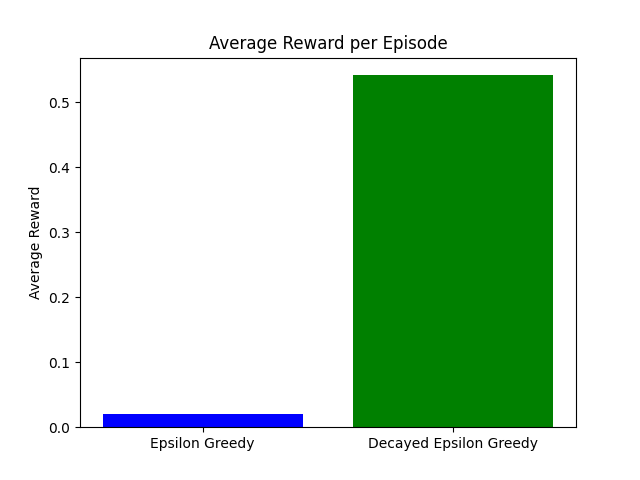
Membandingkan strategi