Double Q-learning
Reinforcement Learning dengan Gymnasium di Python

Fouad Trad
Machine Learning Engineer
Q-learning
- Mengestimasi fungsi nilai-aksi optimal
- Cenderung melebihkan Q karena pembaruan berbasis nilai Q maksimum
- Dapat menghasilkan kebijakan kurang optimal

Double Q-learning
- Memiliki dua tabel Q
- Tiap tabel diperbarui berdasarkan yang lain
- Mengurangi risiko overestimation nilai Q
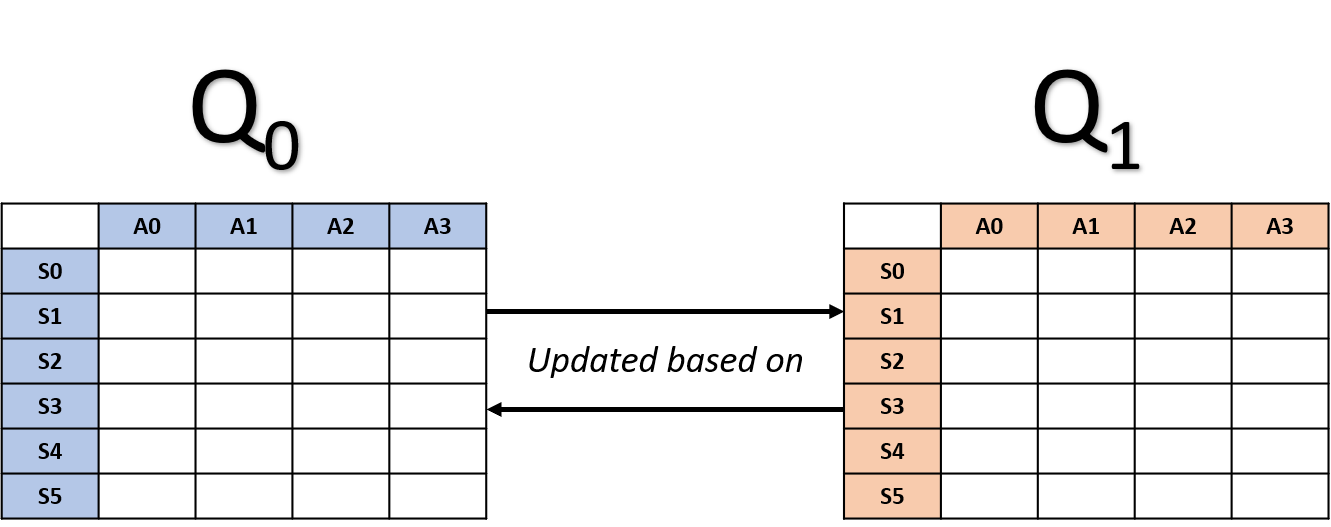
Pembaruan Double Q-learning
- Pilih tabel secara acak
Pembaruan Q0
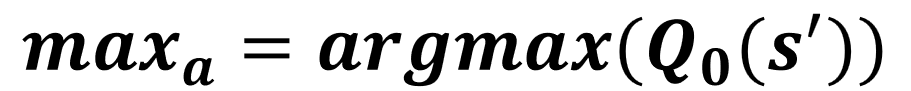
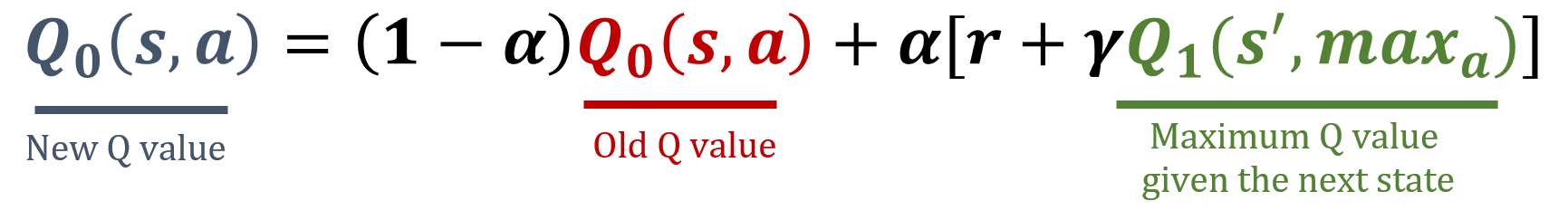
Pembaruan Q1
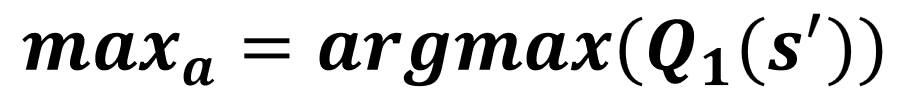
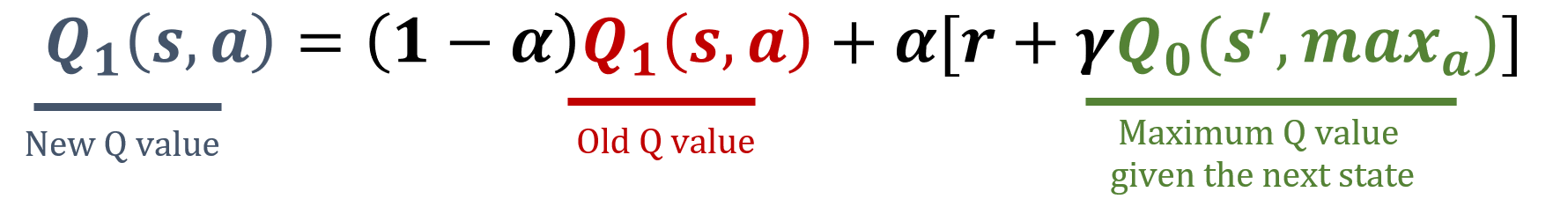
Double Q-learning
- Mengurangi bias overestimation
- Bergantian memperbarui Q0 dan Q1
- Kedua tabel berkontribusi pada pembelajaran
Implementasi dengan Frozen Lake

Mengimplementasikan update_q_tables()
def update_q_tables(state, action, reward, next_state): # Select a random Q-table index (0 or 1) i = np.random.randint(2)# Update the corresponding Q-table best_next_action = np.argmax(Q[i][next_state])Q[i][state, action] = (1 - alpha) * Q[i][state, action] + alpha * (reward + gamma * Q[1-i][next_state, best_next_action])
Kebijakan agen