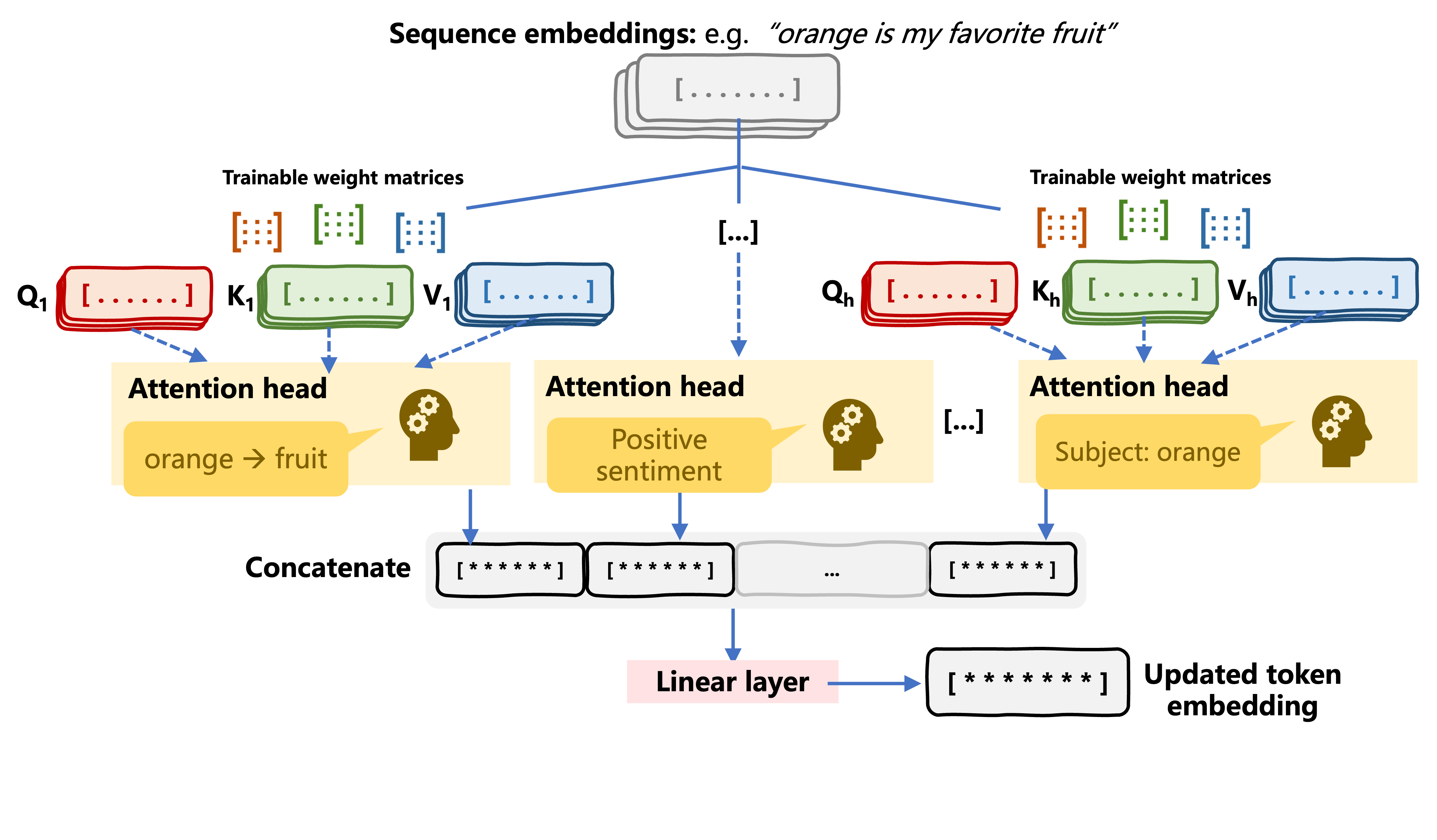
Self-attention multi-kepala
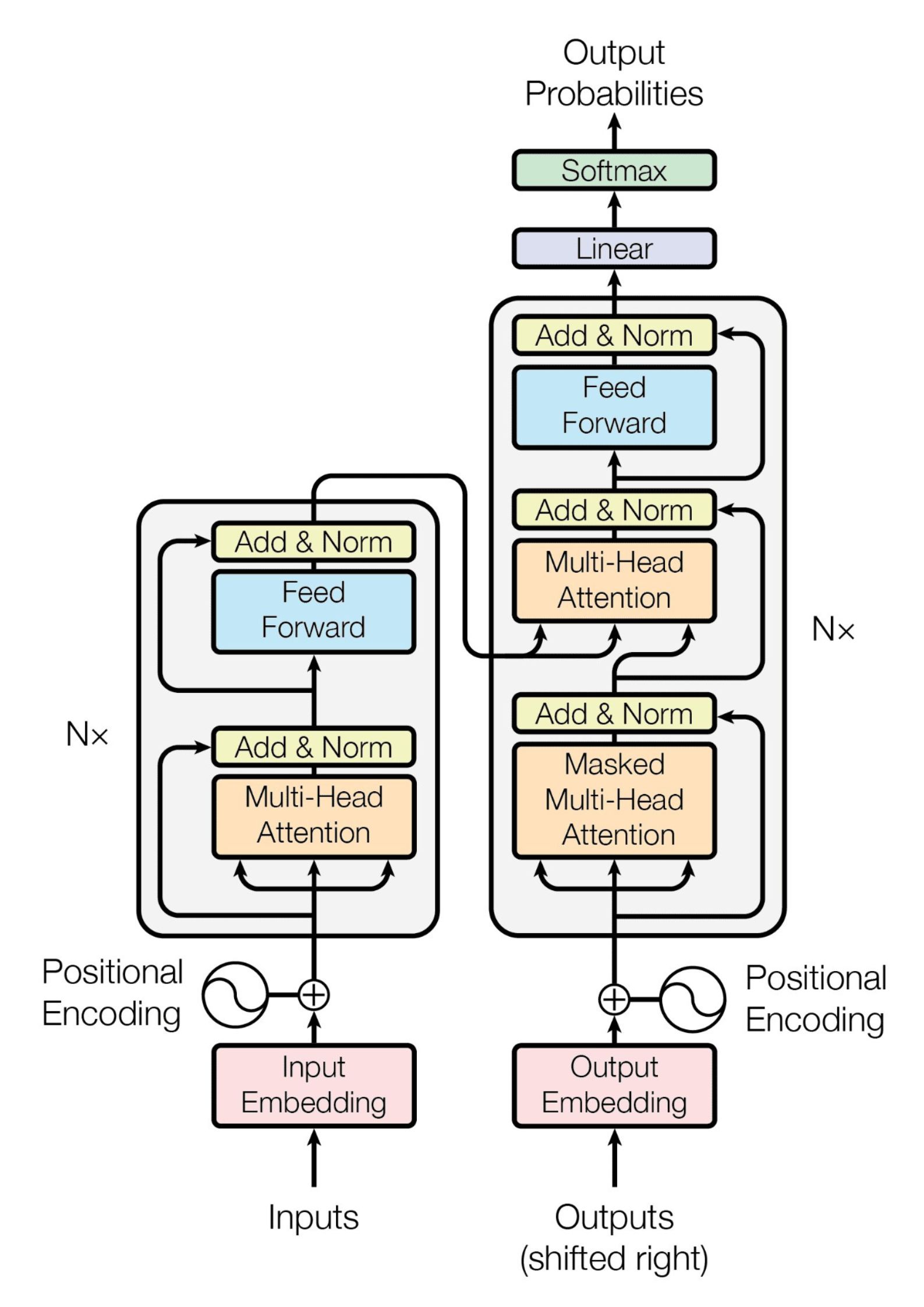
Model Transformer dengan PyTorch

James Chapman
Curriculum Manager, DataCamp
Atensi multi-kepala pada transformer
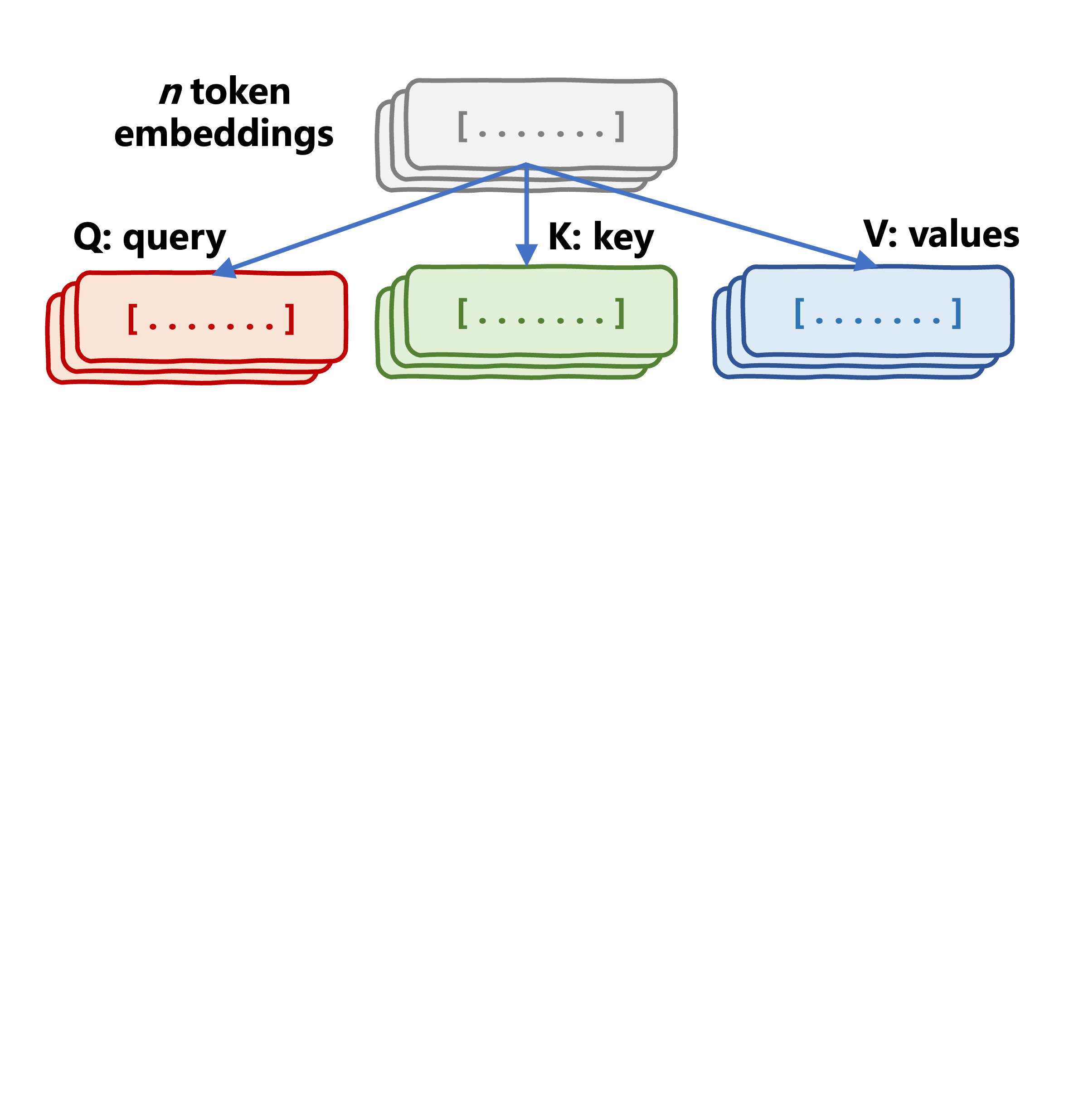
Mekanisme self-attention

Mekanisme self-attention
Mekanisme self-attention
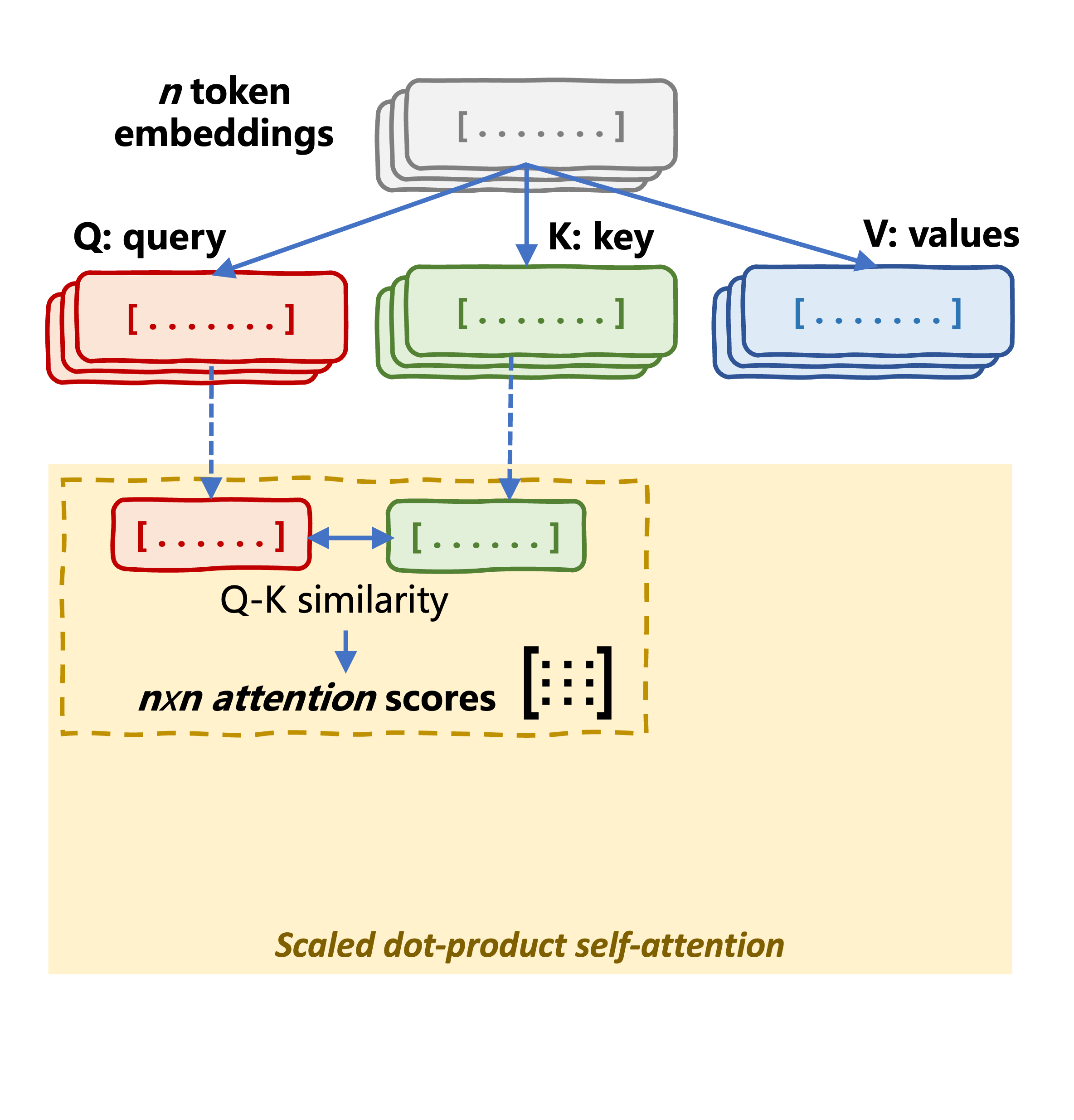
Mekanisme self-attention
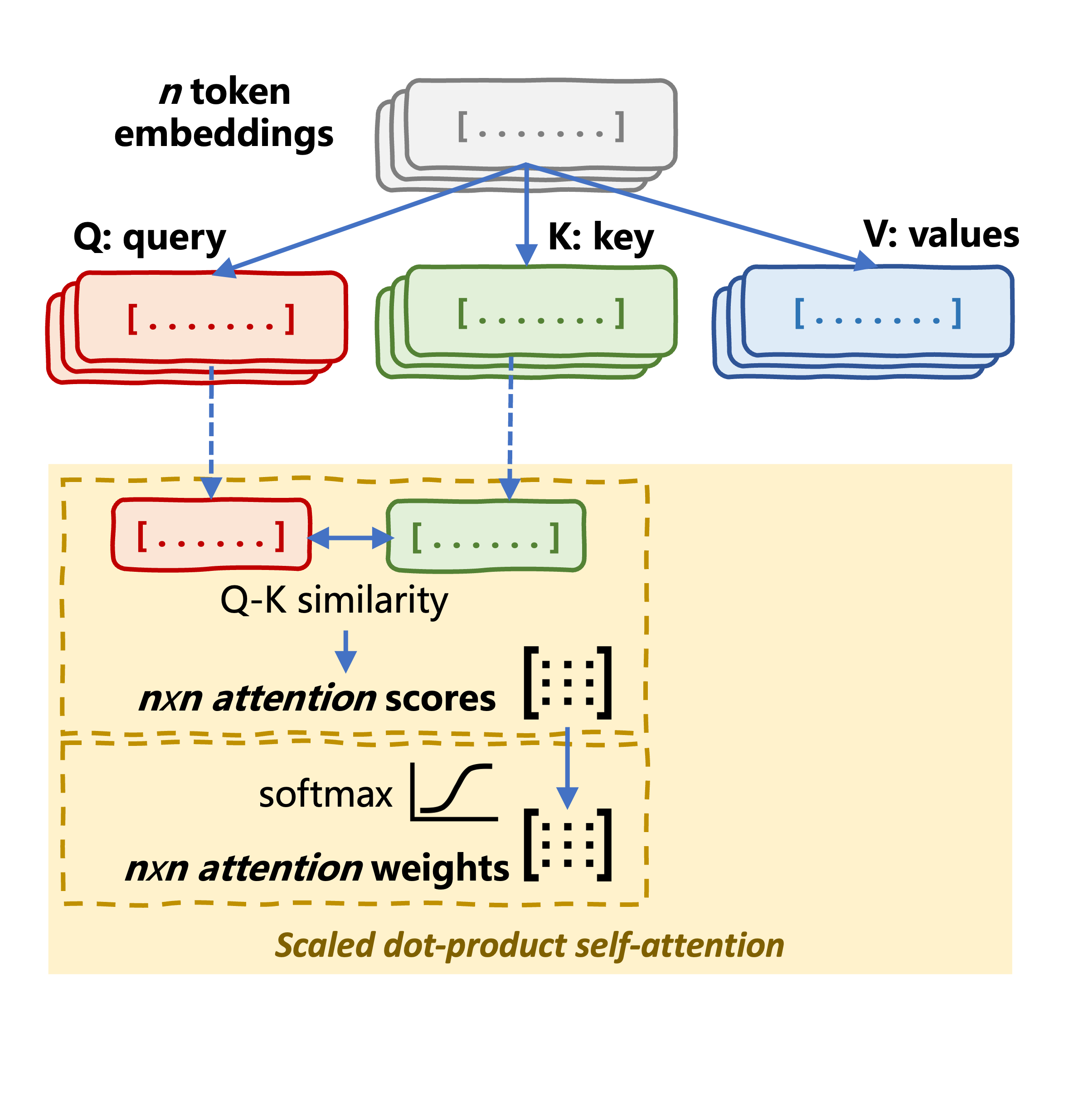
Mekanisme self-attention
Mekanisme self-attention
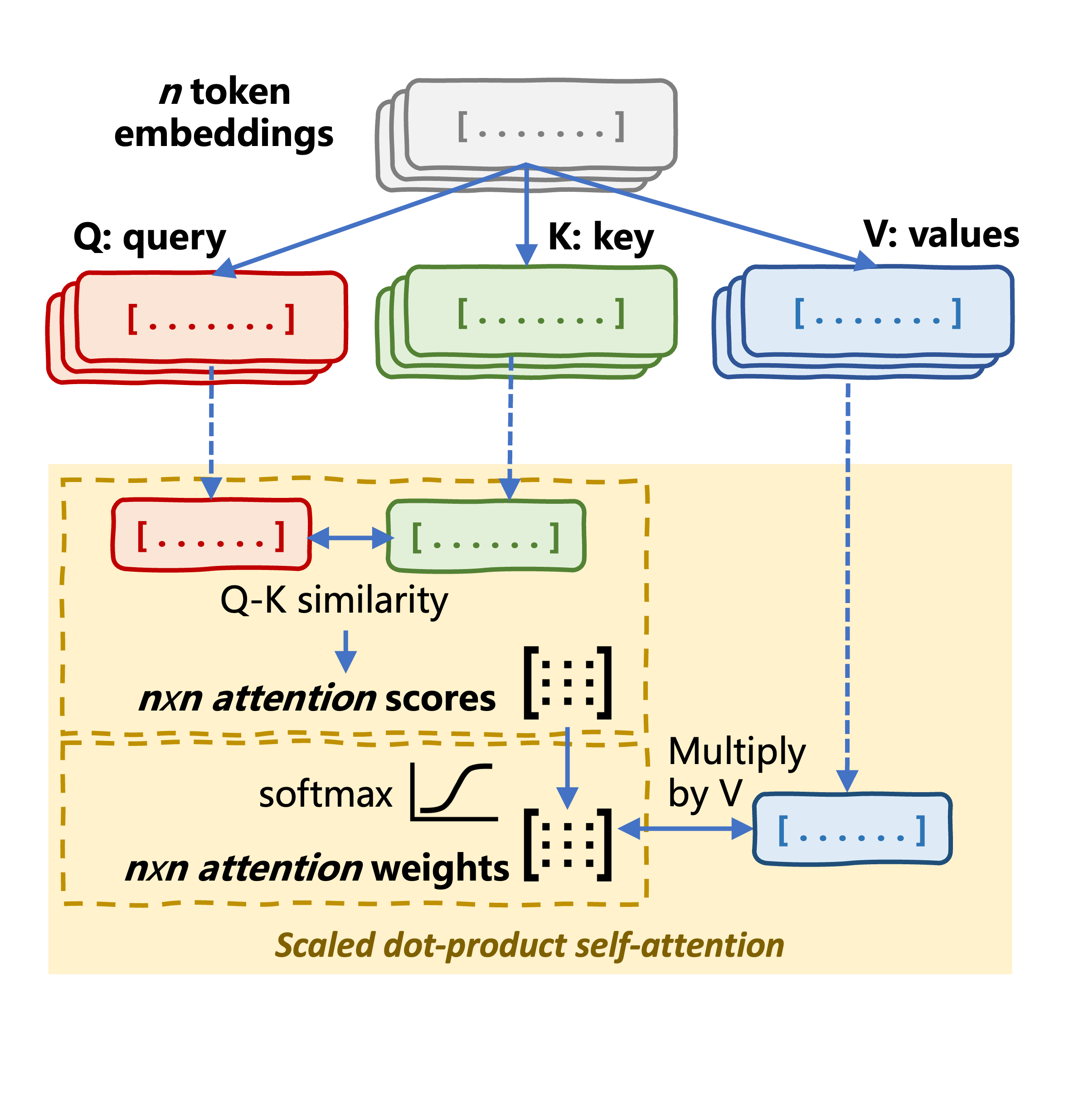
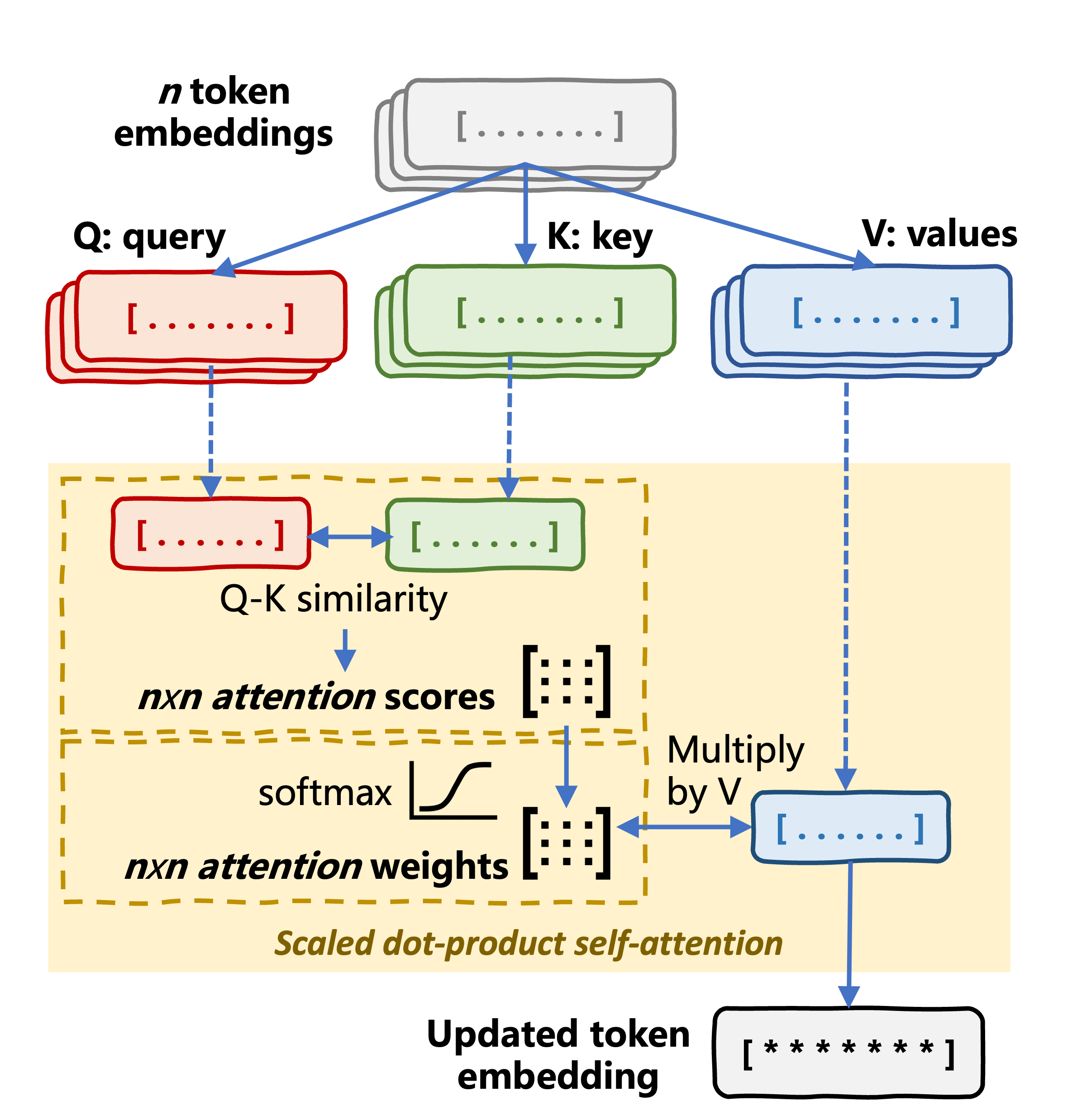
Mekanisme self-attention
Atensi multi-kepala
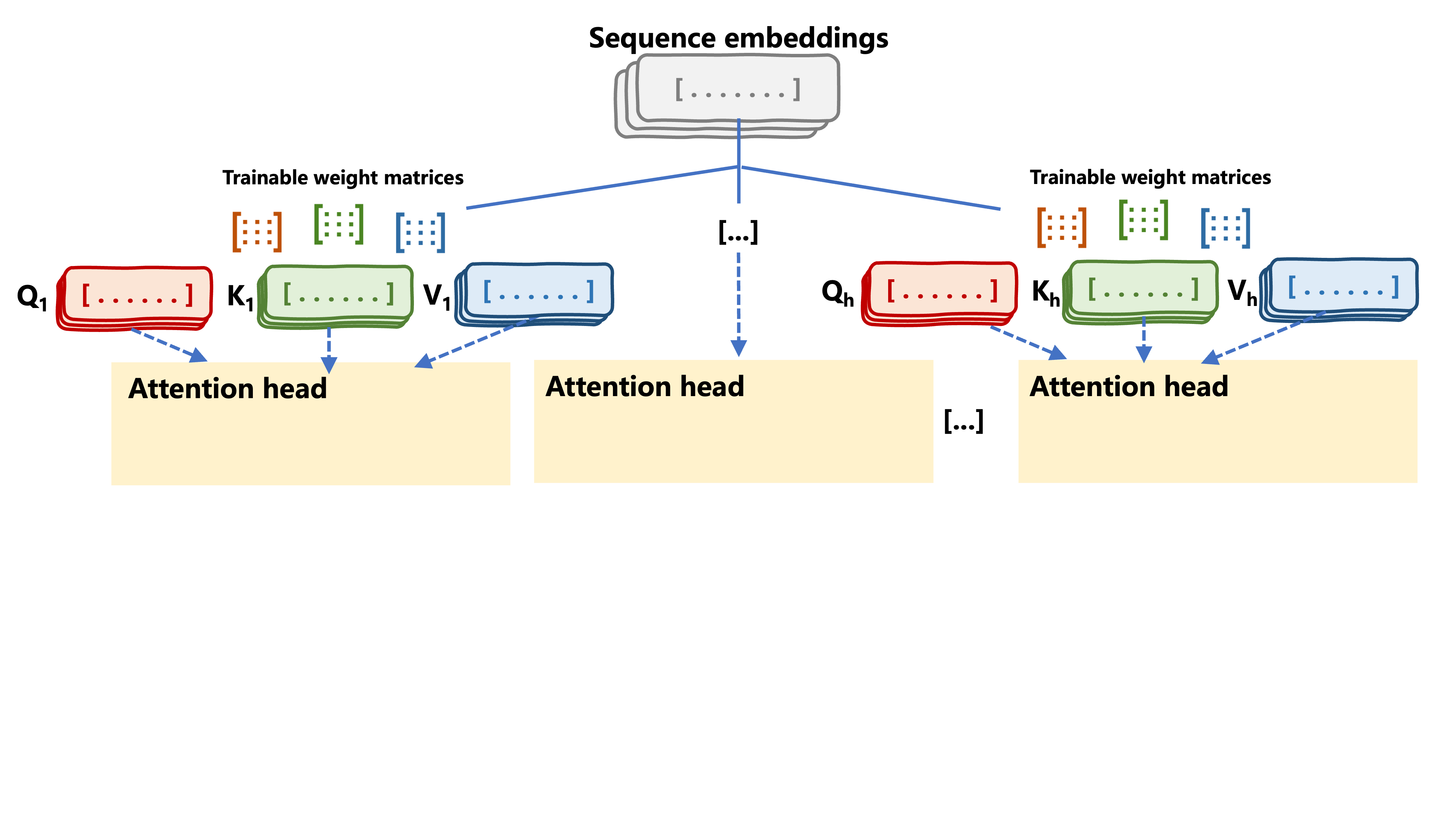
Atensi multi-kepala
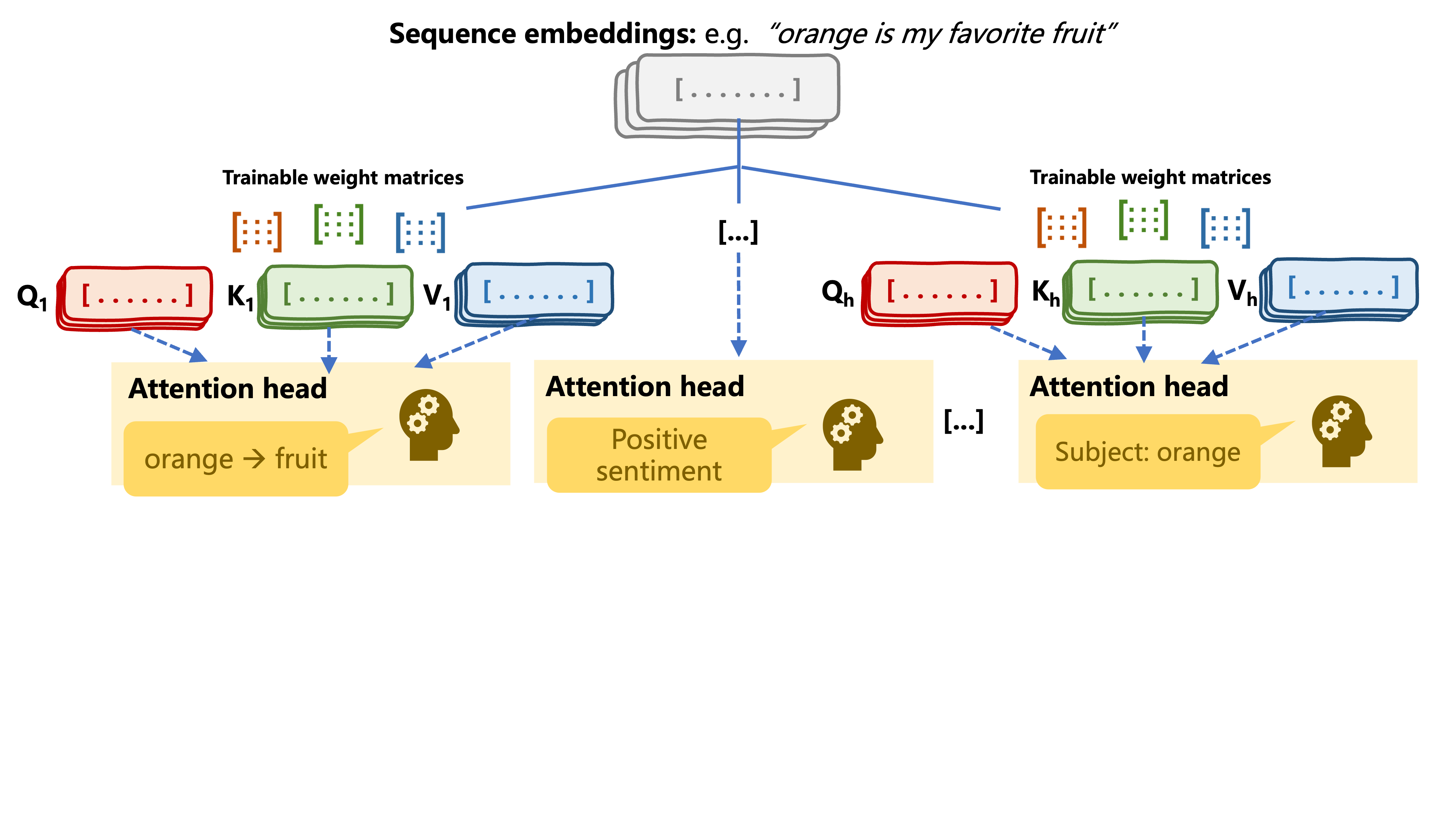
Atensi multi-kepala