Melanjutkan pipeline infer
Pengujian Hipotesis di R

Richie Cotton
Data Evangelist at DataCamp
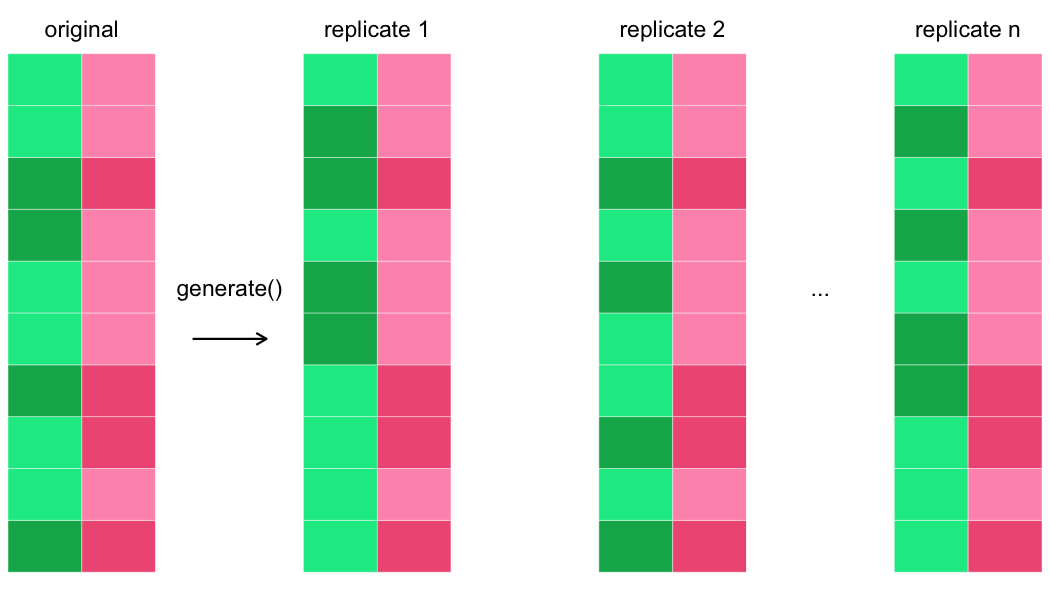
Membuat banyak replikasi
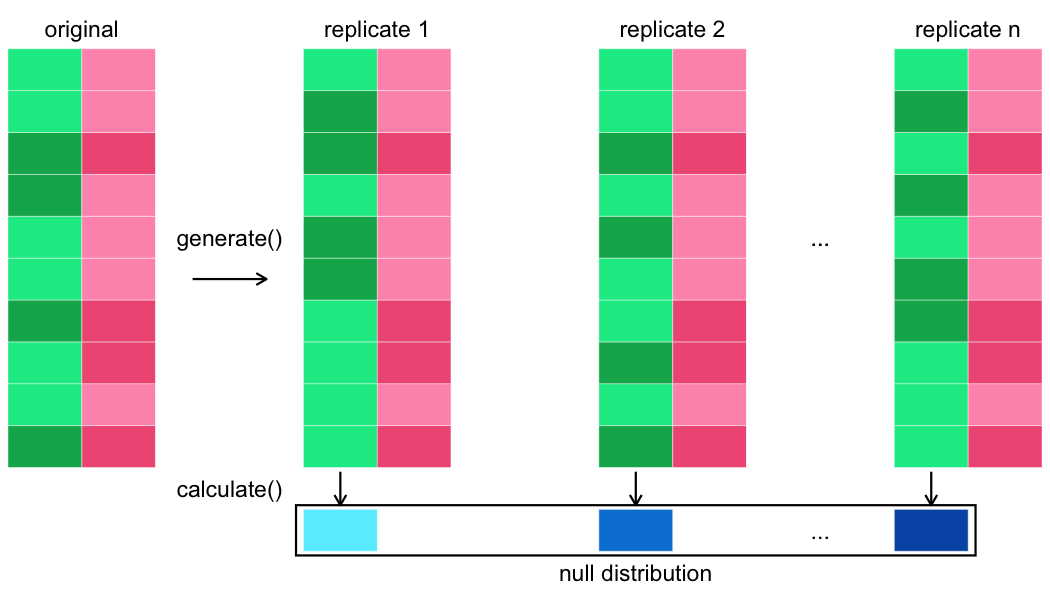
Menghitung statistik uji
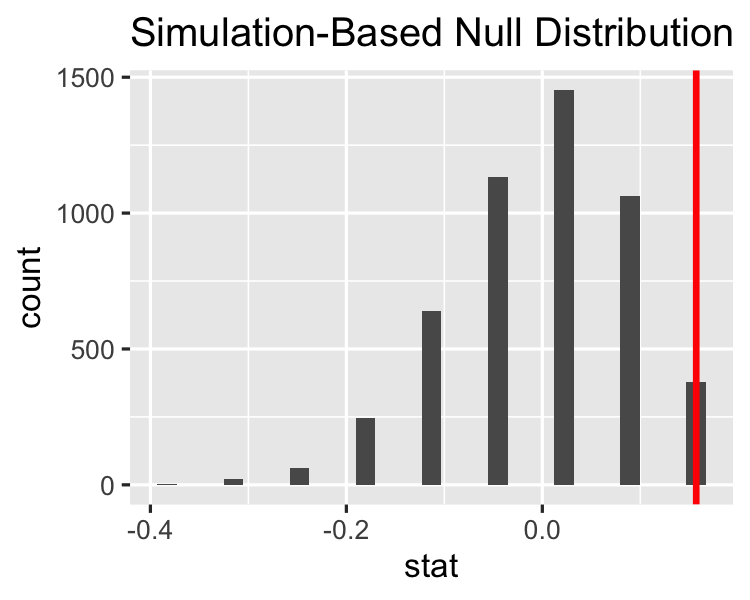
Memvisualisasikan null distribution
visualize(null_distn)
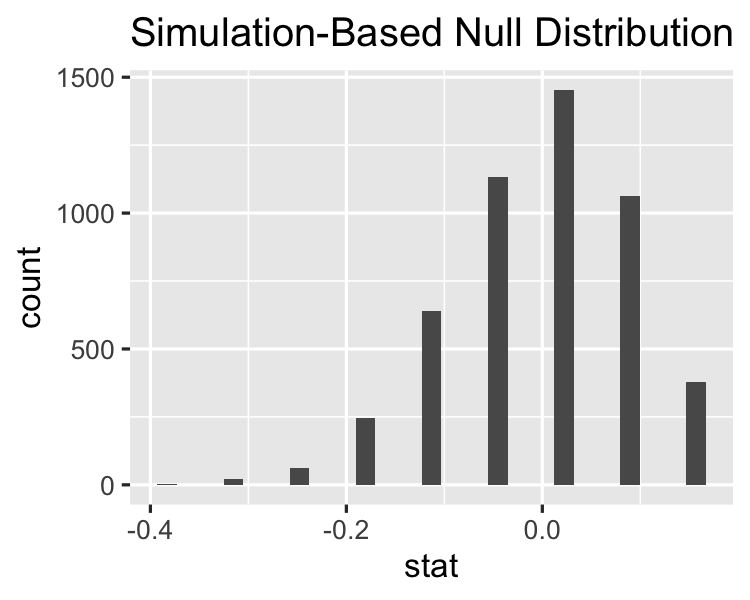
Menghitung statistik uji pada dataset asli
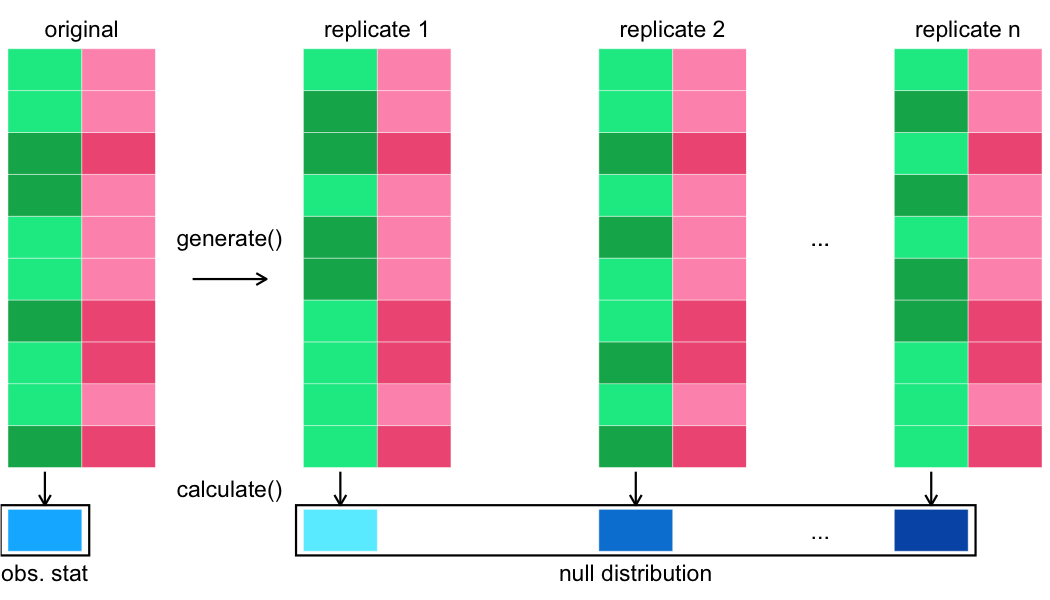
Null distribution vs statistik teramati