Pengantar bootstrap
Sampling di R

Richie Cotton
Data Evangelist at DataCamp
Dengan atau tanpa
Sampling tanpa pengembalian

Sampling dengan pengembalian ("resampling")

Sampling acak sederhana tanpa pengembalian
Populasi

Sampel

Sampling acak sederhana dengan pengembalian
Populasi
Sampel

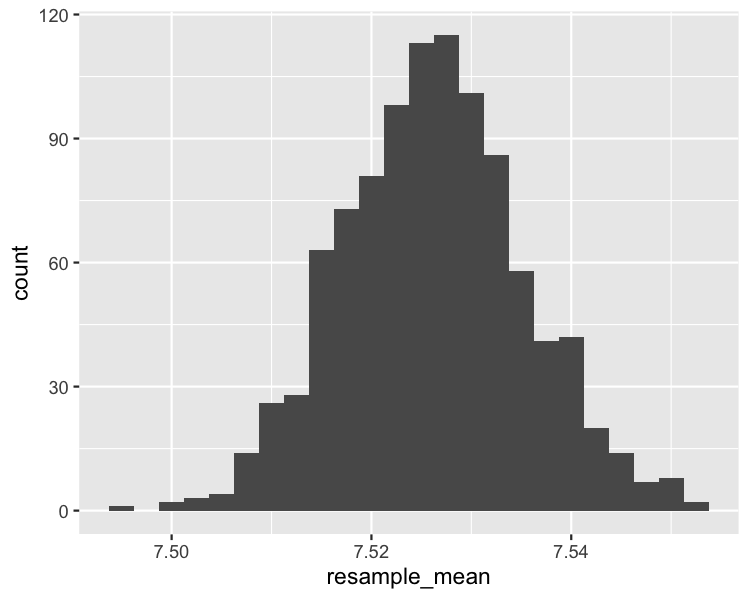
Bootstrapping

Histogram distribusi bootstrap