Organizing complex Dags with Task Groups
Building Data Pipelines with Airflow

Volker Janz
Senior Developer Advocate at Astronomer
The complexity problem
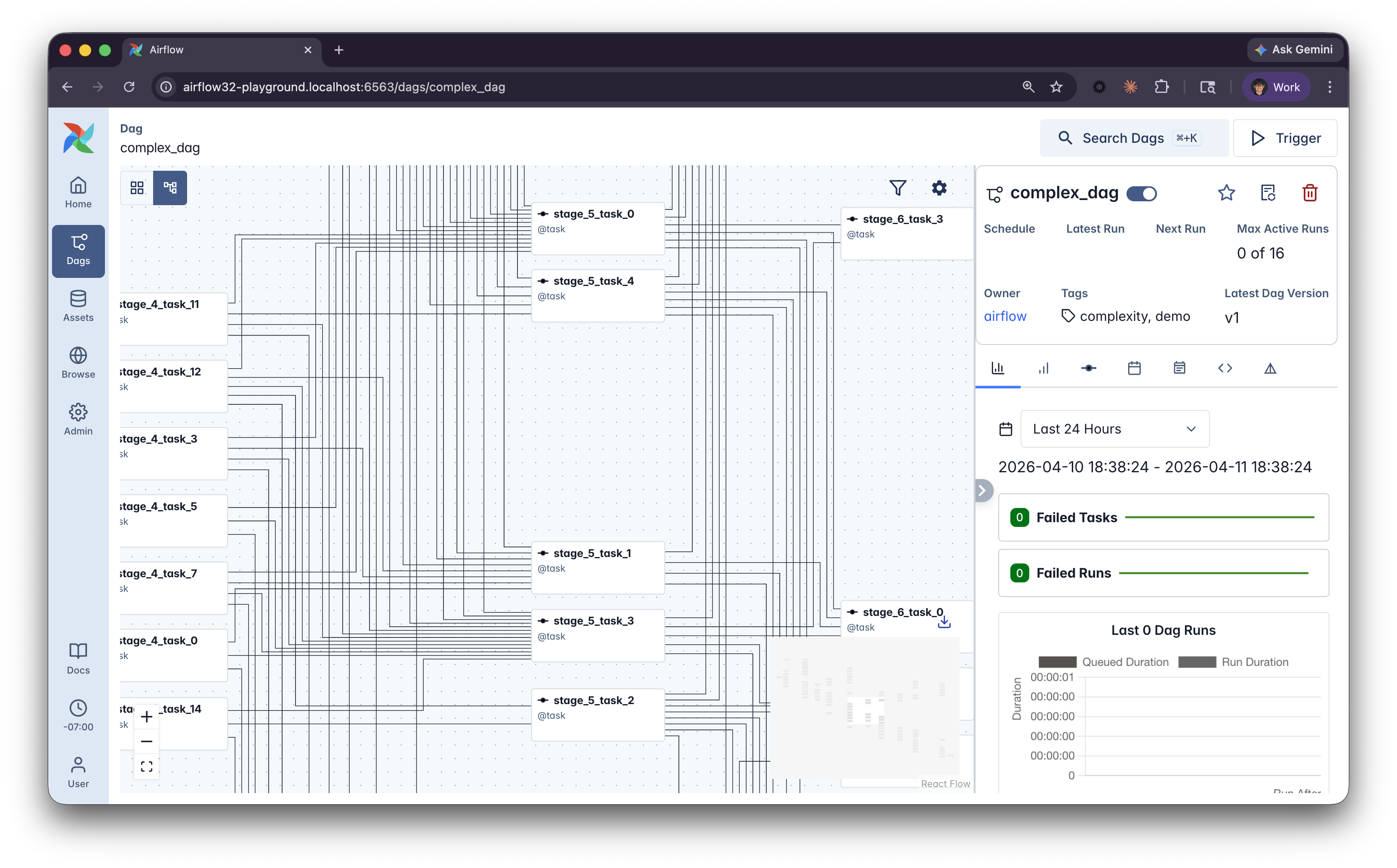
- Large Dags become hard to navigate in the Graph view
- Task names blur together
- New team members struggle to find what they own
How it looks in the Airflow UI
Without task groups
- All tasks at the same level
With task groups
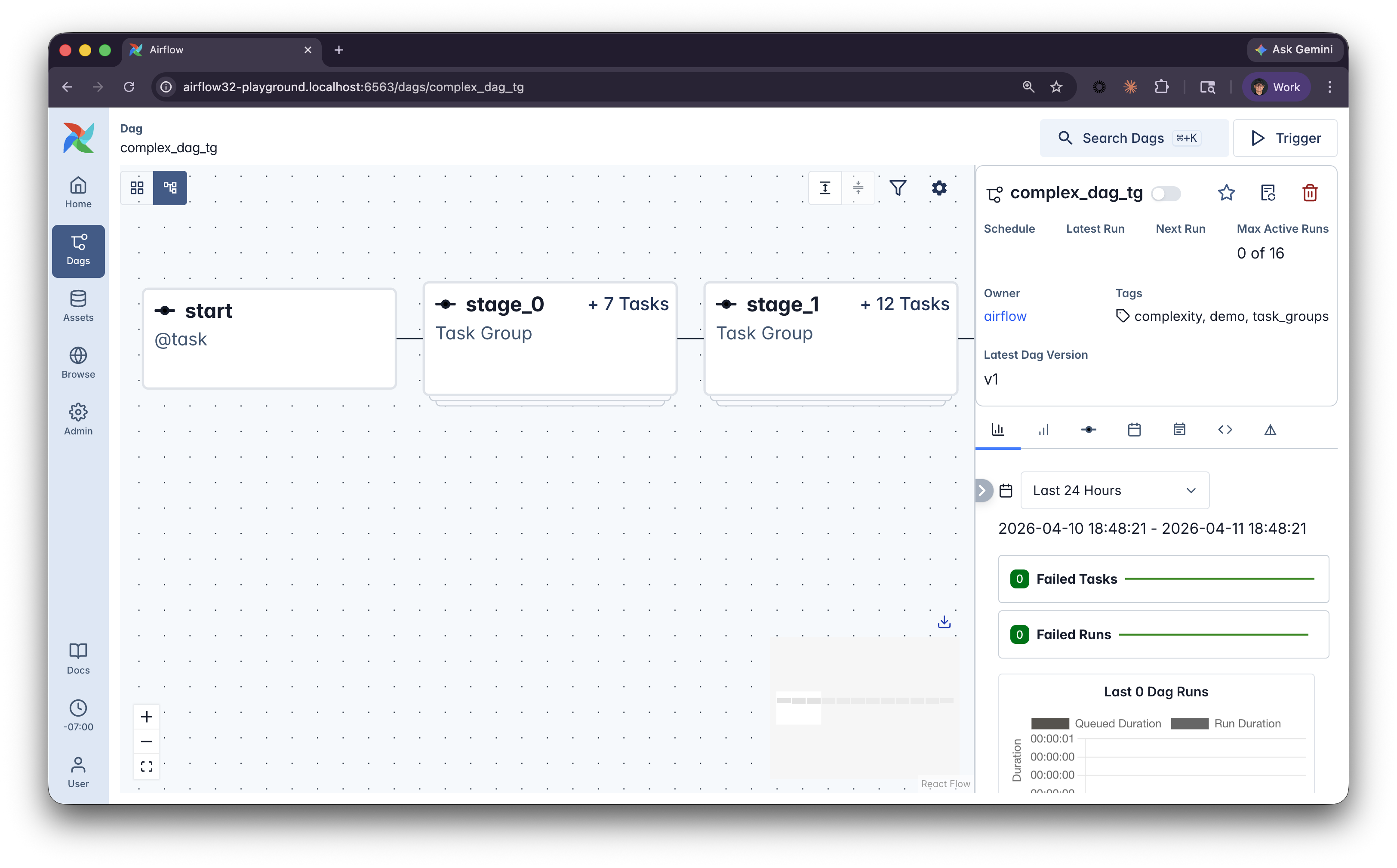
- Collapsible blocks in the UI
Guidelines for grouping
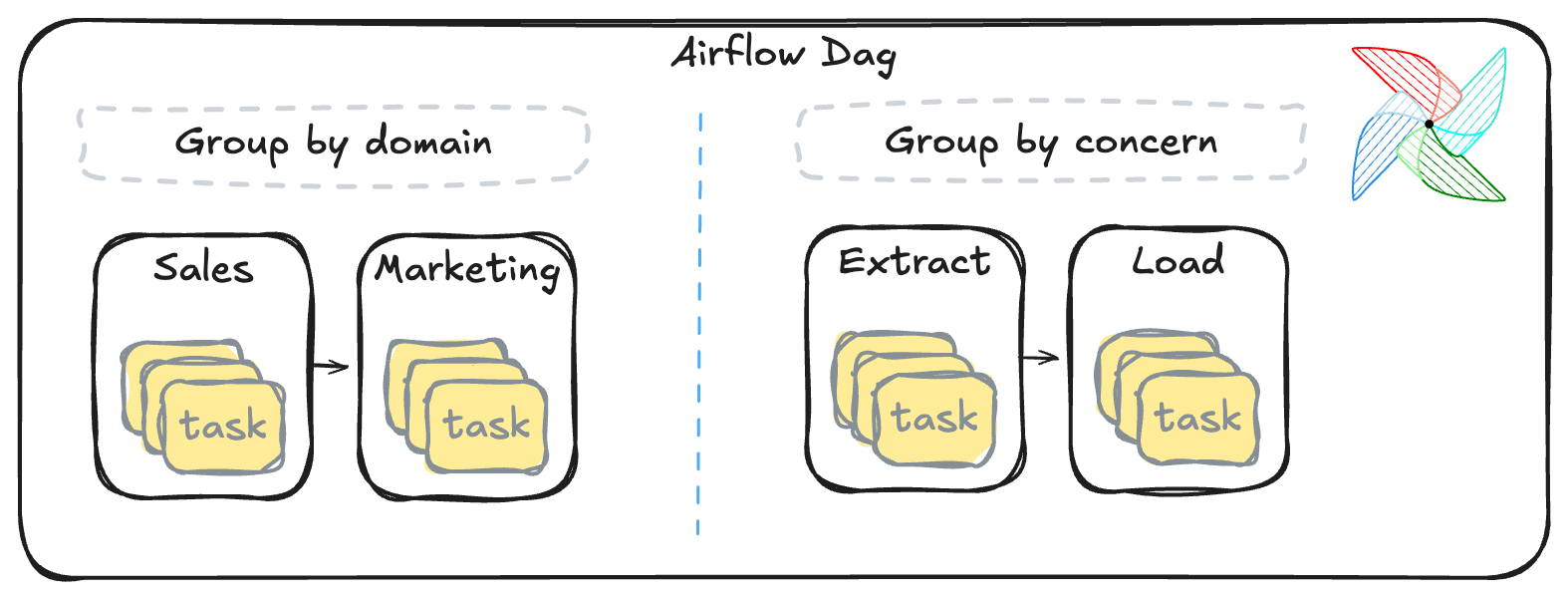
- Group by domain or concern, not by operator type
- Use
group_idfor clear programmatic names,group_display_namefor UI labels - Use
default_argsto share config like retries across all tasks in a group - Apply Miller's Law, more than 7 top-level items can be an indicator that you need a task group

