Dynamic Task Mapping
Building Data Pipelines with Airflow

Volker Janz
Senior Developer Advocate at Astronomer
The problem with hardcoded tasks
@task
def process_file_1():
transform("/data/file_1.csv")
@task
def process_file_2():
transform("/data/file_2.csv")
@task
def process_file_3():
transform("/data/file_3.csv")
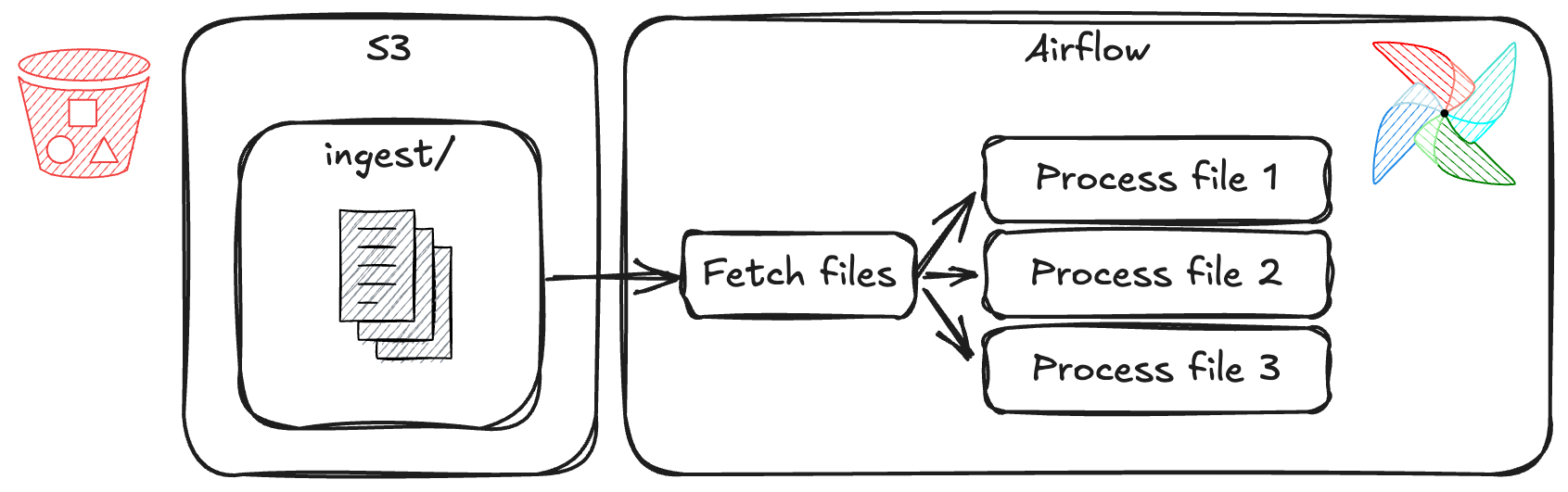
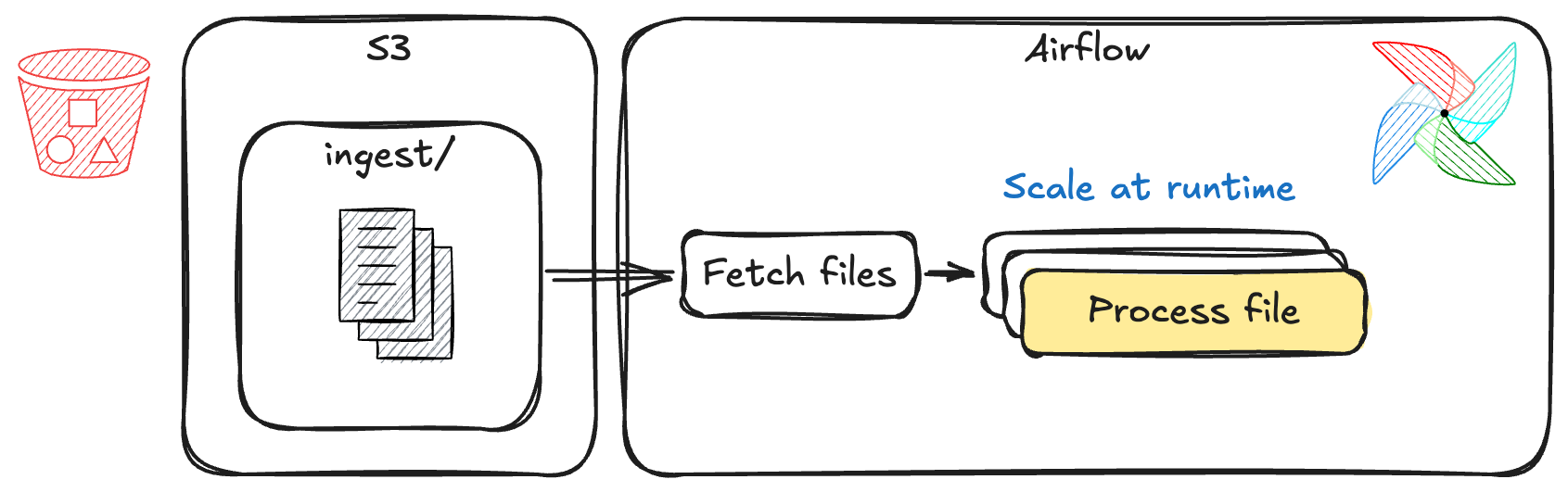
.expand()
@task def fetch_files(): return ["/data/file_1.csv", "/data/file_2.csv", "/data/file_3.csv"]@task(max_active_tis_per_dagrun=2) # control max parallelism def process_file(path: str): print(f"processing file: {path}")files = fetch_files() process_file.expand(path=files)
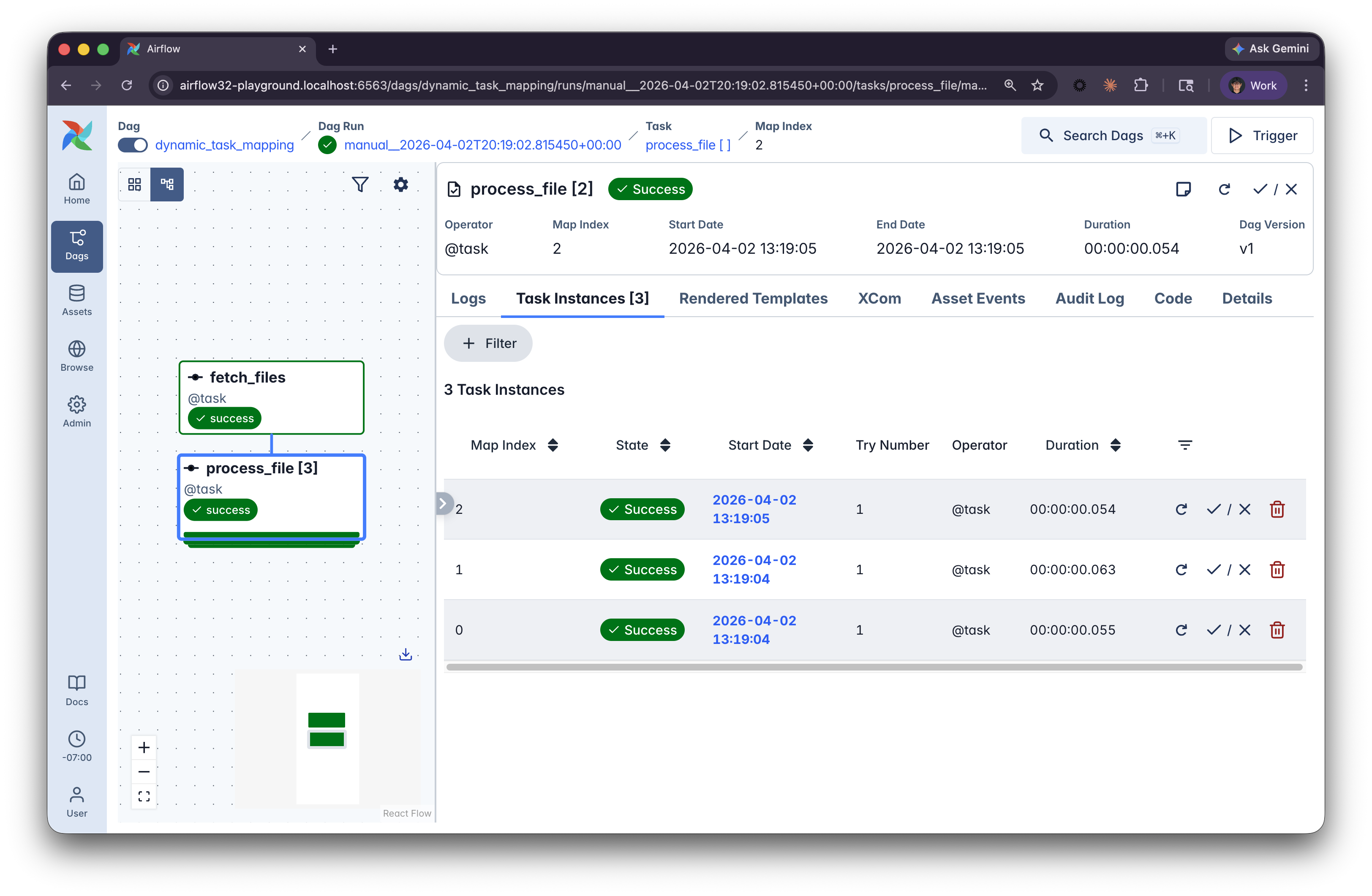
Mapped tasks in the UI
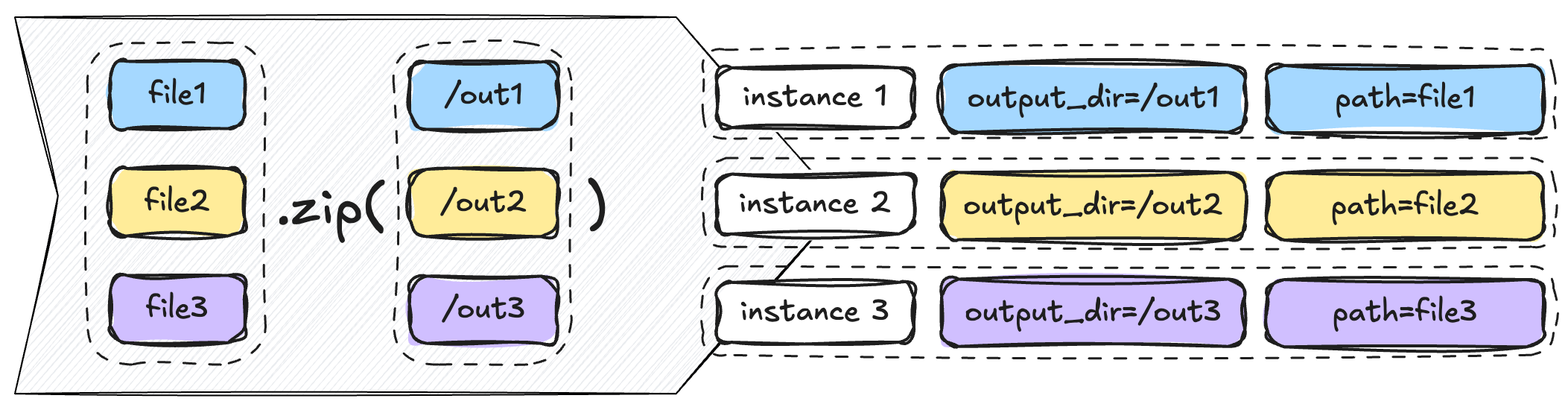
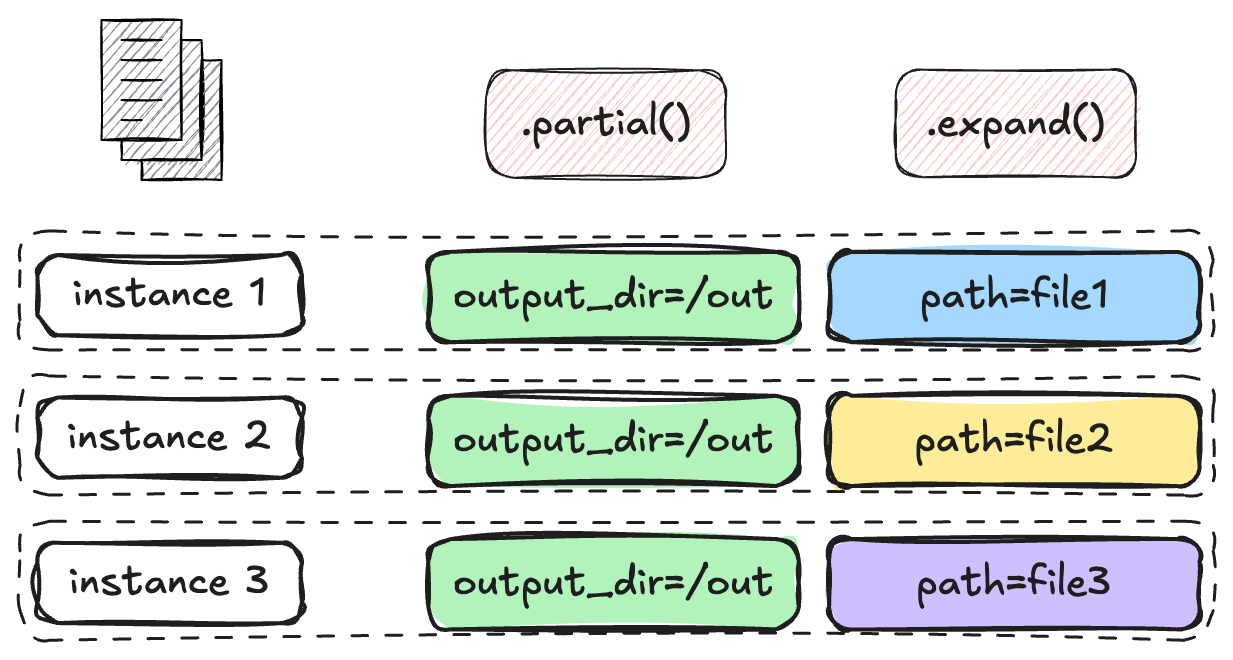
.partial()
@task def process_file(path: str, output_dir: str): transform(path, output_dir)files = get_files() process_file.partial(output_dir="/out").expand(path=files)
The cross-product problem
files = get_files() # ["/data/a.csv", "/data/b.csv", "/data/c.csv"] destinations = get_targets() # ["s3://out/a", "s3://out/b", "s3://out/c"]# Cross product: 3 x 3 = 9 instances (not what we want!) process.expand(path=files, dest=destinations)