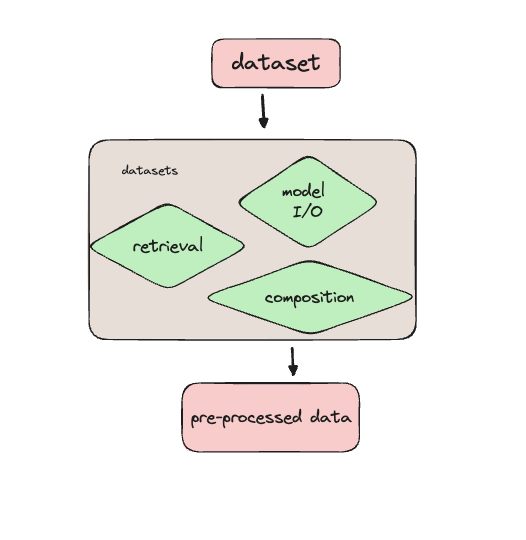
Prapemrosesan data untuk fine-tuning
Fine-Tuning dengan Llama 3

Francesca Donadoni
Curriculum Manager, DataCamp
Menggunakan dataset untuk fine-tuning
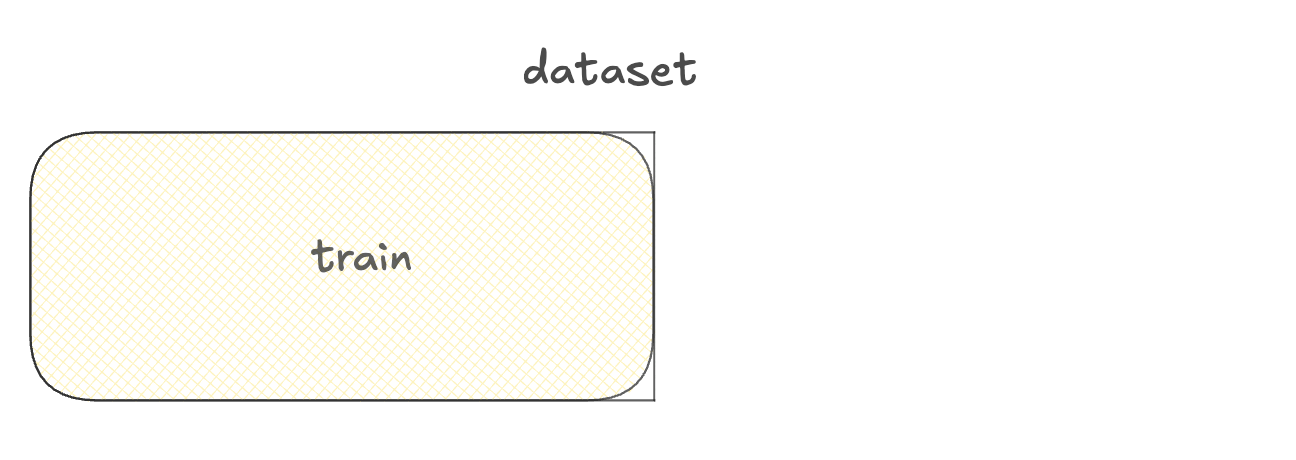
Menggunakan dataset untuk fine-tuning
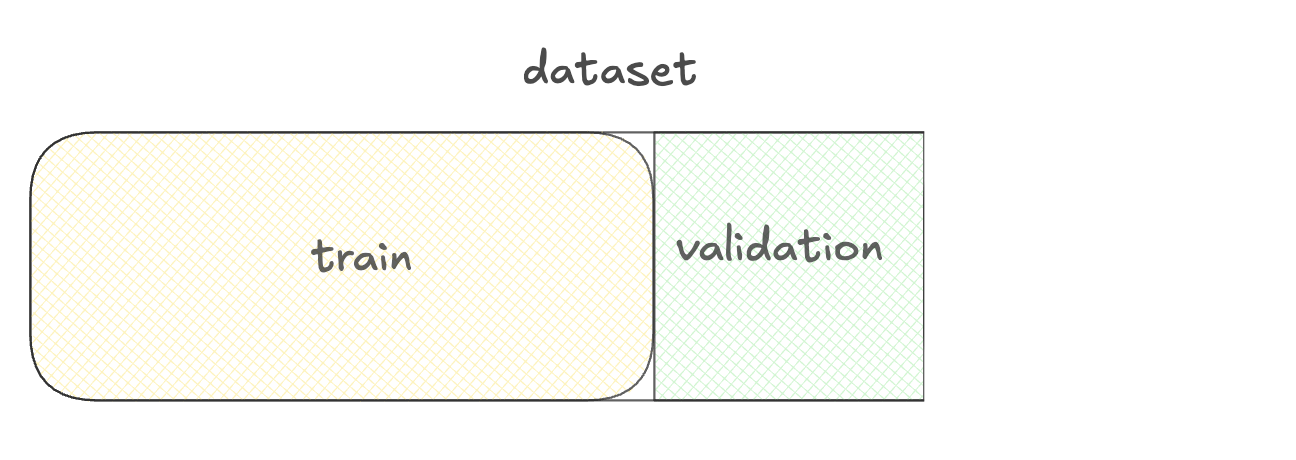
Menggunakan dataset untuk fine-tuning
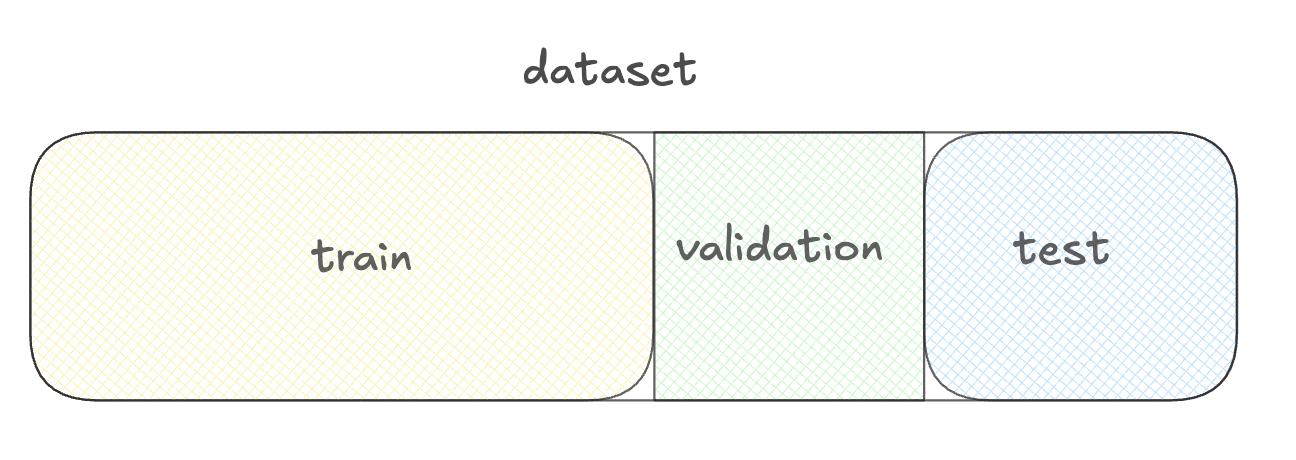
Menyiapkan data dengan pustaka datasets