DQN dengan experience replay
Deep Reinforcement Learning dengan Python

Timothée Carayol
Principal Machine Learning Engineer, Komment
Pengantar experience replay

Double-Ended Queue (Deque)
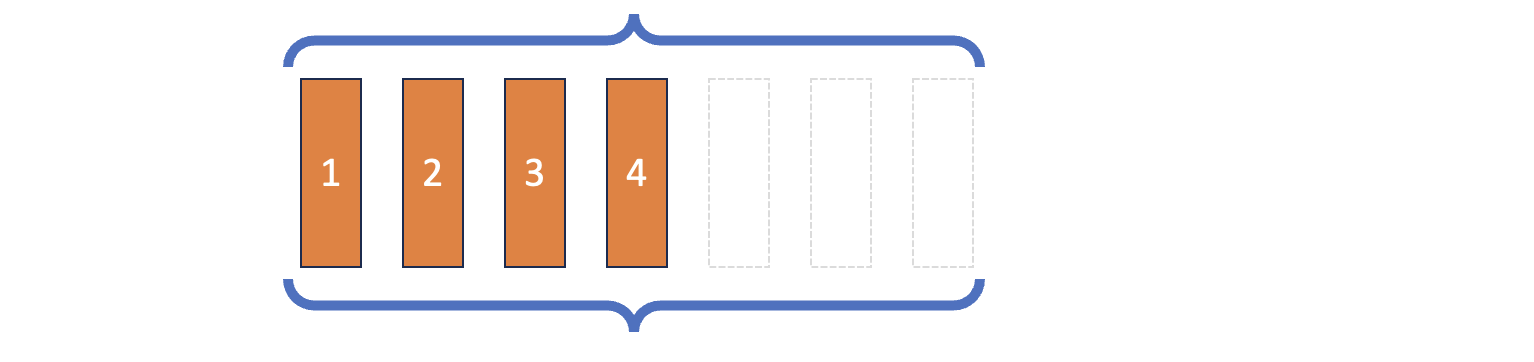
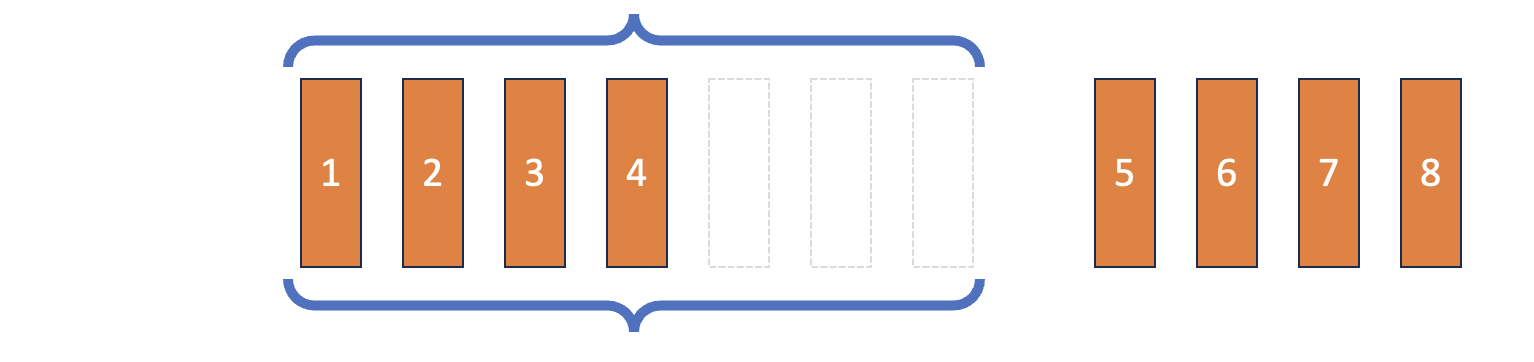
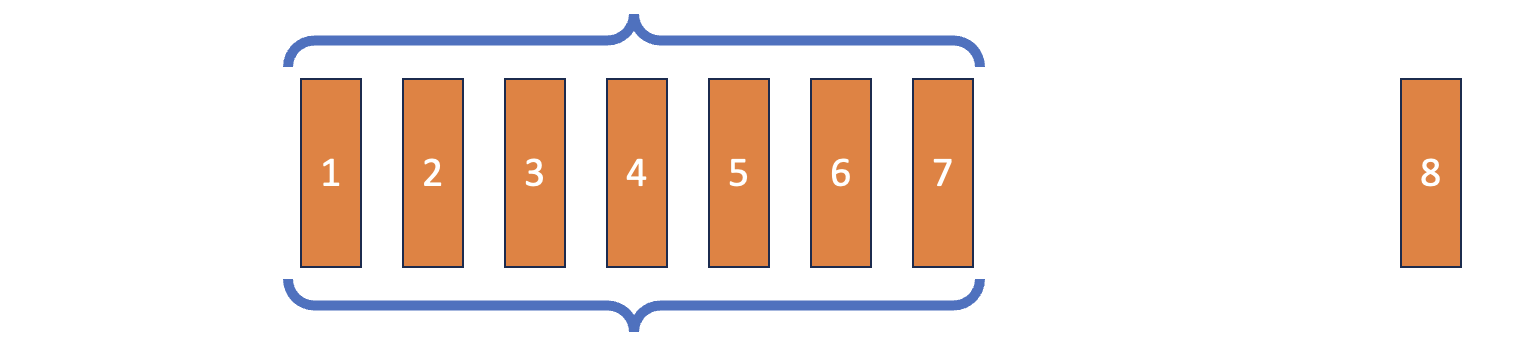
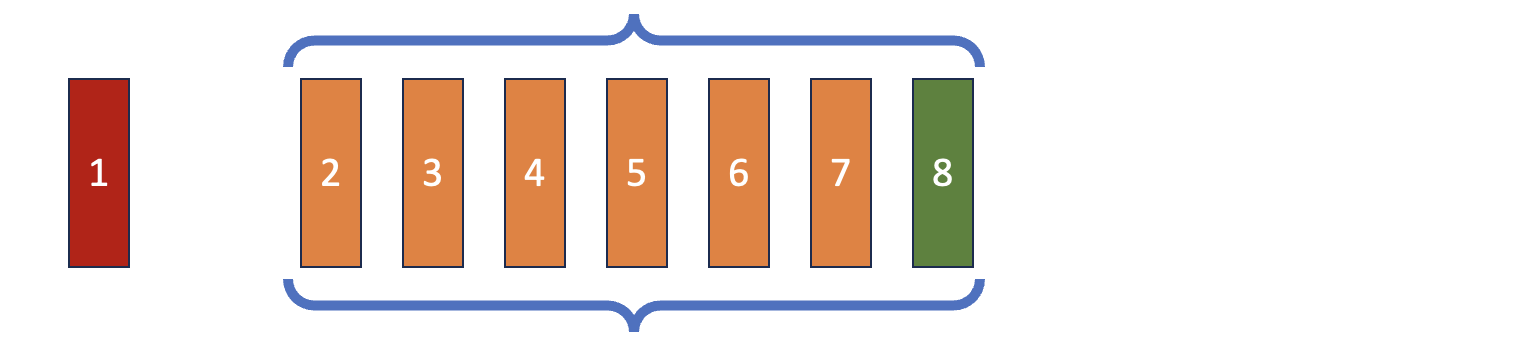
Deep Reinforcement Learning dengan Python
Timothée Carayol
Principal Machine Learning Engineer, Komment

