Algoritme DQN lengkap
Deep Reinforcement Learning dengan Python

Timothée Carayol
Principal Machine Learning Engineer, Komment
Algoritme DQN


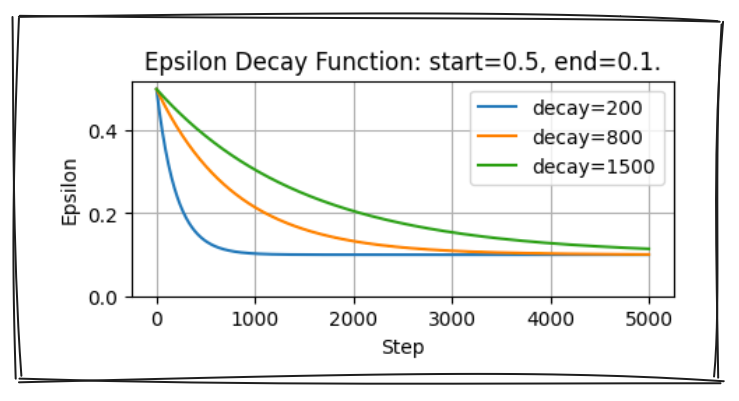
Epsilon-greediness dalam algoritme DQN
- $\varepsilon = end + (start-end) \cdot e^{-\frac{step}{decay}}$
- Ambil aksi acak dengan probabilitas $\varepsilon$
- Ambil aksi bernilai tertinggi dengan probabilitas $1 - \varepsilon$
Fixed Q-targets

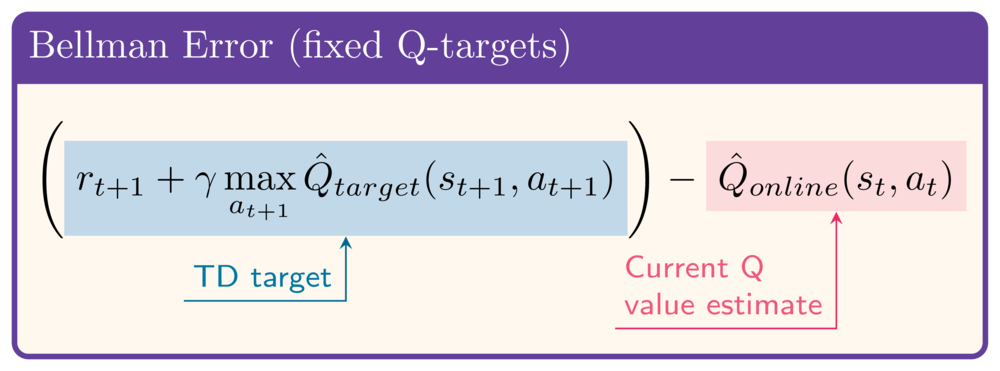
Menerapkan fixed Q-targets
- Awalnya Online Network = Target Network
- State dict suatu network berisi semua bobot:

- Tiap langkah, setiap bobot Target Network makin mendekati Online Network

