Double DQN
Deep Reinforcement Learning dengan Python

Timothée Carayol
Principal Machine Learning Engineer, Komment
Double Q-learning
- Q-learning melebihkan Q-value, menurunkan efisiensi pembelajaran
- Penyebabnya: bias maksimisasi
- Double Q-Learning menghilangkan bias dengan memisahkan pemilihan aksi dan estimasi nilai
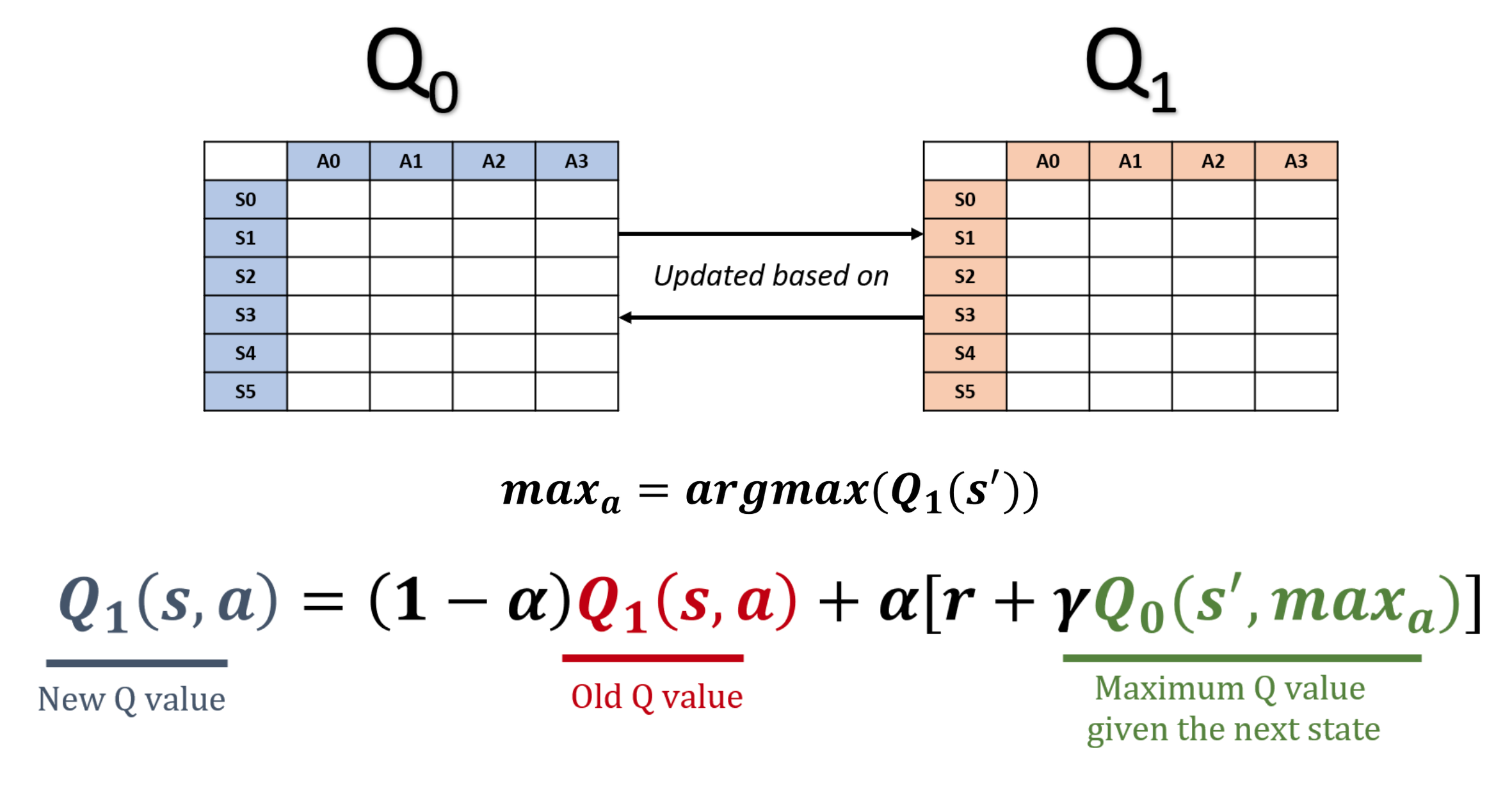
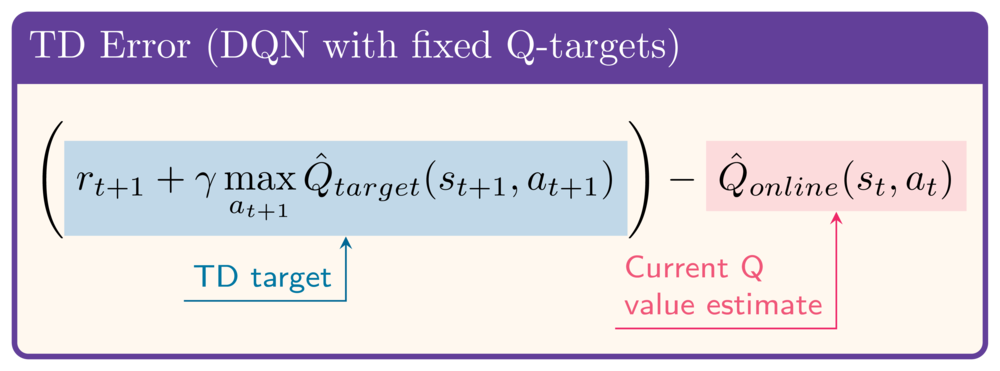
Gagasan di balik DDQN

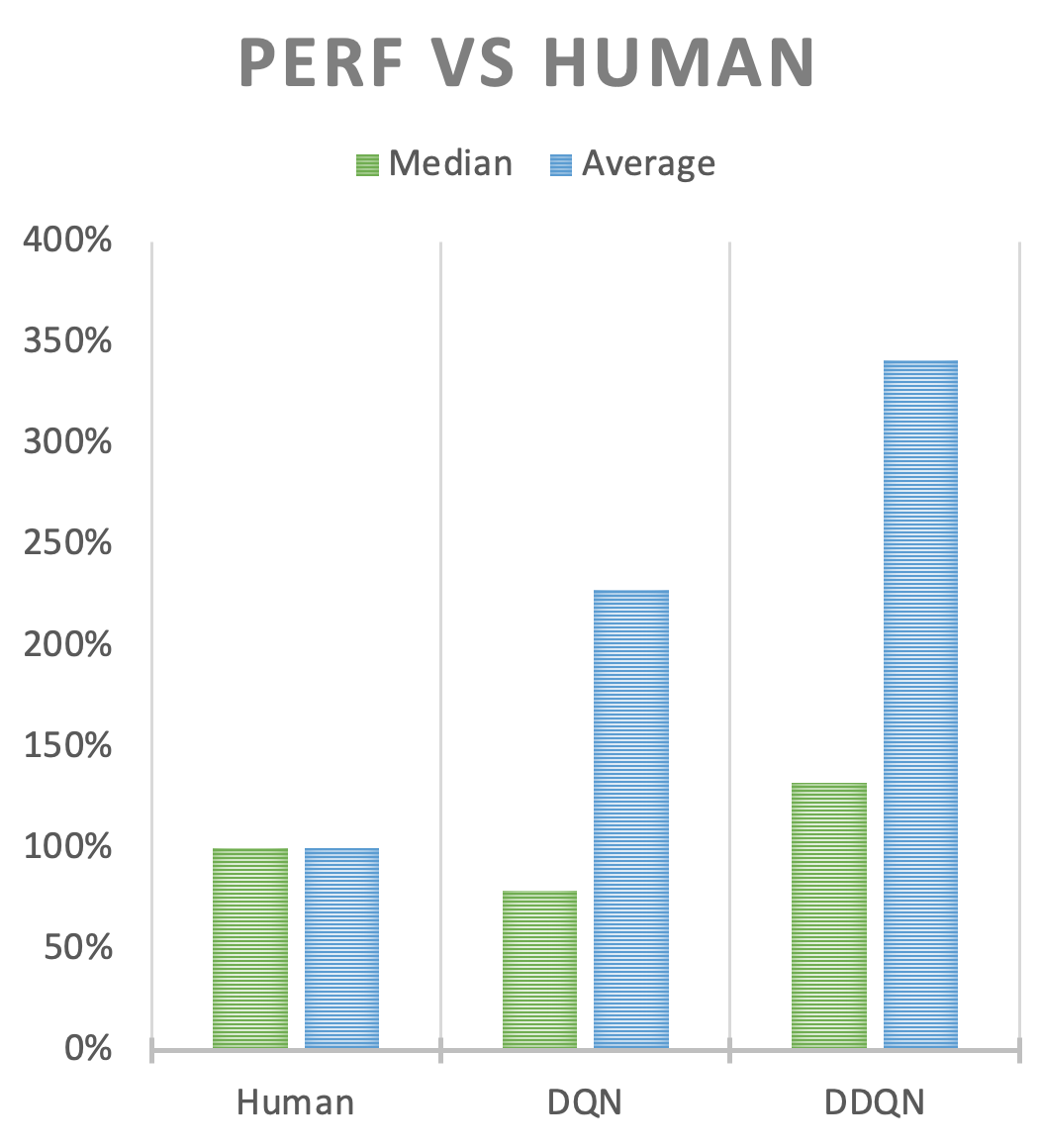
Kinerja DDQN
1 https://arxiv.org/abs/2303.11634

