Advantage Actor Critic
Deep Reinforcement Learning dengan Python

Timothée Carayol
Principal Machine Learning Engineer, Komment
Mengapa actor-critic?
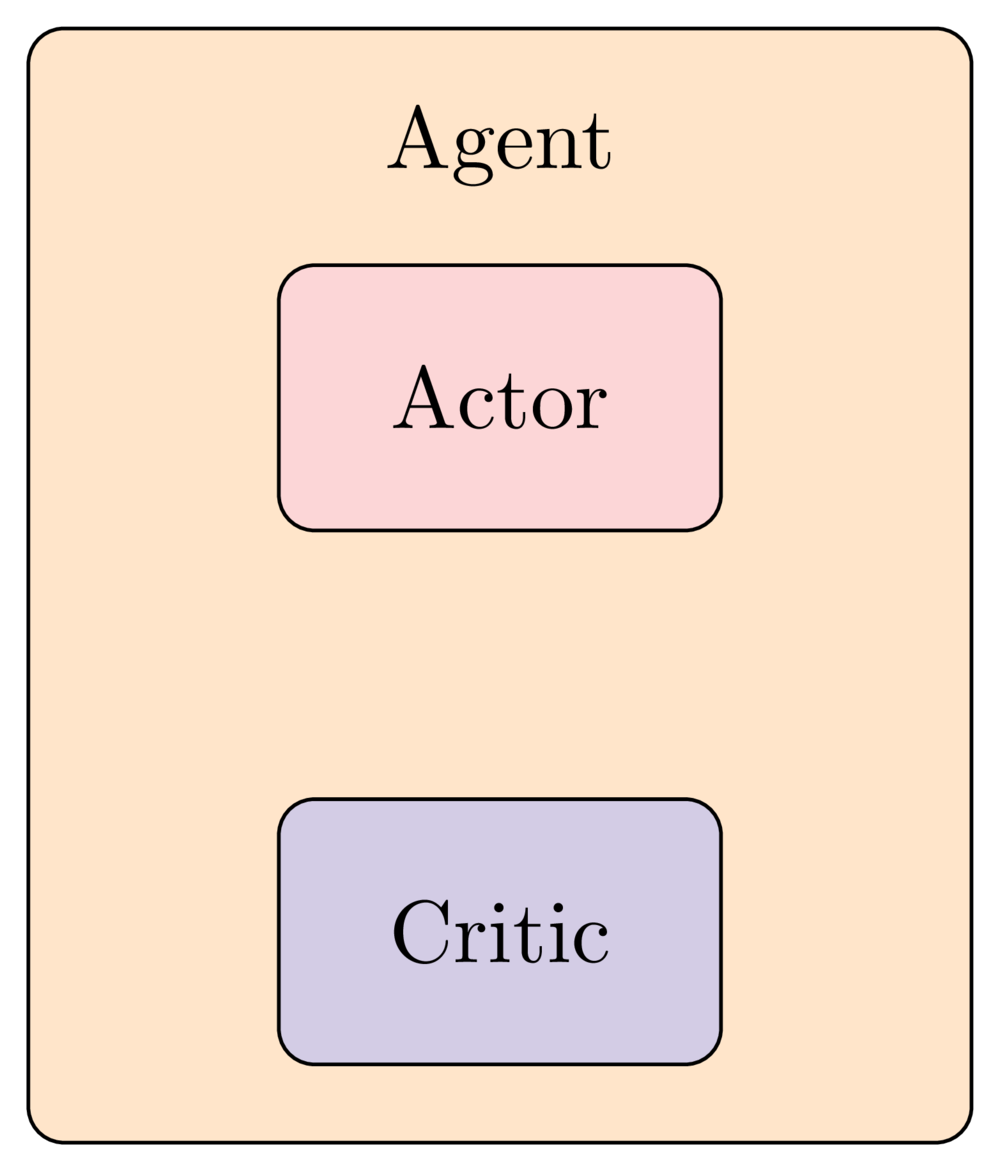
Intuisi di balik metode Actor-Critic

Jaringan Critic
- Critic mengaproksimasi fungsi nilai state
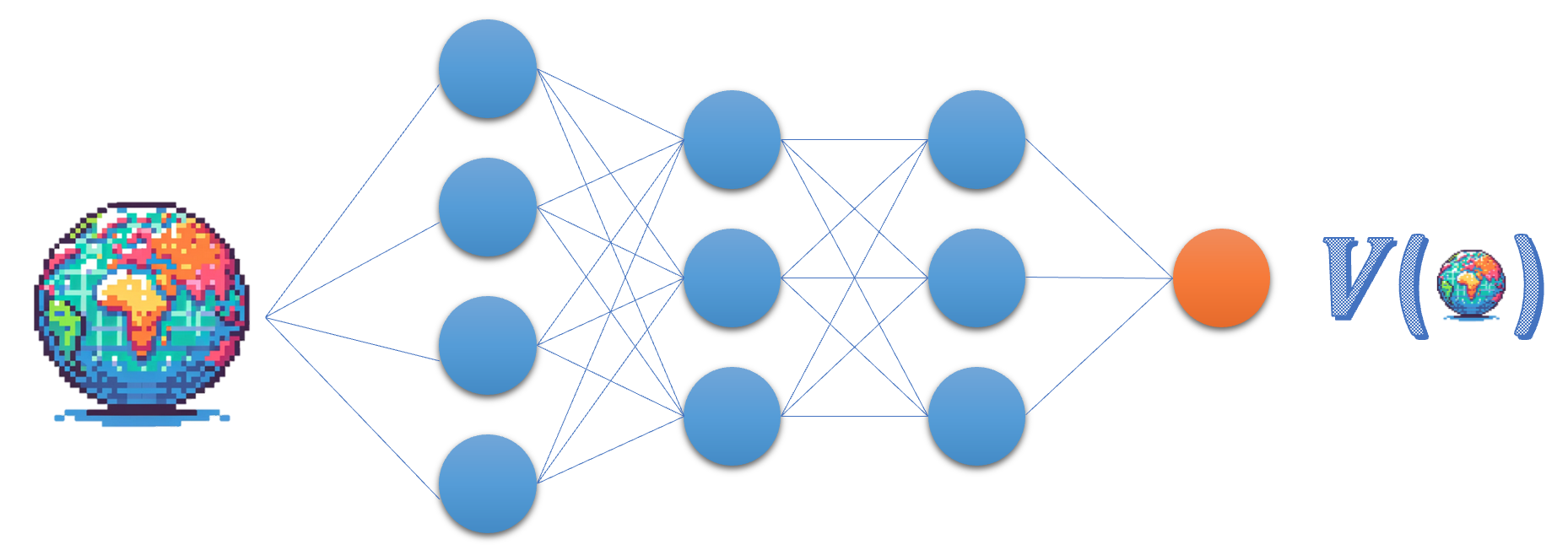
- Menilai aksi $a_t$ berdasarkan advantage atau TD error
Dinamika Actor-Critic
Dinamika Actor-Critic
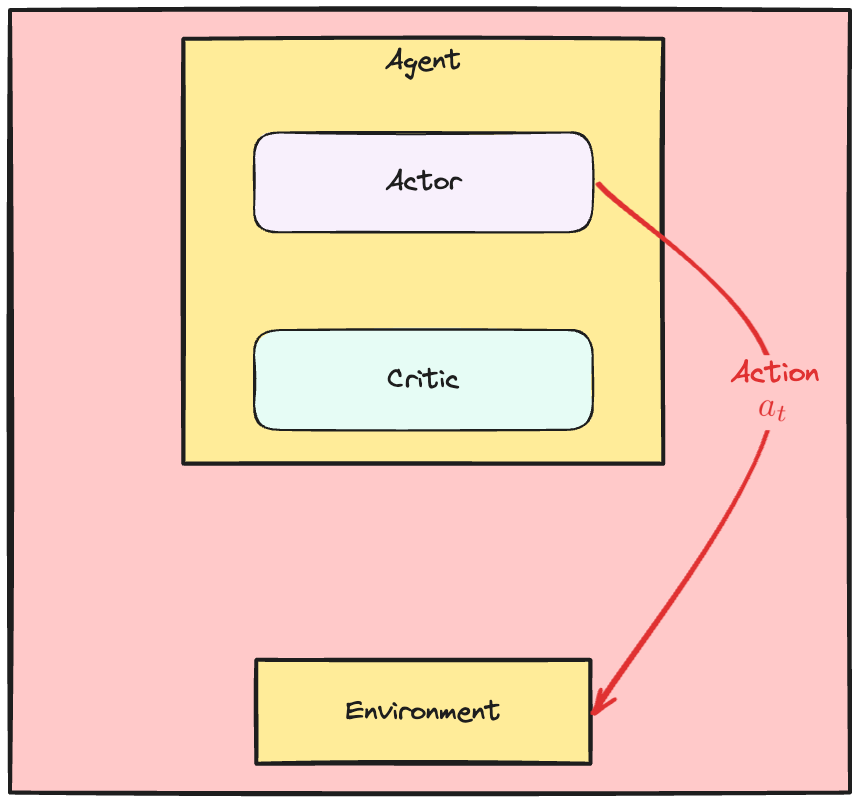
Dinamika Actor-Critic
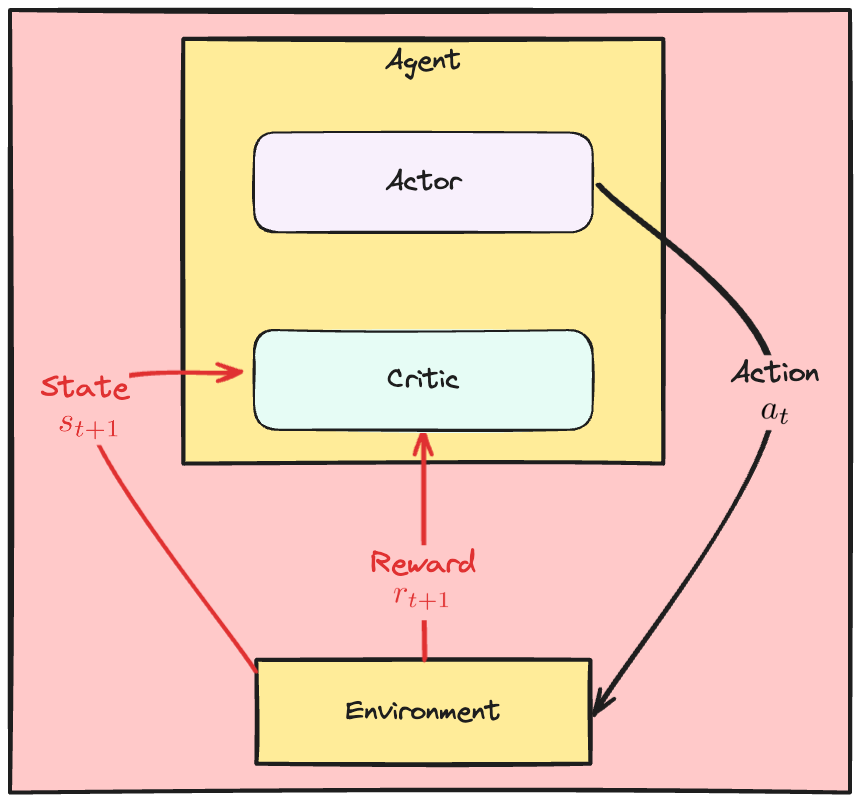
Dinamika Actor-Critic
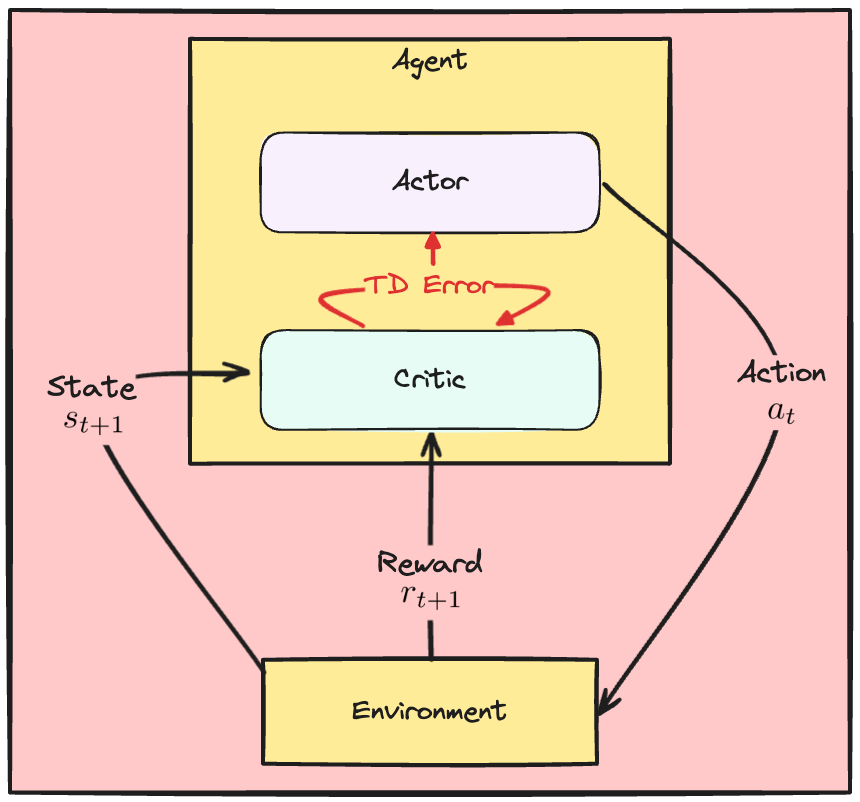
Dinamika Actor-Critic
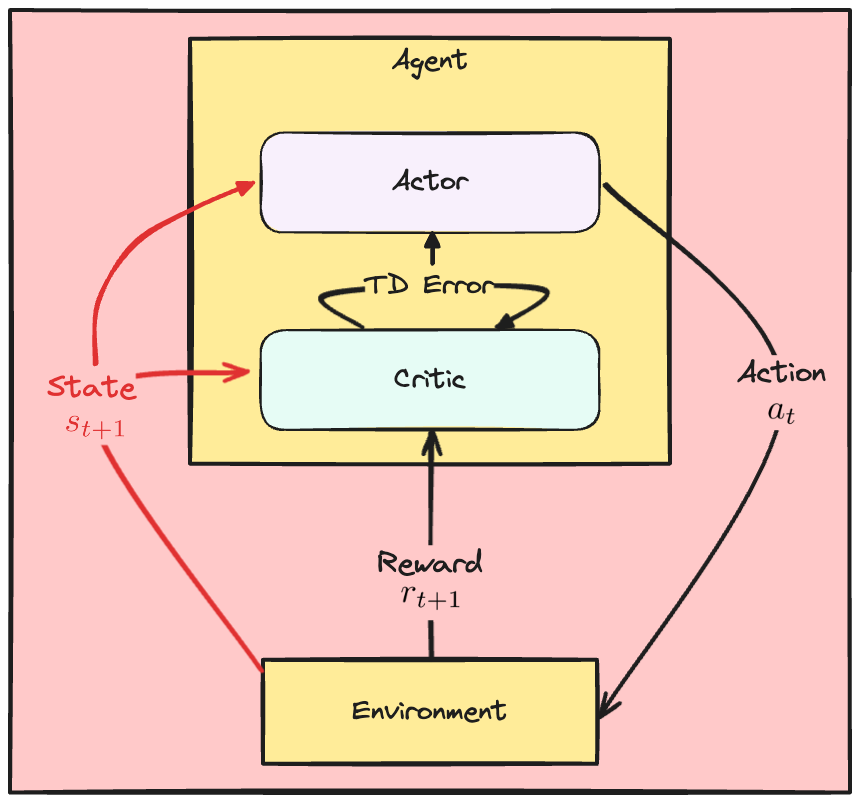
Loss A2C
Critic

- Loss critic: kuadrat TD error
Actor

- TD error mencerminkan penilaian critic
- Naikkan probabilitas aksi dengan TD error positif

