Pengantar policy gradient
Deep Reinforcement Learning dengan Python

Timothée Carayol
Principal Machine Learning Engineer, Komment
Pengantar metode Policy dalam DRL
Q-learning:
- Mempelajari fungsi nilai aksi Q
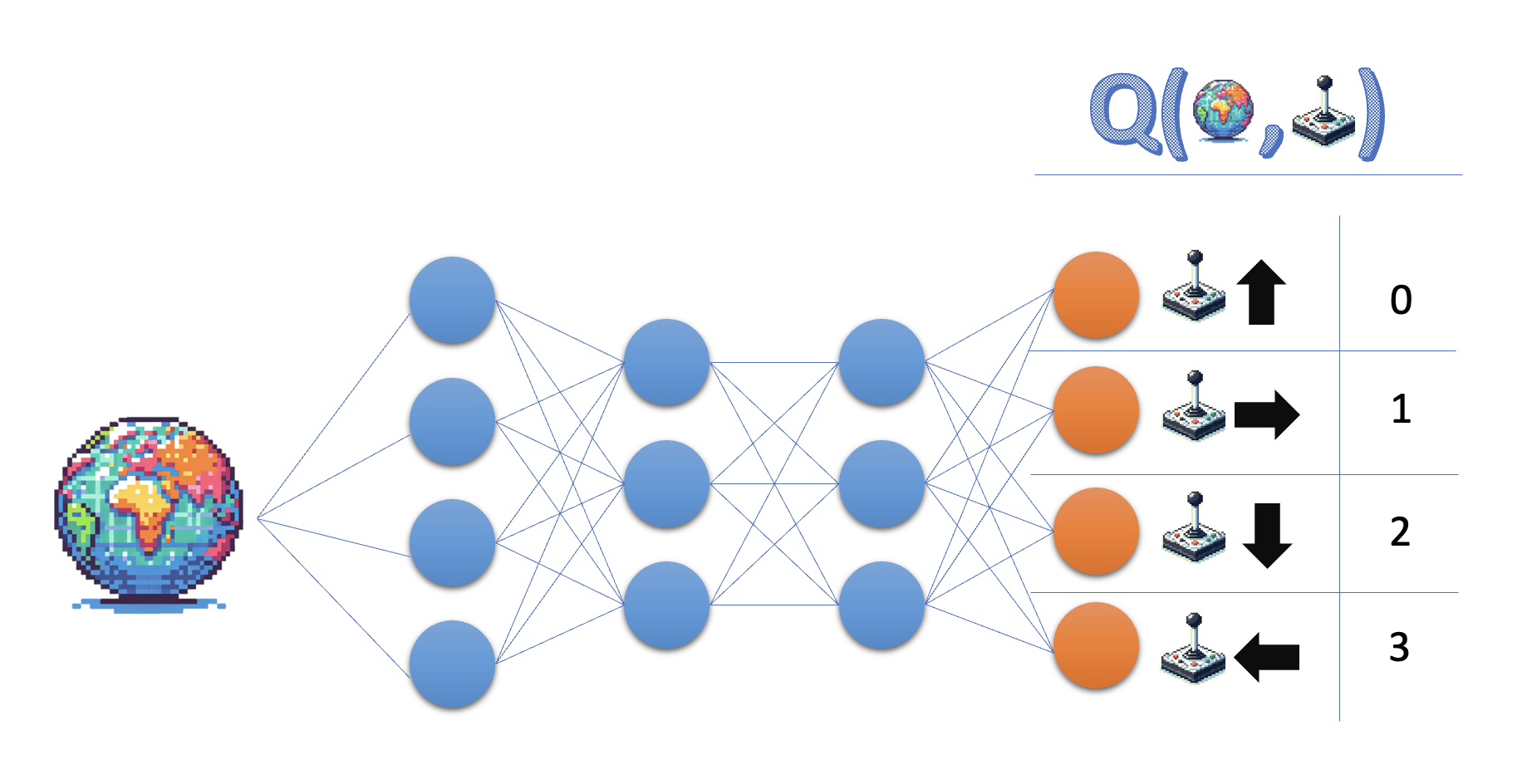
- Policy: pilih aksi dengan nilai tertinggi
Policy learning:
- Mempelajari policy secara langsung
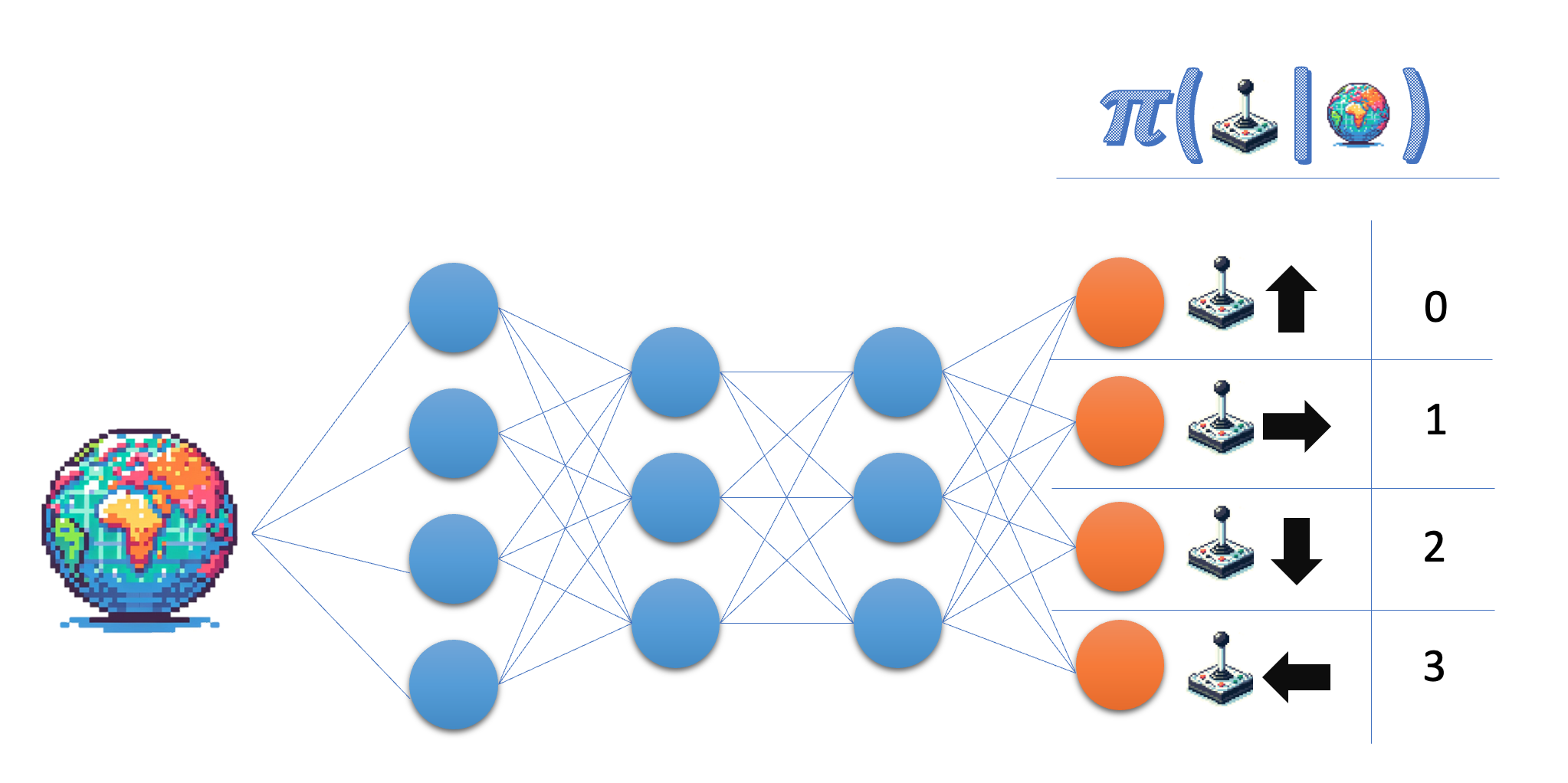
Policy network (aksi diskret)
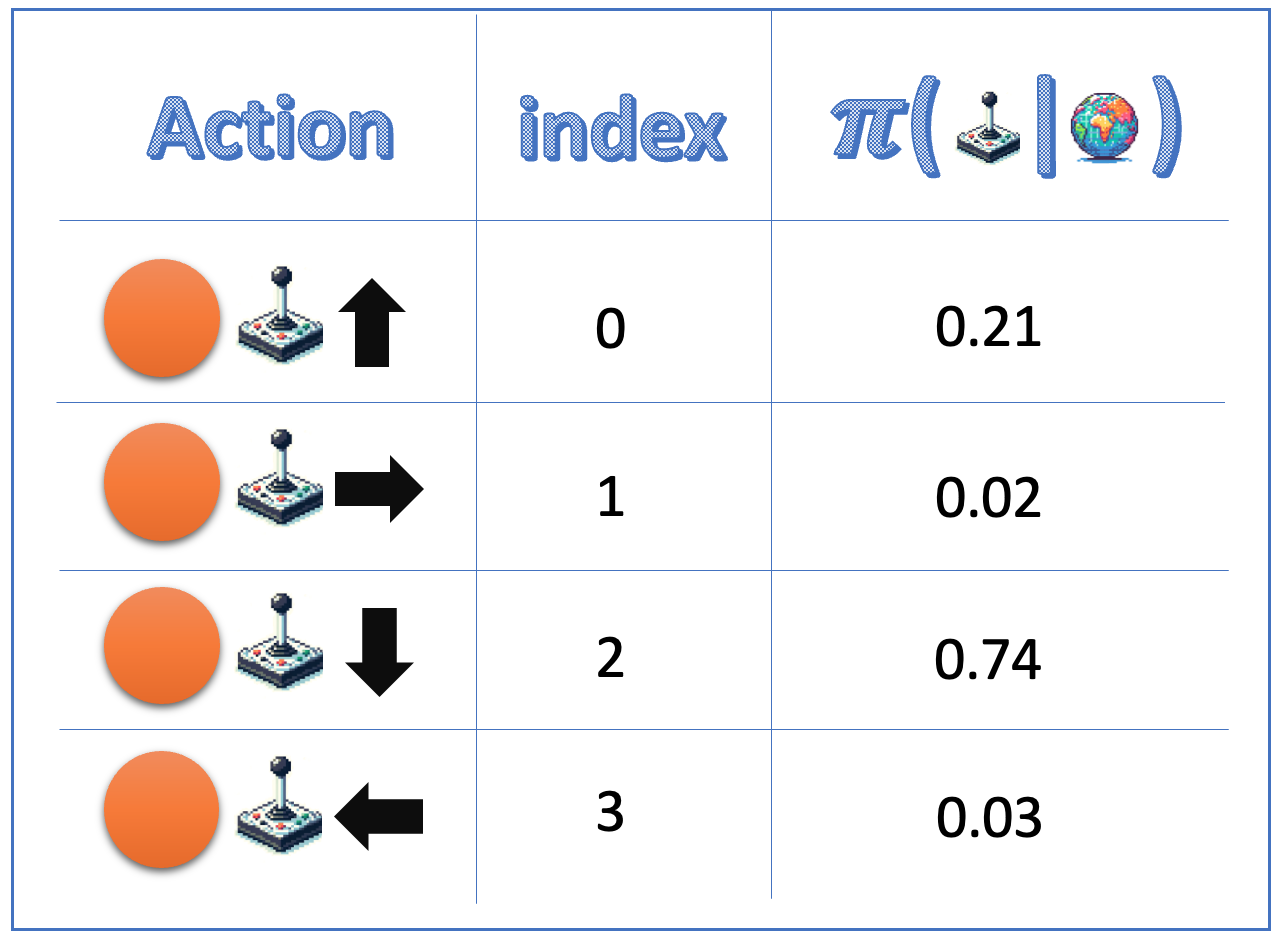
action_dist = ( torch.distributions.Categorical(action_probs))action = action_dist.sample()
Fungsi objektif
Policy harus memaksimalkan expected return
- Dengan asumsi agen mengikuti $\pi_\theta$
- Dengan mengoptimalkan parameter policy $\theta$
Fungsi objektif:

- Untuk memaksimalkan $J$: butuh gradien terhadap $\theta$:
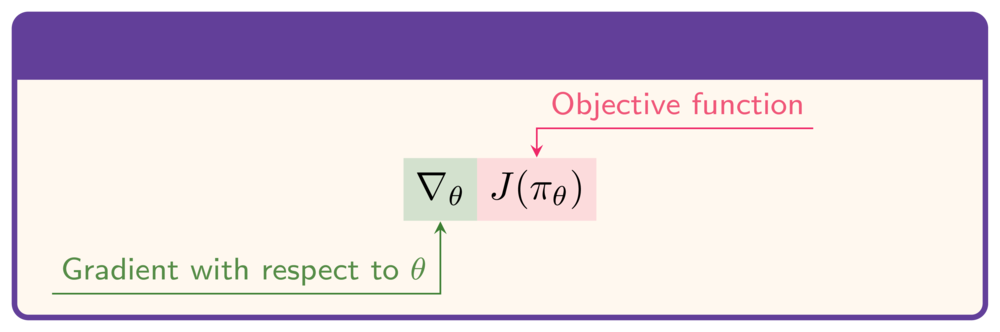
Fungsi objektif
Policy harus memaksimalkan expected return
- Dengan asumsi agen mengikuti $\pi_\theta$
- Dengan mengoptimalkan parameter policy $\theta$
Fungsi objektif:
- Untuk memaksimalkan $J$: butuh gradien terhadap $\theta$:
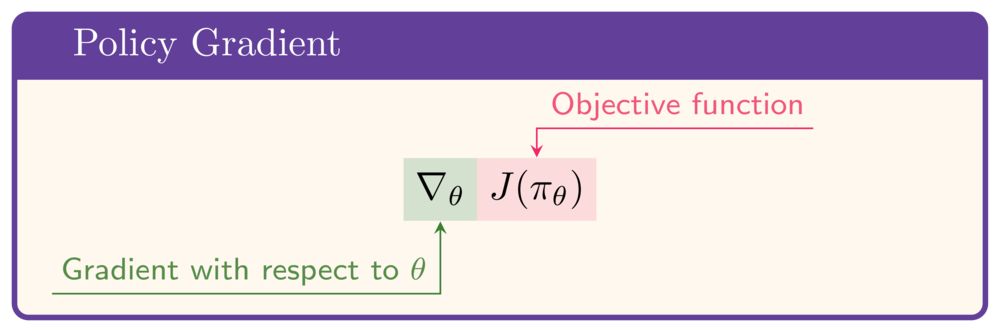
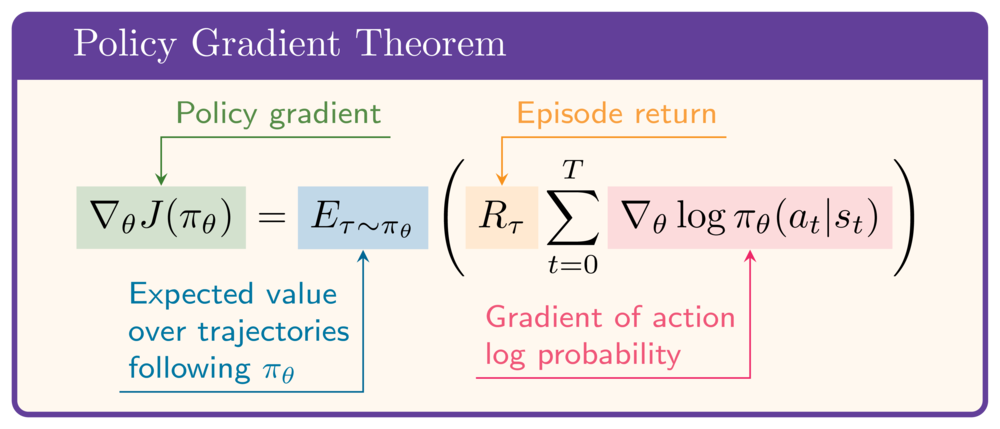
Teorema policy gradient
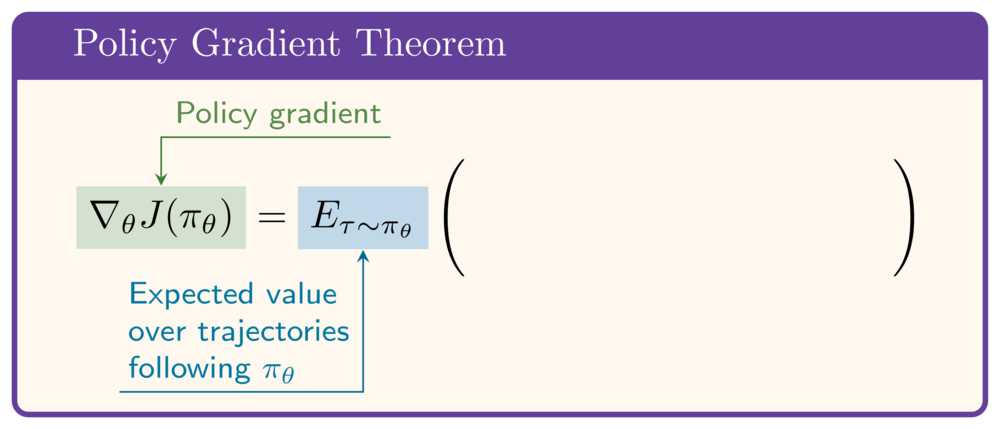
Teorema policy gradient
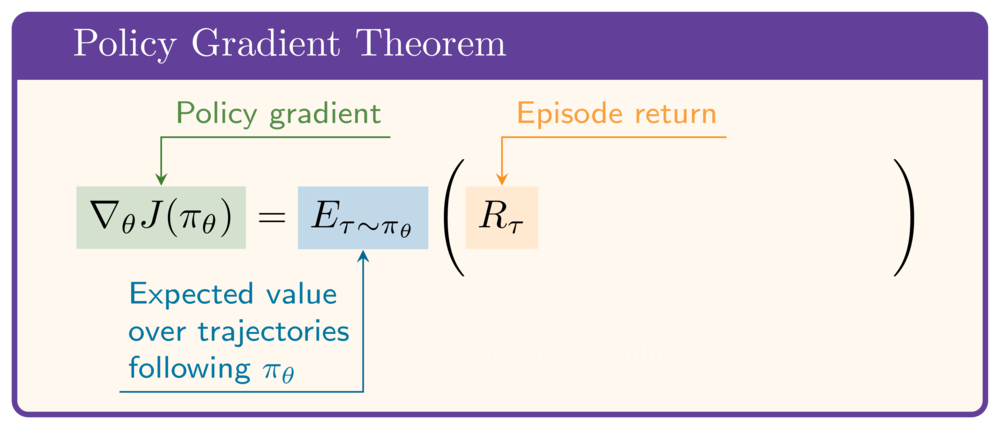
Teorema policy gradient